
실무를 하다보면 비동기 처리를 위해 메시징 큐를 주로 사용한다. 자바에서는 Kafka가 대표적이고 우리 회사에서는 Python을 주로 사용하기 때문에 Python에 특화된 메시징 큐 기법인 Dramtiq를 사용한다, 오늘은 Kafka의 동작 방식과 특징에 대해서 알아보자
1. Kafka
Kafka란?
Kafka는 데이터를 빠르게 처리하고 전달하는 시스템으로, 여러 컴퓨터가 서로 데이터를 주고 받는데 최적화된 도구이다, 쉽게 말하면 큰 데이터를 여러 시스템에 실시간으로 전송할 수 있게 도와주는 "고속 데이터 택배 서비스"역할을 한다고 말하면 이해가 쉽다.
Kafka는 Pub-Sub(발행-구독) 방식으로 작동하는데, 이는 한쪽에서 데이터를 보내면 다른 한 쪽에서는 이 데이터를 받을 수 있도록 연결해주는 방식이다, 이를 통해 많은 데이터가 빠르게 여러 시스템으로 전달될 수 있다.
카프카의 탄색 배경
카프카는 Linked-in이라는회사에서 개발이 되었는데
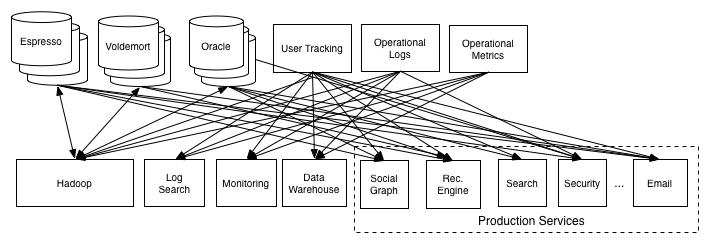
위의 사진이 기존 데이터 시스템이었는데 위의 시스템에는 문제가 많았다, 각 애플리케이션과 DB가 end-to-end로 연결되어 있고(각 파이프라인의 파편화), 요구사항이 늘어남에 따라 해당 복잡도가 증가되면서 아래와 같은 문제가 발생했다.
-
시스템 복잡도 증가
- 통합된 전송 영역이 없어 데이터 흐름을 파악하기가 어렵고, 시스템 관리가 어려움
- 특정 부분에서 장애 발생시 조치 시간 증가(연결되어 있는 애플리케이션을 모두 확인해야하기 때문)
- HW 교체/SW 업그레이드 시 관리 포인트가 늘어나고, 작업시간이 증가(연결된 애플리케이션에 side effect가 없는지 확인해야 됨)
-
데이터 파이프라인 관리의 어려움
- 각 애플리케이션과 데이터 시스템 간의 별도의 파이프라인이 존재하고 해당 파이프라인마다 데이터 포맷과 처리 방식이 다름
- 새로운 파이프라인 확장이 어려워지면서 확장성 및 유연성이 떨어짐
- 데이터 불일치 가능성 증가
파이프라인의 파편화가 무슨 뜻인가?라는 의문이 들 수 있다. 이를 쉽게 이해하기 위해 아래 예시를 참고하자
예를 들어 온라인 쇼핑몰에서 발생하는 여러 데이터 파이프라인 보자,
- 주문 데이터: 고객이 주문한 정보를 결제 시스템으로 전달하고 이후 배송 시스템으로 전달
- 재고 관리: 재품의 재고가 부족하면 알림을 보내고, 재고를 보충하는 시스템과 연결
- 추천 시스템: 고객이 상품을 클릭하거나 장바구니를 담을 때마다 그 데이터를 분석하여 추 천 시스템에 전달
이렇게 각기 다른 시스템들이 서로 독립적으로 존재하고 데이터를 주고 받는 방식으로 작동하면 파편화된 파이프라인이 되는 것이다. 이렇게 되면 문제는 시스템 간의 연결이 복잡하고 일관성이 없으면 데이터를 제대로 추적하거나 처리하기 어려운 상태가 된다.
Kafka를 통한 해결
이를 kafka를 통해 해결하면 아래와 같다.
- 주문 데이터가 발생하면 kafka가 이 데이터를 받아들여 결제 시스템, 배송 시스템, 재고 관리 시스템 등다양한 서비스로 데이터를 실시간으로 전송한다.
