Chapter 04
1) 데이터 수집하기
(1) 직접 데이터 입력하기
변수명 <- c(값)
(a) 직접 데이터 입력하기
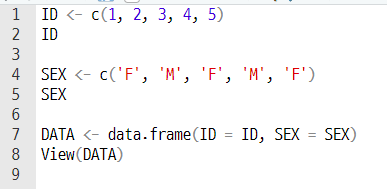
View 함수는 반드시 대문자로 입력 !

(2) 외부 데이터 가져오기 : TXT 파일
read.table() 함수 이용
read.table('원시 데이터', header = FALSE, skip = 0, nrows = -1, sep = "", ... )
-
header : 원시 데이터의 1행이 변수명인지 아닌지 판단
-
skip : 특정 행까지 제외하고 데이터를 가져옴
-
nrows : 특정 행까지 데이터를 가져옴
-
sep : 데이터의 구분 문자 지정
(a) TXT 파일 가져오기
ex_data <- read.table("C:/Rstudy/data_ex.txt", encoding = "EUC-KR", fileEncoding = "UTF-8") View(ex_data)
2-1. header 옵션
header = TRUE : 원시 데이터 1행이 변수명임을 지정
(a) 변수명 지정하기
ex_data <- read.table("C:/Rstudy/data_ex.txt", encoding = "EUC-KR", fileEncoding = "UTF-8",header = TRUE) View(ex_data)
(b) 변수명으로 사용할 행이 없을 때
varname <- C("ID", "SEX", "AGE", "AREA") ex1_data <- read.tavle("C:/Rstudy/data_ex_col.txt", encoding = "EUC-KR", fileEncoding = "UTF-8", col.names = varname) View(ex1_data)
row.names 옵션 : 행 이름 부여할 때
2-2. skip 옵션
(a) 행 스킵하여 가져오기
ex_data2 <- read.table("C:/Rstudy/data_ex.txt", encoding = "EUC-KR", fileEncoding = "UTF-8",header = TRUE, skip = 2) View(ex_data2)
skip = 2 : 제목 행 제외 두 줄 스킵하고, 세번째 줄부터 출력
2-3. nrows 옵션
(a) 행 개수 지정하여 가져오기
ex_data3 <- read.table("C:/Rstudy/data_ex.txt", encoding = "EUC-KR", fileEncoding = "UTF-8",header = TRUE, nrows = 7) View(ex_data3)
nrows = 7 : 1~7행까지의 원시데이터 가져옴
2-4. sep 옵션
sep = "," : 구분자 쉼표(,)
(a) 데이터 구분자 지정하여 가져오기
ex_data4 <- read.table("C:/Rstudy/data_ex.txt", encoding = "EUC-KR", fileEncoding = "UTF-8",header = TRUE, sep = ",") View(ex_data4)
sep = "," : 쉼표(,)를 기준으로 열을 구분하여 가져옴
(3) 외부 데이터 가져오기 : 엑셀 파일
read_excel("원시 데이터 이름:)
(a) readxl 패키지 설치 및 로드하기
(b) 엑셀 파일 가져오기
excel_data_ex <- read.table("C:/Rstudy/data_ex.xlsx") View(excel_data_ex)
엑셀 파일에 시트 탭 여러 개 일 때 : read_excel("C:/위치", sheet = 2)
(4) 외부 데이터 가져오기 : XML, JSON 파일
4-1. XML 파일 가져오기
xmlToDataFrame() 함수 가장 많이 사용 !
