Chapter 02
1) 데이터 분석과정
추가숙제
- 1단계 : 데이터 분석 설계하기
- 주제선정 -> 가설 설정 -> 분석가능 변수 구성 (파생변수 고려) -> 분석항목 결정
- 주제선정 -> 가설 설정 -> 분석가능 변수 구성 (파생변수 고려) -> 분석항목 결정
- 2단계 : 데이터 준비
- 필요한 데이터 준비
- 웹 크롤링
- 3단계 : 데이터 가공
- 원시 데이터(처음의 데이터, 가공 X)를 원하는 형태의 데이터로 가공
- 여러 데이터 세트 병합, 추출하여 새로운 데이터 세트 생성 가능
- 4단계 : 데이터 분석
- 기술통계랑 (빈도, 평균, 최댓값, 이상치 등)으로 데이터 파악
- 시각화
- 5단계 : 결론 도출
- 가설 검정 및 최종결과 도출
- 가설 검정 및 최종결과 도출
2) 데이터의 생김새
(1) 데이터 구조 간 관계
- 벡터 : 한 가지 데이터 유형으로 구성된 1차원 구조의 데이터
- 행렬 : 한 가지 데이터 유형으로 구성된 2차원 구조의 데이터
- 배열 : 행렬을 n차원으로 확대한 데이터
- 리스트 : 숫자형, 문자형 벡터 등 여러 데이터 유형이 포함된 1차원 구조의 데이터
- 데이터 프레임 : 리스트를 2차원으로 확대한 구조의 데이터
(2) 데이터 유형
- 숫자형 : 숫자로만 이루어진 데이터
- 문자형 : 문자로만 이루어진 데이터
- 논리형 : TRUE 혹은 FALSE로 이루어진 데이터
(3) 데이터 유형에 따른 분류
- 단일형 : 숫자형, 문자형 같이 한 가지 데이터 유형으로만 구성된 데이터 (벡터, 행렬, 배열)
- 다중형 : 숫자, 문자데이터 등 여러 가지 데이터 유형으로 구성된 데이터 (리스트, 데이터프레임)
(4) 차원에 따른 분류
| 장점 | 1차원 | 2차원 | n차원 |
|---|---|---|---|
| 단일형 | 벡터 | 행렬 | 배열 |
| 다중형 | 리스트 | 데이터프레임 | - |
(5) 벡터
- 할당 연산자 :
<- 기호,C() 함수
변수명 <- c(값)(a) 숫자형 벡터 생성하기
ex_vector1 <- c(-1, 0, 1) #데이터 생성
ex_vector1 # 변수 조회
>> [1] -1 0 1 [1] : 데이터 위치 표시 , 출력한 벡터 중 첫번째 요소부터 표시
>> [1] 1 2 3 4 5 # 1번째 요소부터 표시
>> [6] 6 7 8 9 10 # 6번째 요소부터 표시(b) 숫자형 벡터 속성과 같이 확인
mode(ex_vector1)
str(ex_vector1)
length(ex_vector1)
>> [1] "numeric"
num [1:3] -1 0 1
[1] 3mode() 함수 : 데이터 유형 확인, "numeric"은 벡터가 숫자형 이라는 의미
str() 함수 : 데이터 유형 값을 전체적으로 확인 // num(숫자형), 변수에 포함된 데이터 전체 값 출력
length() 함수 : 데이터 길이 확인 // 벡터의 길이가 3, 즉 3개의 값을 가진 벡터임
참고 : str() 함수 / mode() 함수 / typeof() 함수
| #정수형 | #문자형 | #논리형 |
|---|---|---|
| str(12345) >>num 12345 mode(12345) >>[1] "numeric" typeof(12345) >>[1] "double" | str("helloworld") >>chr "helloworld" mode("helloworld") >>[1] "character" typeof("helloworld") >>[1] "character" | str(TRUE) >>logi TRUE mode(TRUE) >> [1] "logical" >> typeof(TRUE) >> [1] "logical" |
(c) 문자형 벡터 생성하기
ex_vector2 <- c('Hello', 'Hi~!')
ex_vector2
ex_vector3 <- c('1', '2', '3')
ex_vector3
>> [1] 'Hello' 'Hi~!'
[1] '1' '2' '3'(d) 문자형 벡터 속성과 같이 확인
mode(ex_vector2)
str(ex_vector2)
mode(ex_vector3)
str(ex_vector3)
>> [1] 'character'
chr [1:2] 'Hello' 'Hi~!'