- 재고 상태나 추천 정보도 kafka에 의해 전달되며, 모든 데이터가 실시간으로 동기화 된다.
이렇게 kafka를 사용하여 모든 데이터 시스템 간의 데이터 흐름을 일관되게 유지하고, 각 시스템들이 서로 데이터를 주고 받을 수 있게 한다. 이렇게 되면 데이터 파이프라인이 파편화되지 않고 원할하게 연결되어 일관된 처리가 가능해진다.
다시 돌아와서 Linked-in은 위와 같은 문제를 해결하기 위해 "모든 시스템으로 데이터를 전송할 수 있고, 실시간 처리도 가능하며 확장이 용이한 시스템을 만들자"라는 목표를 가지고 Kafka를 개발했다.
Kafka 적용 후
Kafka를 적용함으로써 앞서 말했던 문제점들이 어느 정도 완화되었다.
- 모든 이벤트/데이터 흐름을 중앙에서 관리할 수 있게 되었다.
- 새로운 서비스/시스템이 추가되도 카프가가 제공하는 표준 포맷으로 연결하면 확장성과 신뢰성이 증가
- 개발자는 각 서비스간의 연결이 아닌, 서비스들의 비즈니스 로직에 집중 가능
Kafka의 동작 방식 및 특징
Kafka는 위에서 말했듯이 Pub-Sub 모델의 메세지 큐 형태로 동작한다.
우선 Kafka를 이해하기 위해서는 메시지/이벤트 브로커와 메세지 큐에 대한 전반적인 이해가 필요하다.
메시지 큐(Message Queue, MQ)란?
메시지 큐는 메시지 지향 미들웨어를 구현한 시트메으로 프로그램(프로세스)간의 데이터를 교환할 때 사용하는 기술이다.
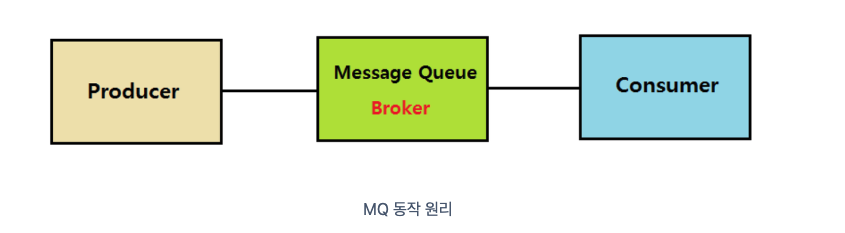
- producer: 정보를 제공하는 자
- consumber: 정보를 받아서 사용하려는 자
- Queue: producer의 데이터를 임시 저장 및 consumer에 저장
여기서 봐야될 부분은 Queue인데, MQ에서는 메시지는 Endpoint간에 직접적으로 통신하지 않고, 중간 Queue를 통해 중계된다는 점이다.
MQ의 장점
- 비동기: queue라는 저장소로 인해 나중에 처리가 가능
- 낮은 결합도: 애플리케이션과 분리
- 확장성: producer, consumer 서비스를 원하는대로 확장 가능함
- 탄력성: consumer 서비스가 다운되더라도 애플리케이션이 중단되는 것은 아니며 메시지는 지속하여 MQ에 남아있다.
- 보장성: MQ에 들어갔다면 결국 모든 메시지가 consumer 서비스에게 전달된다는 보장을 제공받는다.
메세지 브로커/이벤트 브로커
메시지 브로커
producer가 생산한 메시지를 큐에 저장한 후, 저장된 데이터를 consumer가 가져갈 수 있도록 중간 다리 역할을 broker라고 볼 수 있다.
보통 서로 다른 시스템(혹은 소프트웨어) 사이에서 데이터를 비동기 형태로 처리하기 위해 사용한다
이러한 구조를 Pub/Sub구조라고 하며 대표적으로 Redis, RabbitMQ가 있고 GCP의 pubsub, AWS의 SQS같은 서비스가 있다.
이와 같은 메시지 브로커들은 consumer가 큐에서 데이터를 가져가게 되면 즉히 혹은 짧은 시간 내에 큐에서 데이터가 삭제되는 특징이 있다.