xmlToDataFrame("원시 데이터")
(a) XML 패키지 설치 및 로드하기
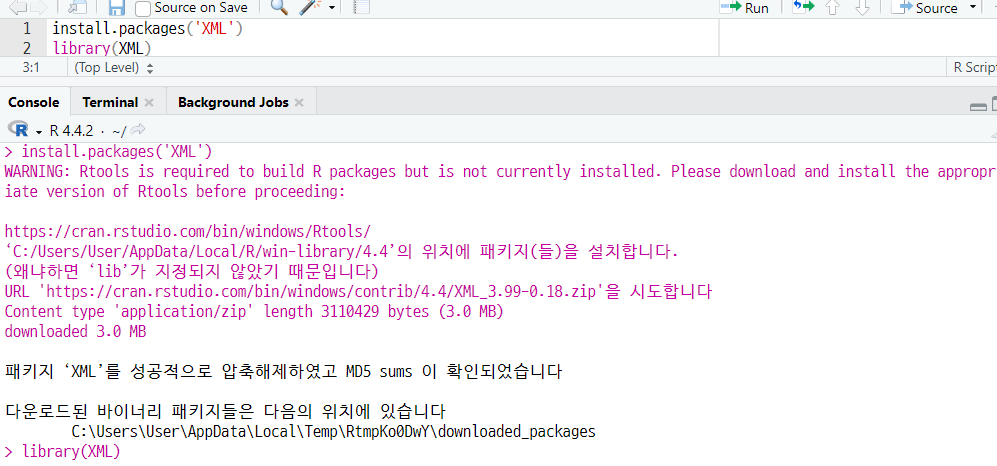
(b) XML 파일 가져오기
xml_data <- xmlToDataFrame("C:/Rstudy/data_ex.xml") View(xml_data)
태그 명이 상단 행 변수명이 됨 !
4-2. JSON 파일 가져오기
JSON 파일 : 데이터 안에 데이터가 정의된 중접데이터 구조, 속성 - 값 쌍
{
"이름" : "홍길동",
"나이" : 25,
"성별" : "여",
"주소" : "서울특별시 양천구 목동",
"특기" : ["농구", "도술"]
"가족관계" : {"#" : 2, "아버지" : "홍판서", "어머니" : "춘섬"}, #중첩데이터 구조
"회사" : "경기 수원시 팔달구 우만동"
}fromJSON("원시 데이터")
(a) jsonlite 패키지 설치 및 로드하기
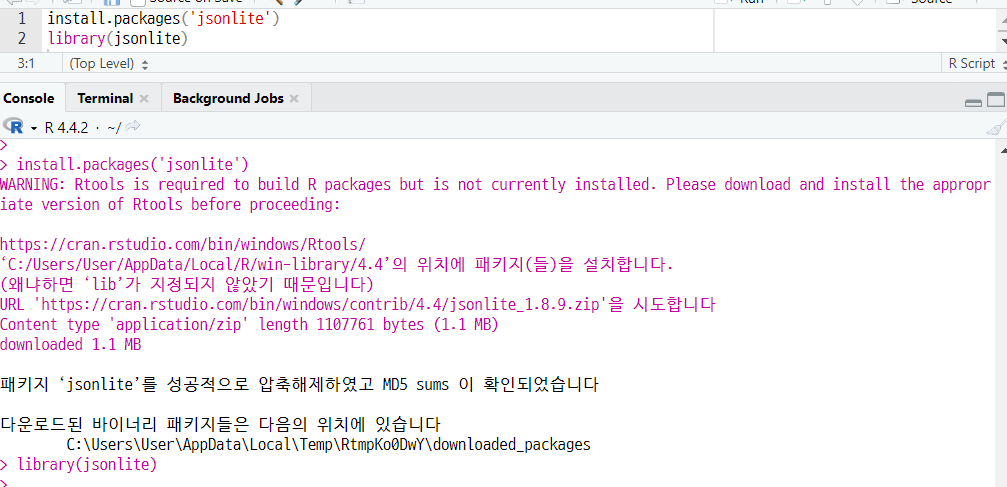
(b) JSON 파일 가져오기
json_data <- fromJSON("C:/Rstudy/data_ex.xml") View(json_data)
List of 7
$ 이름 : chr "홍길동"
$ 나이 : int 25
$ 성별 : chr 여
$ 주소 : chr "서울특별시 양천구 목동"
$ 특기 : chr [1:2] "농구" "도술"
$ 가족관계:List of 3
..$ # : int 2
..$ 아버지 : chr "홍판서"
..$ 어머니 : chr "춘섬"
$ 회사 : chr "경기 수원시 팔달구 우만동"
List of 7 : JSON 파일을 리스트 형식으로 가져왔으며, 7개의 속성으로 구성 !