[1] 'character'
chr [1:3] '1' '2' '3'(e) 논리형 벡터 생성하고 속성 확인하기
ex_vector4 <- c(TRUE, FALSE, TRUE, FALSE)
ex_vector4
mode(ex_vector4)
str(ex_vector4)
>> [1] TRUE, FALSE, TRUE, FALSE
[1] 'logical'
chr [1:4] TRUE, FALSE, TRUE, FALSE참고 : 데이터 세트 삭제하기
remove(ex_vector2) # ex_vector2 벡터 삭제
rm(ex_vector3) # ex_vector3 벡터 삭제(f) 범주형 데이터 생성하기
ex_vector5 <- c(2, 1, 3, 2, 1)
ex_vector5
cate_vector5 <- factor(ex_vector5, labels = c('Apple', 'Banana', 'Cherry'))
cate_vactor5
>> [1] 2 1 3 2 1 #그룹 순서 범주화
[1] Banana Apple Cherry Banana Apple
Levels: Apple Banana Cherry(6) 행렬과 배열
matrix(벡터, nrow = 행 개수, ncol = 열 개수)
(a) 행렬 데이터 생성하기
x <- c(1, 2, 3, 4, 5, 6)
matrix(x, nrow = 2, ncol = 3)
matrix(x, nrow = 3, ncol = 2)
>> [,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
[,1] [,2]
[1,] 1 3
[2,] 2 4
[3,] 3 6(b) 옵션 추가로 결과 비교하기
byrow: 데이터를 왼쪽 -> 오른쪽, 열부터 채운다는 옵션 / T, F 대문자만 가능 / 기본값 F는 생략가능
x <- c(1, 2, 3, 4, 5, 6)
matrix(x, nrow = 2, ncol = 3)
matrix(x, nrow = 3, ncol = 2, byrow = T)
>> [,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
[,1] [,2]
[1,] 1 3
[2,] 2 4
[3,] 3 6(7) 배열
array (변수명, dim = c(행 수, 열 수 , 차원 수))
(a) 배열 생성하기
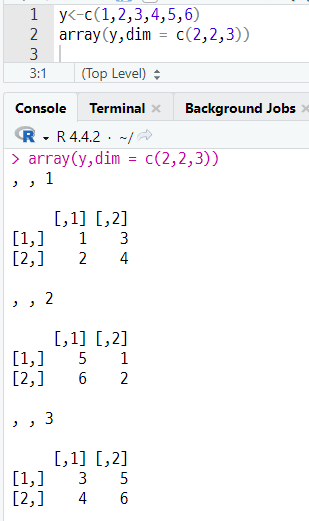
(8) 리스트
(a) 리스트 생성하기
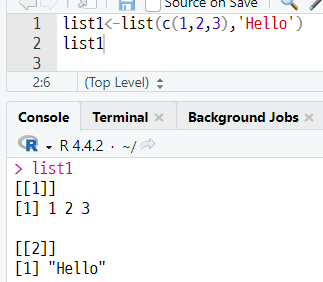
(b) 변수 속성 확인하기
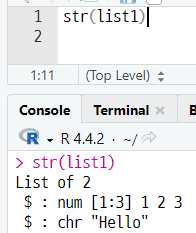
참고 : 인덱스
list[[1]]
>> [1] 123(9) 데이터 프레임
data.frame(변수명1, 변수명2, ... , 변수명n)
(a) 데이터 프레임 생성하기
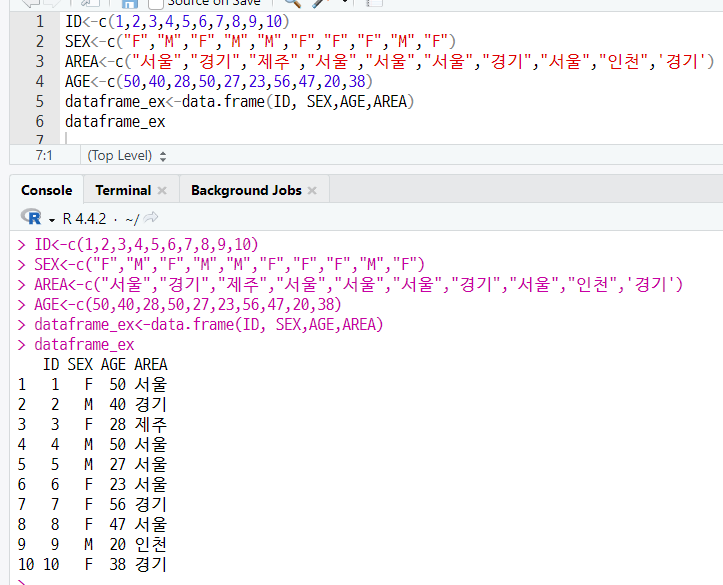
(b) 변수 속성 확인하기
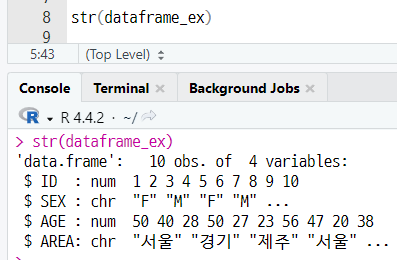
10obs. : 관측치 (observations) 줄임말
- ID : 숫자형(num) 데이터 10개 (1 2 3 4 5 6 7 8 9 10) 포함
- SEX : 요소 2개 (F M)를 데이터 값으로 포함
- AGE : 숫자형(num) 데이터 10개 (50 40 28 50 27 23 56 47 20 38) 포함
- AREA : 요소 4개(서울 경기 ...)를 데이터 값으로 포함
3) 숙제
기본숙제
a) p99 3번
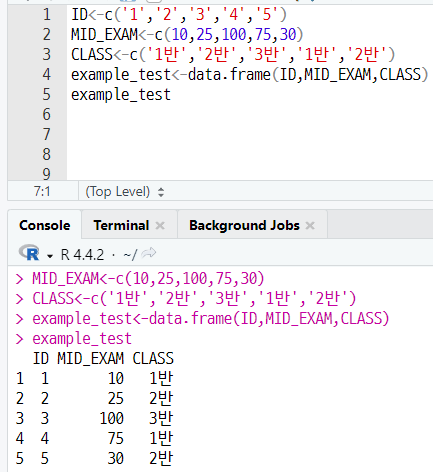
문자형으로 이루어진 데이터 1, 2, 3, 4, 5는 ID 변수로,
숫자형으로 이루어진 데이터 10, 25, 100, 75, 30은 MID_EXAM 변수로,
문자형으로 이루어진 데이터 1반, 2반, 3반, 1반, 2반은 CLASS 변수로 구성해보세요.

b) p99 4번
data.frame() 함수와 3번 문항에서 구성한 ID, MID_EXAM, CLASS 변수를 사용하여 example_test 데이터 세트를 저장해보세요.

열심히해서 허니콤보 맨날 먹자 !