이벤트 브로커
이벤트 브로커 또한 기본적으로 메시지 브로커의 큐 기능들을 가지고 있어 메시지 브로커의 역할도 할 수 있다,
여기서 이 둘의 가장 큰 차이점은
이벤트 브로커는 producer가 생산한 이벤트를 이벤트 처리 후에 바로 삭제하지 않고 저장하여, 이벤트 시점이 저장되어 있어 consumer가 특정 시점 부터 이벤트를 다시 consume할 수 있다는 장점이 있다(예를 들어 장애가 일어난 시점 부터 그 이후의 이벤트를 다시 처리할 수 있음)
또한 대용량 처리에 있어서는 메시지 브로커보다는 더 많은 양의 데이터를 처리할 수 있다.
이러한 이벤트 브로커에는 Kafka, AWS kinesis같은 서비스가 있다.
좀 더 자세히 살펴보자
Kafka가 아닌 일반적인 형태의 네트워크 통신은 아래와 같이 구성된다.
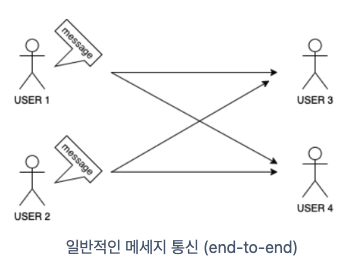
각 개체가 직접 연결하며 통신한다. 전송 속도가 빠르고 전송 결과를 신속하게 알 수 있는 반면에 특정 개체에 장애가 발생한 경우 메시지를 보내는 쪽에서 대기 처리 등을 개별적으로 해주지 않으면 장애가 전파될 수 있다. 또한 참여하는 개체가 많아질 수록 각 개체를 연결해줘야 한다.(이는 시스템이 커질수록 확장성이 좋지 않다.)
이러한 문제를 해결하고자 나온 것이 Pub/Sub 모델이다
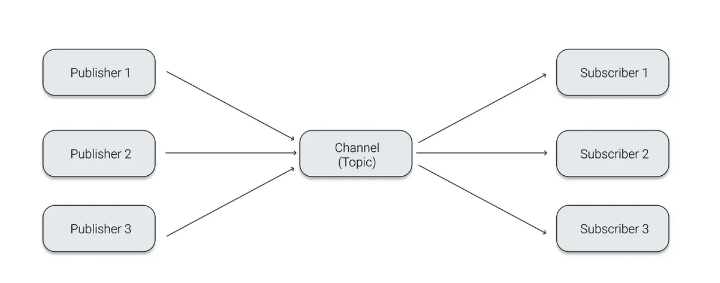
Pub/Sub 모델은 비동기 메시징 전송 방식으로 publisher는 subscriber를 특정하지 않고 publish한다. 그리고 이를 한 subscriber만 정해져 topic(메시지)를 받을 수 있다. 이처럼 subcriber은 publisher의 정보가 없어도 원하는 메시지만 수신할 수 있으며, 이런 구조 덕분에 높은 확장성을 지니고 있다.
Pub/Sub 모델의 구체적인 발행/구독 방식은 각 서비스마다 다른데 대표적으로 Kafka, Redis, RabbitMQ가 있다.
1) Redis의 동작 방식 및 특징
-
Redis는 데이터 베이스, 캐시, 메시지 브로커 및 스트리밍 엔진으로 사용되는 인메모리 데이터 구조 저장소이다.
-
구성 요소
- publisher: 메시지를 캐시
- channel: 메시지를 쌓아두는 queue
- subcriber: 메시지를 구독
-
동작
- publisher가 channel에 메시지 게시
- 해당 채널을 구독하고 있는 subscriber가 메시지를 sub에서 처리함
-
특징
- channel은 이벤트를 저장하지 않음
- channel에 이벤트가 도착했을 때 해당 채널의 subscriber가 존재하지 않는다면 이벤트가 사라짐
- subscriber는 동시에 여러 channel을 구독할 수 있으며, 특정한 channel을 지정하지 않고 패턴을 설정하여 해당 패턴에 맞는 채널을 구독할 수 있다.
-
장점
- 처리 속도가 빠름
- 캐시의 역할도 가능
- 명시적으로 데이터 삭제 가능
-
단점
- 메모리 기반으므로 서버가 다운되면 Redis 내의 모든 데이터가 사라짐
- 이벤트 도착 보장을 못함
참고로 Python의 Dramatiq 또한 Redis 브로커를 사용하고 있다.