2) 데이터 관측하기
(1) 데이터 전체 확인하기
data()
(a) 내장 데이터 세트 가져오기
data("iris")
(b) 데이터 세트 확인하기
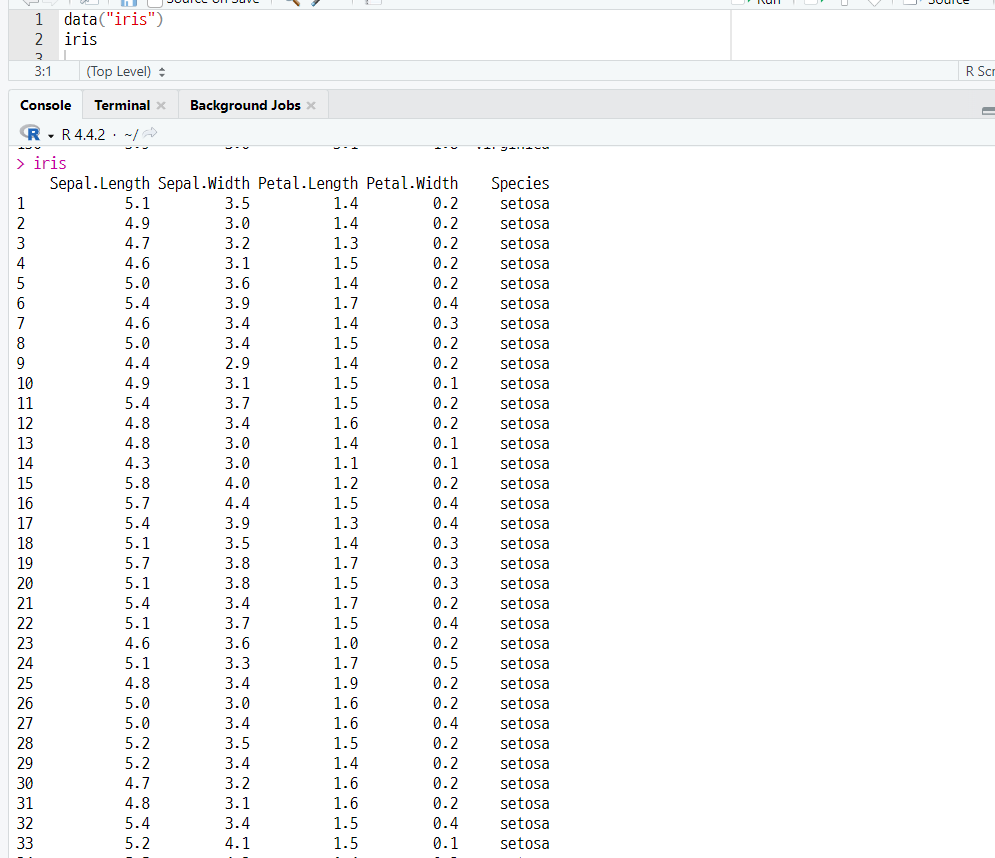
(2) 데이터요약 확인하기
2-1. 데이터 구조 확인하기
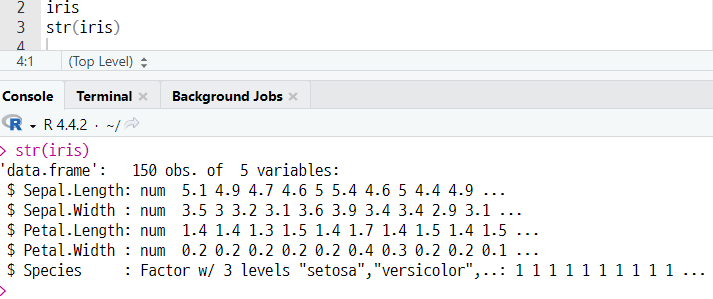
str(변수명)
(a) 데이터 구조 확인하기 (기본숙제)
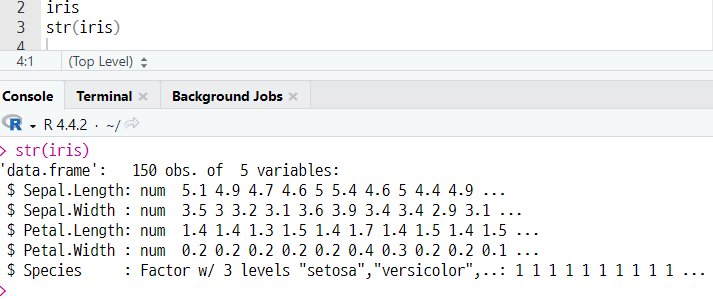
2-2. 데이터 세트 컬럼 및 관측치 확인하기
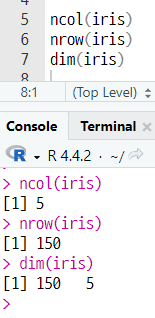
- ncol() 함수 : df컬럼 (열) 개수 확인
ncol(변수명) - nrow() 함수 : df관측치 (행) 개수 확인
nrow(변수명) - dim() 함수 : df컬럼 (열) 및 관측치 (행) 개수 확인
dim(변수명)
(a) 데이터 세트 컬럼 및 관측치 확인하기
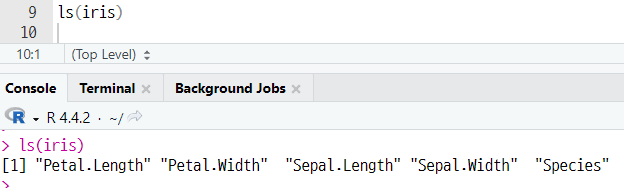
2-3. 데이터 세트 컬럼명 확인하기
ls(변수명)
(a) 데이터 세트 컬럼명 확인하기
2-4. 데이터 앞부분과 뒷부분 값 확인하기
head(변수명, n = 수량)
tail(변수명, n = 수량)
(a) 데이터 앞부분 값 확인하기
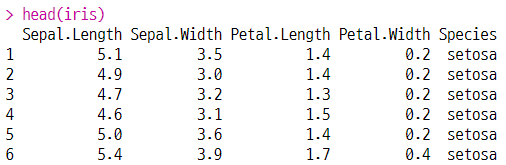
(b) 데이터 뒷부분 값 확인하기

(3) 기술통계량 확인하기
3-1. 평균과 중앙값
- 평균 :
mean(변수명) - 중앙값 :
median(변수명)
(a) 평균, 중앙값 구하기
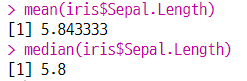
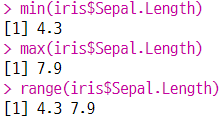
