
1. 자료구조
📖 스택과 큐
- Stack: 선형 자료구조의 일종으로 Last In First Out (LIFO). 즉, 나중에 들어간 원소가 먼저 나온다.
- Queue: 선형 자료구조의 일종으로 First In First Out (FIFO). 즉, 먼저 들어간 놈이 먼저 나온다.
📖 이진 트리
➡️ 루트 노드를 중심으로 두 개의 서브 트리(큰 트리에 속하는 작은 트리)로 나뉘어 진다. 또한 나뉘어진 두 서브 트리도 모두 이진 트리어야 한다.
각 부모 노드에서 파생되는 자식 노드의 개수는 최대 2개까지로 구성된 트리이다.
- 포화 이진 트리(Perfect): 모든 레벨이 꽉 찬 이진 트리를 의미한다.
-
완전 이진 트리(Complete): 부모, 왼쪽 자식, 오른쪽 자식 순으로 채워지는 트리를 말하며, 마지막 레벨을 제외하고 모든 노드가 가득 차 있어야 한다.
-
정 이진 트리(Full): 각 내부 노드가 두 개의 자식 노드는 가지는 트리입니다. (0개 or 2개)
📖 이진 탐색 트리
➡️ 부모 노드를 기준으로 왼쪽의 자식들은 부모 노드보다 작고 오른쪽 자식들은 부모 노드보다 크다는 규칙을 따르는 이진 트리이다.
📖 힙(Heap)
- 최대 힙(max heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- key(부모 노드) >= key(자식 노드)
- 최소 힙(min heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- key(부모 노드) <= key(자식 노드)
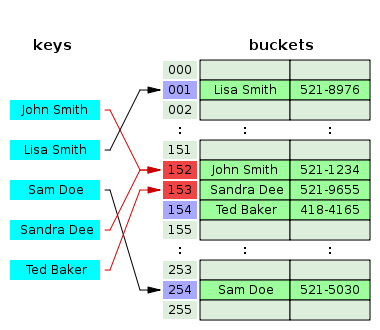
📖 해시 테이블
➡️ 해시 테이블은 효율적인 탐색을 위한 자료구조로 key를 Value에 대응시킨다.

해시 테이블은 충돌(Collision)이 일어날 수 있다.
<해결법>
- Chaining
- 충돌이 일어난 경우 그냥 연결 리스트 뒤에 삽입을 해주면 된다.
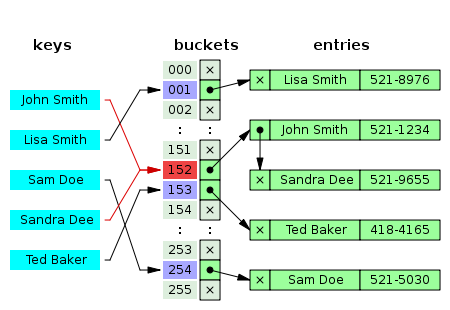
- Open Addressing
- 충돌이 일어날 경우 다른 빈공간의 주소를 이용할 수 있게 한다.
📖 LinkedList와 Array
➡️ Array 는 삽입, 삭제가 O(n)의 시간 복잡도를 가지지만 LinkedList는 O(1)를 가진다.(정확히는 상황에 따라 다르다)
- 맨 끝 값을 알고 있다면 O(1), 모르면 O(N), 중간에 삽입도 마찬가지로 O(n), 처음에 삽입은 O(1)
반면 특정 요소에 접근할 때에는 Array는 O(1), LinkedList는 O(n)의 시간 복잡도를 가진다.
Array는 인덱스로 접근이 가능하지만 LinkedList는 Search를 해야 된다.
2. 알고리즘 (손 코딩 필수 ✏️)
📖 퀵 소트
➡️ 분할 정복의 방식으로 정렬을 수행한다. (불안정 정렬)
하나의 리스트를 피벗(pivot)을 기준으로 두 개의 비균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다. (분할 정복)
#include <iostream>
using namespace std;
//퀵정렬
int n,cnt, quick[10000001];
void quickSort(int i, int j)
{
if(i>=j) return;
int pivot = quick[(i+j)/2];
int left = i;
int right = j;
while(left<=right)
{
while(quick[left]<pivot) left++;
while(quick[right]>pivot) right--;
if(left<=right)
{
swap(quick[left],quick[right]);
left++; right--;
}
}
quickSort(i,right);
quickSort(left,j);
}시간복잡도: O(nlogn)
최악: O(n^2) - 이미 정렬된 리스트에 대해 퀵 정렬 실행하는 경우
✅ 최악의 상황을 개선하기 위해서는 피벗을 배열을 중간 값으로 설정하는 것이 좋다.