2) RabbitMQ의 동작 방식 및 특징
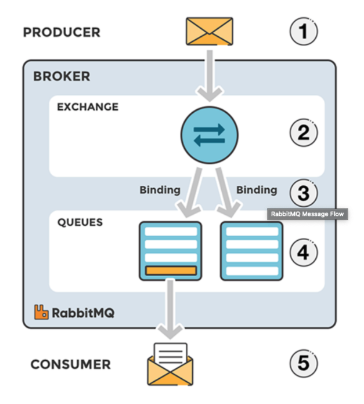
- RabbitMQ는 AMQP 프로토콜을 구현한 메세지 브로커이다.
여기서 AMQP란?
- 메세지 지향 미들웨어를 위한 개방형 표준 응용 계층 프로토콜
- Client와 Middleware broker 간의 메시지를 주고 받기 위한 프로토콜
-
구성 요소
- producer: 메시지를 보냄
- exchange: 메시지를 목적지(큐)에 맞게 전달
- queue: 메시지를 쌓아둠
- consumer: 메시지를 받음
-
메시지 처리 과정
-
Producer가 Broker로 메시지 전
-
Broker가 내 Exchange(메시지 교환기)에서 해당하는 key에 맞게 큐에 분배(Blinding or Routing이라고 함)
- topic 모드: Routing Key가 정확히 일치하는 큐에 전송(Unicast)
- direct 모드: Routing key 패턴이 일치하는 큐에 전송(MultiCast)
- headers 모드: [Key:Value]로 이뤄진 헤더 값을 기준으로 일치하는 큐에 전송(MultiCast)
- fanout 모드: 해당 Exchange에 등록되는 모든 큐에 메시지를 전송(BroadCast)
-
해당 큐에서 consumer가 메시지를 받는다.
-
-
장점
- Broker 중심적인 형태로 publisher와 Consumer 간의 보장되는 메시지 전달에 초점을 맞추고 복합적인 라우팅 지원
- 클러스터 구성이 쉽고 Manage UI가 제공되며 플러그인도 제공되어 확장성이 뛰어남
- 20kb/sec 정도의 속도
- 데이터 처리보단, 관리적 측면이나 다양한 기능 구현을 위한 서비스를 구축할 때 사용
-
단점
- MQ Server가 종료 후 재기동되면 기본적으로 Queue 내용은 모두 종료
- 성능 문제
- key 이름으로 exchange에서 수신자를 결정하므로 Producer과 Consumer간의 결합도가 높다.
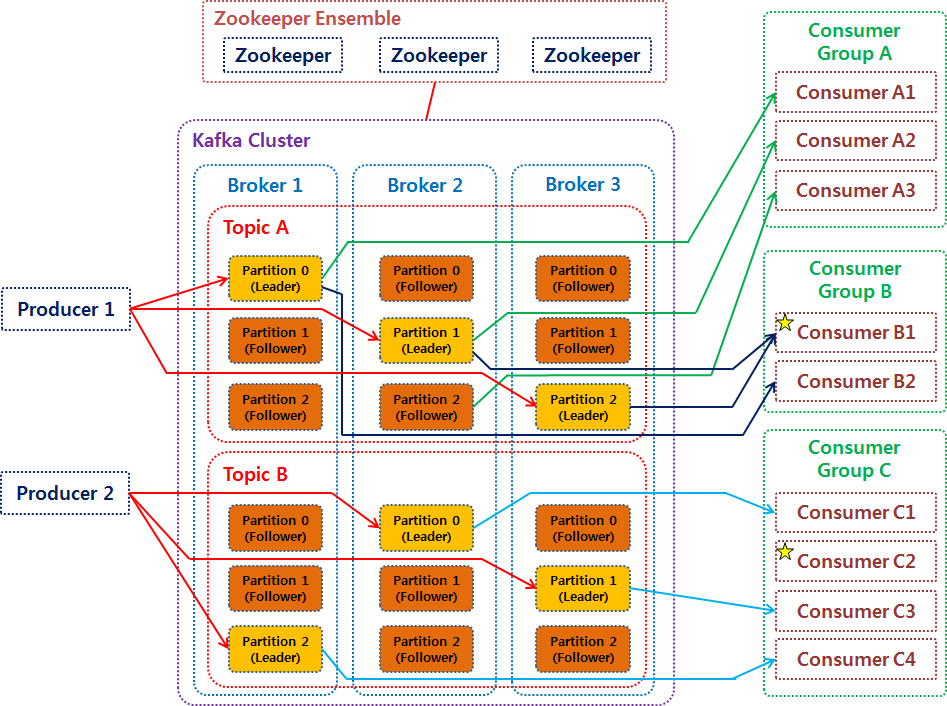
3) Kafka의 동작 방식 및 특징
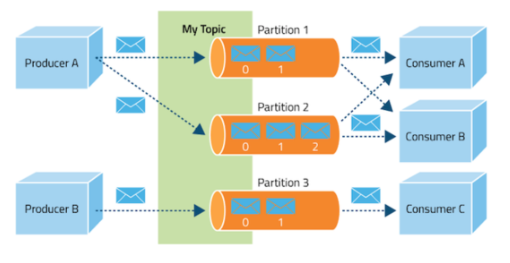
- 구성 요소
- Event: Kafka에서 producer와 consumber가 데이터를 주고받는 단위, 메시지
- Producer: Kafka에 이벤트를 게시(post, pop)하는 클라이언트 애플리케이션
- Consumer: Topic을 구독하고 이로부터 얻어낸 이벤트를 받아 처리하는 클라이언트
- Topic: 이벤트가 모이는 곳, producer는 topic에 event를 게시하고 consubmer는 topic을 구독해 이로부터 이벤트를 가져와 처리