3-2. 최솟값, 최댓값과 범위
- 최솟값 :
min(변수명) - 최댓값 :
max(변수명) - 범위 :
range(변수명)
(a) 최솟값, 최댓값, 범위 구하기
3-3. 분위수
- 제1사분위수 (Q1) : 제 0.25분위수,
하위25%에 해당하는 값 - 제2사분위수 (Q2) : 제 0.50분위수,
50%에 해당하는 값 - 제3사분위수 (Q3) : 제 0.75분위수,
하위75%혹은상위25%에 해당하는 겂 - 제4사분위수 (Q4) : 제 1분위수,
100%에 해당하는 값
분위수 : quantile()함수
quantile(변수명, probs = 0 ~ 1)
(a) 사분위수 구하기

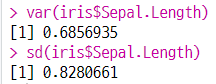
3-4. 분산과 표준편차
- 분산 :
var(변수명), 작을수록 데이터가 평균 값에 몰려있음 - 표준편차 :
sd(변수명), 클수록 데이터가 넓게 퍼져있음
(a) 분산과 표준편차 구하기
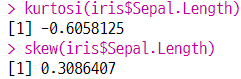
3-5. 첨도와 왜도
- 첨도 :
kurtosi(변수명), 통계량이 0보다 크면 정규분포 대비 그래프 곡선 뽀족, 0보다 작으면 완만함 - 왜도 :
skew(변수명), 0에 가까울수록 좌우대칭, 0보다 큰 경우 오른쪽 꼬리, 0보다 작은경우 왼쪽꼬리
(a) psych 패키지 설치 및 로드하기

(b) 첨도와 왜도 구하기
(4) 데이터 빈도 분석하기
-
빈도분석 :
freq(변수명), 데이터의 항목별 빈도 및 빈도 비율을 나타내는 방법, 데이터 분포 파악할 때 가장 많이 사용하는 분석 기법
(a) dexcr 패키지 설치 및 로드하기
(freq() 함수는 descr패키지에 포함되어 있으므로 먼저 패키지 설치 후 로드 !)