📖 머지 소트
➡️ 안정 정렬에 속하고 퀵소트와 마찬가지로 분할 정복 알고리즘 중 하나이다.
시간복잡도: O(nlogn)
📖 힙 소트
➡️ 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법이다. 내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 된다.
시간복잡도: O(nlogn)
📖 버블 소트
➡️ 서로 인접한 두 원소를 비교해서 정렬하는 알고리즘
function bubble_sort(list, n){
let i, j, temp;
for(i=n-1; i>0; i--){
// 0 ~ (i-1)까지 반복
for(j=0; j<i; j++){
// j번째와 j+1번째의 요소가 크기 순이 아니면 교환
if(list[j]>list[j+1]){
temp = list[j];
list[j] = list[j+1];
list[j+1] = temp;
}
}
}
}시간 복잡도: O(n^2)
3. 운영체제
📖 컴파일러와 인터프리터
➡️ 컴파일러와 인터프리터 모두 고레벨 언어를 기계어로 변환하는 역할을 수행
컴파일러는 전체 코드를 보고 한번에 해석하지만 인터프리터는 소스코드의 각 행을 연속적으로 분석하며 실행한다.
인터프리터는 고레벨 언어를 중간 레벨 언어로 한 번 변환하고 이를 각 행마다 실행하기 때문에 일반적으로 컴파일러가 인터프리터보다 실행 시간이 빠른 경우가 많다.
📖 프로세스와 쓰레드
- 프로세스: 현재 실행 중인 프로그램을 의미한다. (메모리에 올라와 있음)
-
쓰레드: 프로세스 내에서 할당받은 자원을 이용해 동작하는 실행 단위
- code, data, heap 영역을 다른 쓰레드와 공유한다.
📖 컨텍스트 스위칭
➡️ Context Switching이란 인터럽트를 발생시켜 CPU에서 실행중인 프로세스를 중단하고, 다른 프로세스를 처리하기 위한 과정
- 인터럽트: CPU가 프로세스를 실행하고 있을 때, 입출력 하드웨어 등의 장치나 예외상황이 발생하여 처리가 필요함을 CPU에게 알리는 것을 말합니다.
📖 임계영역과 임계자원
➡️ 두 개 이상의 프로세스가 동시에 사용할 수 없는 자원을 임계자원(Critical Resource)라고 한다. 그리고 이에 대해 접근하고 실행하는 프로그램 내의 코드 부분을 임계영역(Critical Section)이라고 한다.
📖 교착상태(Deadlock)
➡️ 둘 이상의 프로세스가 자원을 각자 가지고 있는 채로 계속해서 기다리고 있는 상태를 의미한다. (외부적 조치가 없는 한)
📖 LRU(Least Recently Used) - 페이지 교체 알고리즘
➡️ LRU 알고리즘은 실제메모리의 페이지들 중에서 가장 오랫동안 사용되지 않은 페이지를 선택하는 방식
📖 라운드 로빈 기법
➡️ 각 프로세스는 동일한 크기의 할당 시간(time quantum)을 갖게 된다. 할당 시간이 지나면 프로세스는 선점당하고(CPU 뺏김) ready queue에 들어가게 된다.
📖 다단계 큐(MLQ)와 다단계 피드백 큐(MFQ)
- 다단계 큐: 우선순위만틈 큐를 만들어 프로세스를 스케줄링하는 기법이다. 각 프로세스는 해당되는 우선순위 큐에 들어가게 된다. (선점방식)
-
다단계 피드백 큐
- 우선순위마다 준비 큐 형성
- 항상 가장 높은 우선순위 큐의 프로세스에 CPU를 할당 (우선순위가 낮은 큐에서 작업 실행 중이더라도 상위 단계의 큐에 프로세스가 도착하면 CPU를 빼앗는 선점형 스케줄링)
- 프로세스가 시간 할당량을 다 사용하면 우선순위가 낮아지게 된다. (우선순위가 낮은 큐로 들어가게 된다.)