- Partition: Topic은 여러 Broker에 분산되어 저장되며, 이렇게 분산된 topic을 partition이라고 함
- Zookeeper: 분산 메시지의 큐의 정보를 관리
- 동작원리
- Producer 전달하고자 하는 메시지를 topic을 통해 카테고리화 한다.
- Consumer는 원하는 topic을 구독함으로써 메시지를 읽어온다.
- producer와 consumer는 오로지 topic 정보만 알 뿐 서로에 대해 알지 못한다.
- kafka는 broker들이 하나의 클러스터로 구성되어 동작하도록 설계
- 클러스터 내 broker에 대한 분산처리는 zooKeeper가 담당한다.
- 장점
- 대규모 트래픽 처리 및 분산 처리에 효과적이다
이유는 Kafka는 파티셔닝이 가능한 분산 처리 메모리인데 반해 RabbitMQ는 한 큐에 모든 메시지 저장, Redis는 인메모리 데이터 저장소이기에 메모리 제한이라는 한계로 인해 Kafk의 강점이 드러난다. 또한 Kafka는 디스크 기반 저장 방식이면서도 디스크에 순차적으로 저장하므로 높은 처리 성능을 자랑하지만 RabbitMQ는 메모리와 디스크에 저장하여 디스크에 의존하는 경우에는 성능이 느려지고, 메시지 순서 보장에 더 많은 자원을 소모할 수 있기에 대규모에서는 성능이 느려진다.
- 클러스터 구성, Fail-over, Replication 같은 기능 존재
- 100kb/sec 정도의 성능
- 디스크에 메시지를 특정 주기동안 저장하여 데이터의 영속성이 보장되고 유실 위험이 적다, 또한 consumer가 장애 시 재처리 가능
- 대규모 트래픽 처리 및 분산 처리에 효과적이다
| 특징 | Kafka | RabbitMQ | Redis |
|---|---|---|---|
| 라우팅 | 기본기능으로 라우팅에 대해서 지원하지 않은다. Kafka Streams을 사용하여 동적라우팅을 구현할 수 있다. | Direct, Fanout, Topic, Headers의 라우팅 옵션을 제공하여 유연한 라우팅이 가능하다. | - |
| 프로토콜 | 단순한 메시지 헤더를 지닌 TCP 기반 custom 프로토콜을 사용하기 때문에 대체가 어렵다 | AMQP, MQTT, STOMP 등 여러 메세징 플랫폼을 지원한다. | TCP 통신 |
| 우선순위 | 변경 불가능한 시퀀스 큐로, 한 파티션내에서는 시간 순서를 보장한다. 하지만 여러 파티션이 병렬로 실행될 경우에는 시간 순서 보장 못함 | priority Queue를 지원하여 우선 순위에 따라서 처리가 가능하다. | - |
| 이벤트 저장 in Queue | 이벤트를 삭제하지 않고 디스크에 저장함으로 영속성이 보장되고 재처리 가능 | 메시지가 성공적으로 전달되었다고 판단될 경우 메시지가 큐에서 제거되므로 재처리가 어렵다. | 저장하지 않고, 채널에 이벤트가 도착했을 시 수신자가 없으면 이벤트 제거 |