(b) 빈도분석하기

plot = F옵션 제외 : 막대 그래프 출력 제외하는 옵션
freq_test <- freq(iris$Sepal.Length)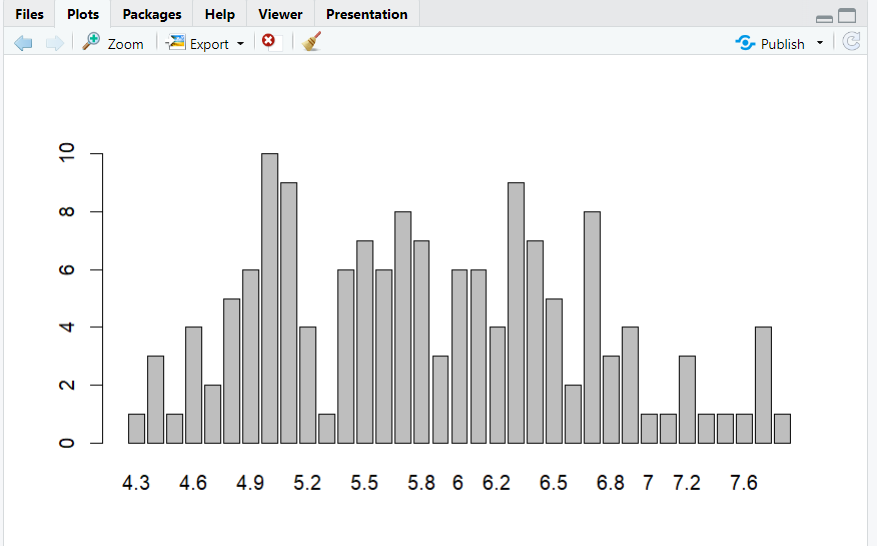
3) 데이터 탐색하기
(1) 막대 그래프 그리기
1-1. freq 함수
freq(변수명, plot = T, main = '그래프 제목')
(a) 엑셀파일 가져오기
library(readxl) exdata1 <- read_Excel("C:/Rstudy/Sample1.xslx") exdata1
(b) 막대 그래프 그리기
freq(exdata1$SEX, plot = T, main = '성별(barplot)')
exdata1$SEX : exdata1의 SEX 변수 지정
1-2. barplot() 함수
barplot() : 별도의 패키지를 설치하지 않아도 막대그래프를 그릴 수 있으나 빈도 분포를 구하는 기능이 없으므로 table() 함수와 함께 사용
barplot(변수명, ylim = c(y축 범위), main = '그래프 제목', xlab = 'x축 제목', ylab = 'y축 제목', names = c('컬럼 제목', ...), col = c('컬러',...),...)
- ylim :
출력할 y축의 범위지정c()함수를 사용해 벡터 형태로 지정 - main :