4. 네트워크
TCP/UDP
- TCP(Trasmission Control Protocol, 전송 제어 프로토콜)
- 연결지향: TCP 3 way handshake => 논리적으로 클라와 서버가 연결
- 데이터 전달 보증
- 순서 보장
- 신뢰할 수 있는 프로토콜
- 현재는 대부분 TCP를 사용
- UDP(User Datagram Protocal, 사용자 데이터크램 프로토콜)
- IP와 거의 같다. +PORT + 체크섬 정도만 추가
- 애플리케이션에서 추가 작업 필요
PORT
➡️ 같은 IP 내에서 프로세스 구분을 하기 위해 사용된다.
- 패킷을 보낼 때 PORT 정보를 보내기 때문에 식별할 수 있다.
IP => 아파트
PORT => 호수
DNS(Domain Name System)
➡️ IP는 기억하기 어렵고 변경될 수 있다.
그래서 도메인으로 찾는 것이다. 도메인에 IP 주소를 등록시킨다.
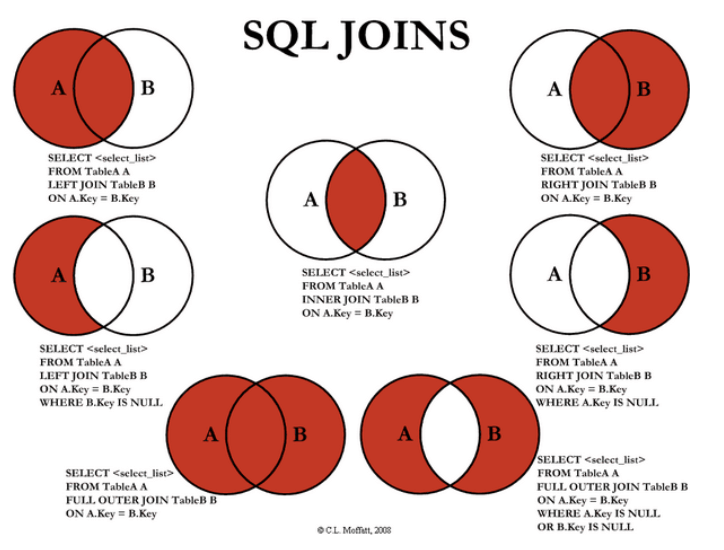
6. 데이터 베이스
7. 공통
Call By Value와 Call by Reference
- Call By Value
- 인자로 받은 값을 복사하여 처리하는 방식
- 넘어 온 값을 증가 시켜도 원래 값은 유지가 된다.
- 값을 복사하여 넘기기 때문에 메모리 사용량이 늘어난다.
- Call by Reference
- 인자로 받은 값의 주소를 참조하여 직접 값에 영향을 주는 방식이다.
- 값을 복사하지 않기 때문에 속도가 빠르다.
- 원래 값에 영향을 줄 수 있는 위험이 있다.
객체지향 프로그래밍
➡️ 프로그래밍에서 필요한 데이터를 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법
- 추상화: 공통의 속성이나 기능을 묶어 이름을 붙이는 것
- 캡슐화: 객체가 내부적으로 기능을 어떻게 구현하는지를 감추는 것
- 상속: 부모클래스의 속성과 기능을 그대로 이어받아 사용할 수 있게하고 기능의 일부분을 변경해야 할 경우 상속받은 자식클래스에서 해당 기능만 다시 수정(정의)하여 사용할 수 있게 하는 것
- 다형성: 하나의 변수명, 함수명 등이 상황에 따라 다른 의미로 해석될 수 있는 것
💡 오버로딩과 오버라이딩의 차이
- 오버로딩: 같은 이름의 메소드를 여러 개 가지면서 매개 변수를 다르게 지정하는 것
- 오버라이딩: 상위 클래스(부모 클래스)가 갖고 있는 메소드(자식 클래스)를 하위 클래스에서 재정의해 사용하는 것
References
https://jeong-pro.tistory.com/95
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/DataStructure#stack-and-queue