| 장점 | 이벤트가 전달되어도 삭제하지 않고 디스크에 저장, | 데이터 처리보단 관리적 측면이나 다양한 기능 구현에서 강점 | Kafka보다 동기화 문제가 덜하다, 가볍다 |
| 단점 | 범용 메시지 시스템에서 제공되는 다양한 기능이 제공되지 않음 | Kafka보다 느리고 대규모 데이터에서 성능 저하 | 이벤트 도착을 보장 못함 |
4) 사용 구분
- 대용량 데이터처리, 실시간 고성능, 고가용성이 필요한 경우, 또는 저장된 이벤트를 기반으로 로그를 추적하고 재처리 하는 것이 필요한 경우 Kafka를 사용
- 복잡한 라우팅을 유연하게 처리해야 하고 정확한 요청-응답이 필요한 application을 사용할 경우 또한 트래픽은 작지만 장시간 실행되고 안정적인 백그라운드 작업이 필요한 경우 RabbitMQ 사용
- 이벤트 데이터를 DB에 저장하기 때문에 굳이 미들웨어에 이벤트를 저장할 필요가 없는 경우, consumer에게 굳이 꼭 알람이 도착해야한다는 보장없이 알람처럼 push 보내는 것이 중요하다면 유지보수가 편한 redis 사용
카프카의 구성 요소
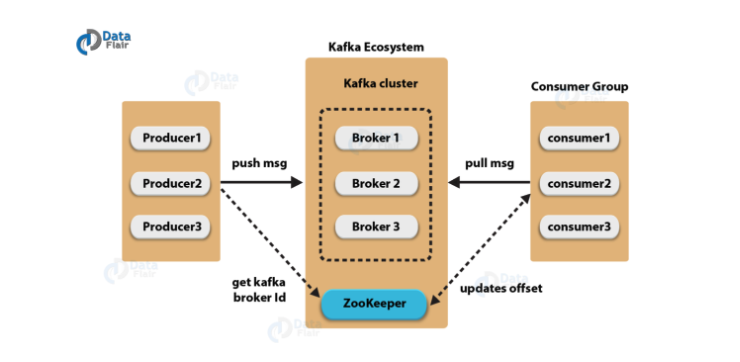
카프카의 구성요소
Topic
- 각각의 메시지를 목적에 맞게 구분할 때 사용한다.
- 메시지를 전송하거 소비할 때 Topic을 반드시 입력한다.
- consumer는 자신이 담당하는 topic의 메시지를 처리한다.
- 한 개의 토픽은 한 개 이상의 파티션으로 구성된다.
Partition
- 분산처리를 위해 사용된다.
- Topic 생성시 partition 개수를 지정할 수 있다.
- 파티션이 1개라면 모든 메시지에 대해 순서가 보장된다.
- 파티션 내부에서 각 메시지는 offset(고유 번호)로 구분
- 파티션이 여러개라면 Kafka 클러스터가 라운드 로빈 방식으로 분배해 분산처리 되기 때문에 순서 보장이 안된다.
- 파티션이 많을 수록 처리량이 좋지만 장애 복구 시간이 늘어난다.
Offset
- 컨슈머에서 메시지를 어디까지 읽었는지 저장하는 값
- 컨슈머의 그룹의 컨슈머들은 각각의 파티션에 자신이 가져간 메시지의 위치 정보를 기록
- 컨슈머 장애 발생 후 다 살아나도, 전에 마지막으로 읽었던 위치에서부터 다시 읽어 드릴 수 있다.
Producer
- 메시지를 만들어서 카프카 클러스터에 전송
- 메시지 전송시 batch 처리 가능
- key 값을 지정하여 특정 파티션으로만 전송이 가능
- 전송 acks값을 설정하여 효율성을 높일 수 있다.
- ACKS=0 -> 매우 빠르게 전송, 파티션 리더가 받았는지 알 수 없다.