그래프 제목지정 - xlab :
x축 제목지정 - yalb :
y축 제목지정 - names : c() 함수를 사용해 벡터 형태로
컬럼 제목지정 - col : c() 함수를사용해 벡터 형태로
그래프 색상지정
(a) 빈도 분포를 구하고 막대 그래프 그리기
dist_sex <- table(exdata1$SEX) dist_sex barplot(dist_sex)
(b) 막대 그래프 축 범위와 제목 지정하기
barplot(dist_sex, ylim = c(0, 14), main = "BARPLOT", xlab = "SEX", ylab = "FREQUENCY", names = c("FEMALE", "MALE")
(c) 막대 그래프 색상 변경하기
barplot(dist_sex, ylim = c(0, 14), main = "BARPLOT", xlab = "SEX", ylab = "FREQUENCY", names = c("FEMALE", "MALE"), col = c("pink", "navy")
col = c("pink", "navy") : 핑크, 네이비 컬러로 지정
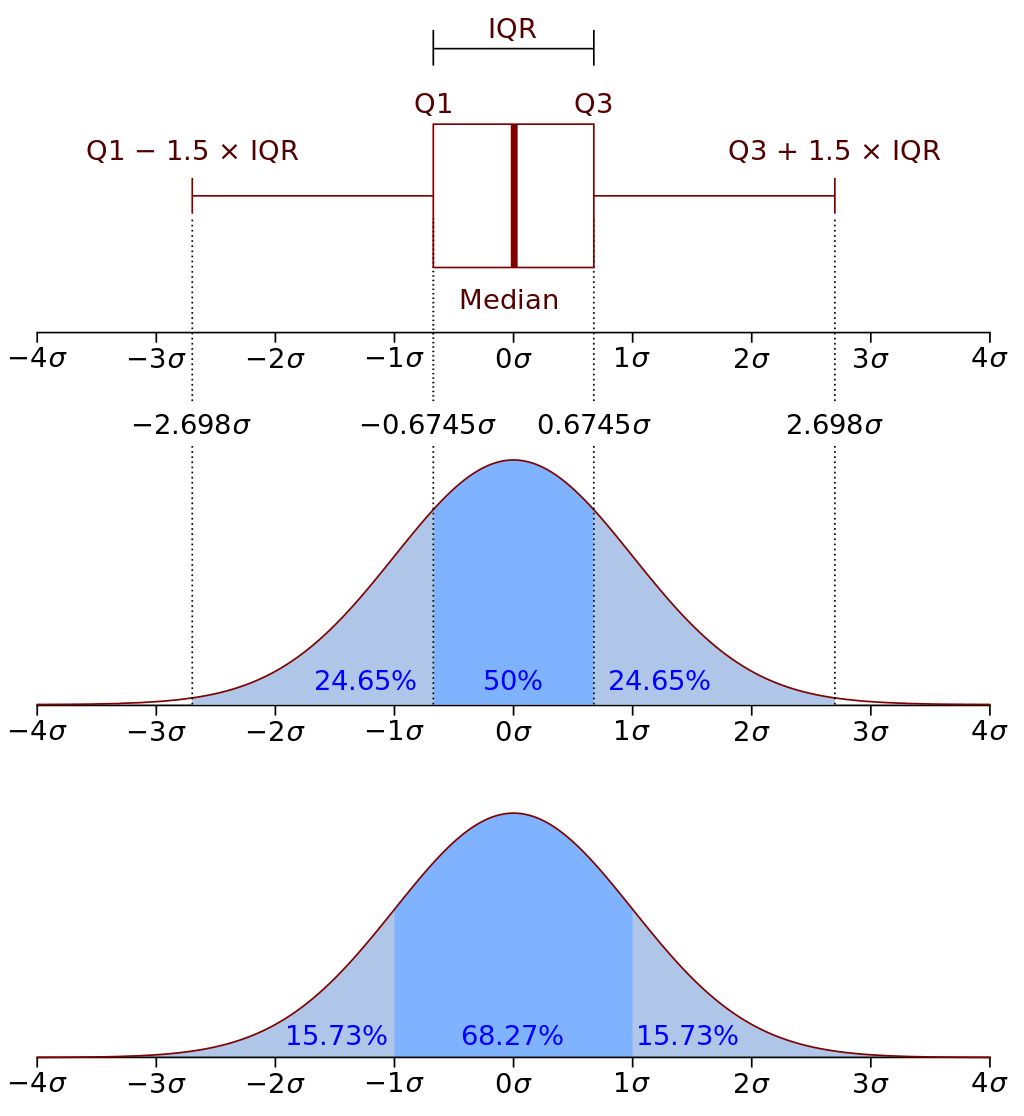
(2) 상자 그림 그리기
데이터 분포 비고, 이상치 판단할 때 주로 사용