- ACKS=1 -> 파티션 리더가 받았는지 확인(기본값)
- ACKS=ALL -> 파티션 리더 뿐만 아니라 팔로워까지 메시지를 받았는 지 확인
Consumer
- 카프카 클러스터에서 메시지를 읽어서 처리한다.
- 메시지를 batch 처리할 수 있다.
- 한 개의 컨슈머는 여러개의 토픽을 처리할 수 있다.
- 메시지를 소비하여도 메시지를 삭제하지 않는다
- 컨슈머는 컨슈머 그룹에 속한다.
- 한 개 파티션은 같은 컨슈머 그룹의 여러개의 컨슈머에서 연결할 수 없다.
Broker
- 실행된 카프카 서버를 말한다.
- 프로듀서와 컨슈머는 별더의 애플리케이션으로 구성되는 반면 브로커는 카프카 그 자체이다.
- 브로커는 카프카 클러스터 내부에 존재한다.
- 서버 내부에 메시지를 저장하고 관리하는 역할을 수행한다.
ZooKeeper
- 분산 애플리케이션 관리를 위한 코디네이션 시스템
- 분산 메시지큐의 메타 정보를 중앙에서 관리하는 역할
주요 설계 특징
왜 하나의 topic을 여러개의 partition으로 분산시키는가?
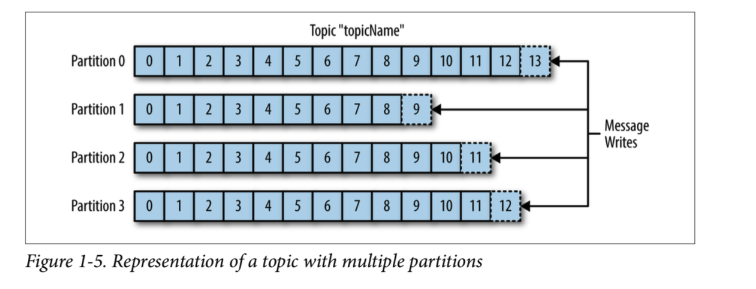
- 병렬로 처리하기 위해 분산저장을 한다.
- 카프카의 토픽에 메시지가 쓰여지는 것도 어느정도 시간이 소비된다. 몇 천건의 메시지가 동시에 카프카에 write이 되면 병목현상 발생
- 따라서 파티션을 여러개 두어서 분산 저장함으로써 write 동작을 병렬로 처리할 수 있다.
- 다만 한번 늘린 파티션은 절대 줄일 수 없기 때문에 운영 중에 파티션을 늘려야 하는 건 충분히 검토 후 실행되어야 한다.(최소한의 파티션으로 운영하고 사용량에 따라 늘리는것을 권장)
- 파티션이 늘렸을 때 메시지는 Round-Robin 방식으로 쓰여진다 , 따라서 하나의 파티션 내에서는 메시지 순서가 보장되지만 파티션이 여러개면 순서가 보장되지 않는다.
컨슈머 그룹은 왜 존재할까?
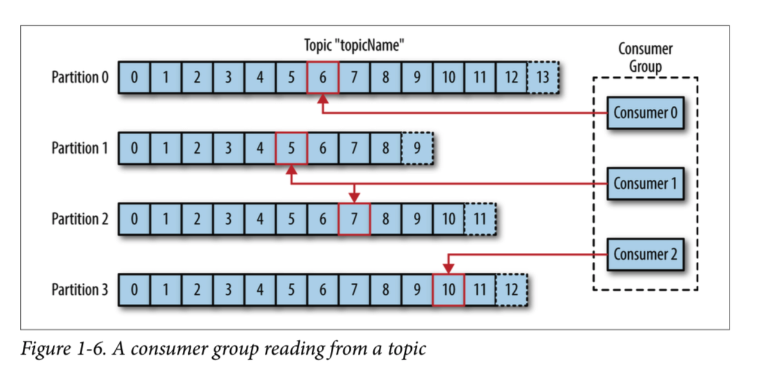
- consumer의 묶음을 consumer group이라고 한다.
- consumer 그룹은 하나의 토픽에 대한 책임을 가지고 있다.
- 즉 어떤 consumer가 다운이 된다면 파티션 재조정을 통해 다른 컨슈머가 해당 파티션을 맡아서한다. offset정보를 그룹간의 공유하고 있기 때문에 down되기 전 마지막 메시지 위치에서부터 시작한다.
출처