극단값(최댓값과 최솟값), 제3사분위수, 평균값, 중앙값, 제1사분위수로 구성
barplot(변수명)
상자그림 이상치 : 최댓값 혹은 최솟값 라인 바깥에 동그라미(O)로 표시
(3) 히스토그램 그리기
| 항목 | 히스토그램 | 막대 그래프 |
|---|---|---|
| 함수 | hist() | barplot() |
| 데이터 형태 | 연속형 | 이산형 |
| 데이터 예시 | 키, 나이 , 금액 등 | 성별, 지역 등 |
| 그래프 형태 차이 | 그래프 막대가 붙어 있음 | 그래프 막대 분리되어 있음 |
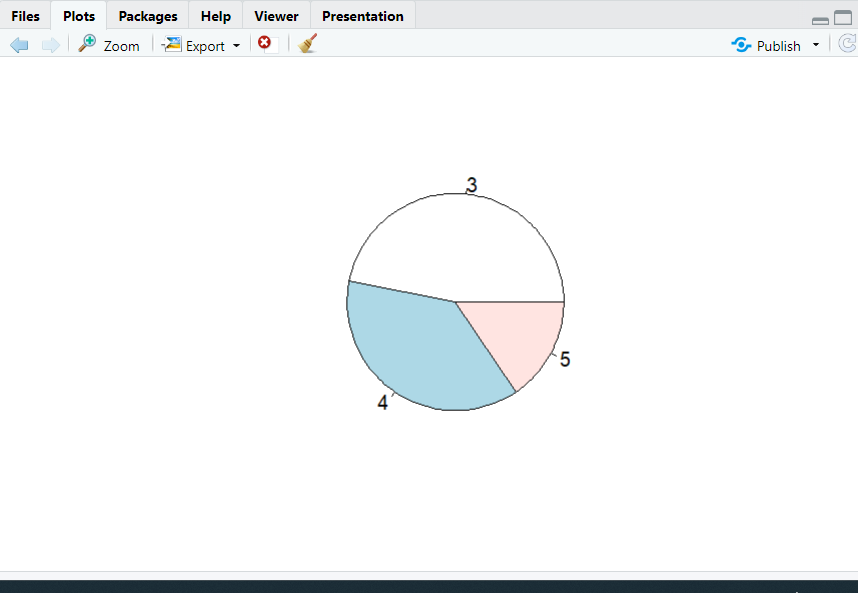
(4) 파이차트 그리기
pie(변수명) , 원을 데이터 범주 구성이 비례에 따라 파이 조각을 나누는 것처럼 표현,
여러개의 부채꼴 모양으로 구성
(a) 파이차트 그리기
1. pie() 함수에는 빈도분석 기능이 없으므로 먼저 빈도분석을 하는 table()함수 실행
2. mtcars 데이터 세트의 gear 변수 값을 x에 저장하고, x에 대한 파이차트 그리기

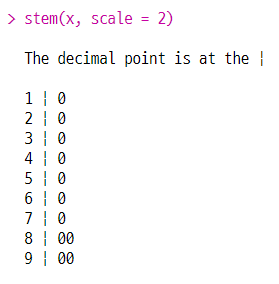
(5) 줄기 잎 그림 그리기
stem(변수명, scale = 1)
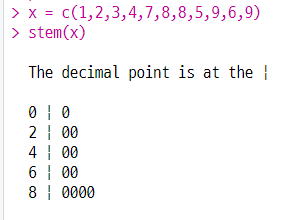
| 줄기 구간 | 구간에 속한 데이터 |
|---|---|
| 0이상 2미만 | 1 |
| 2이상 4미만 | 2 3 |
| 4이상 6미만 | 4 5 |
| 6이상 8미만 | 6 7 |
| 8이상 | 8 8 9 9 |
scale 옵션 : 구간 조정

(6) 산점도 그리기
plot(x, y)
(a) 산점도 그리기

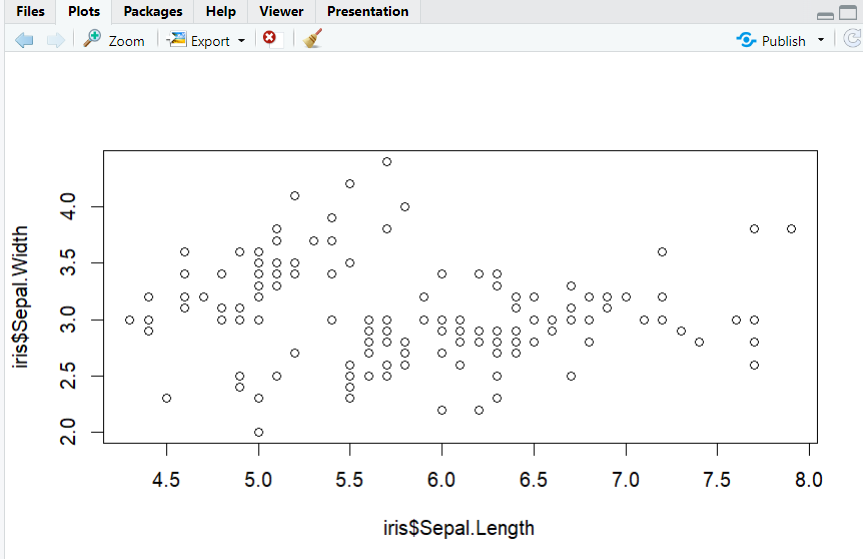
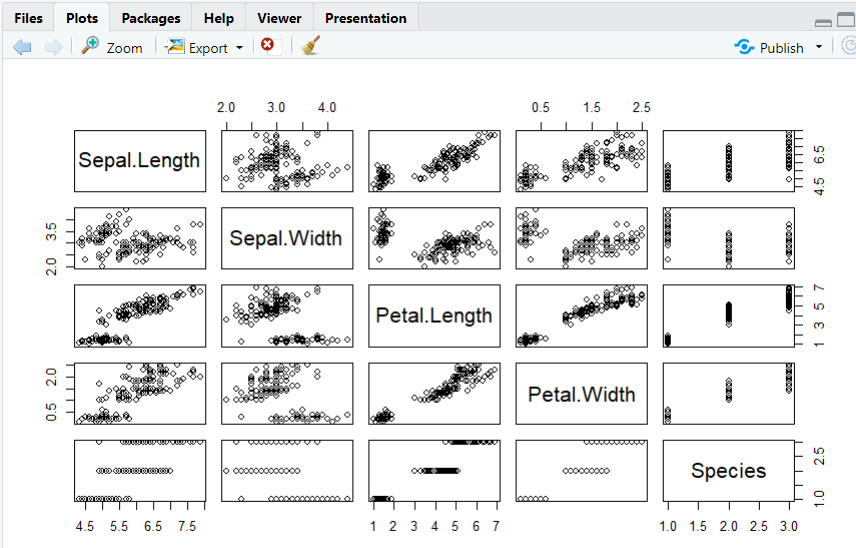
6-1. 산점도 행렬
pairs(변수명)
(a) 산점도 행렬 그리기

(b) psych 패키지로 산점도 행렬 그리기

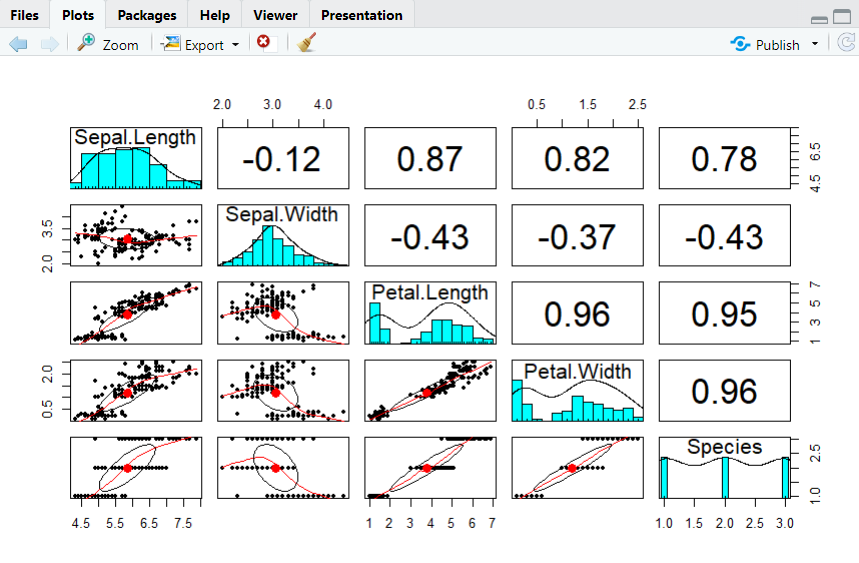
5) 핵심함수
(1) 데이터 수집하기
| 함수 | 기능 |
|---|---|
| read.table() | TXT 파일 가져옴 |
| read.csv() | CSV 파일 가져옴 |
| read_excel() | 엑셀 파일 가져옴 |
| xmlToDateFrame() | XML 파일 가져옴 |
| fromJSON() | JSON 파일 가져옴 |
(2) 데이터 관측하기
| 함수 | 기능 |
|---|---|
| data() | R 내장 데이터 세트 확인 |
| str() | 데이터 구조 확인 |
| ncol() | df컬럼(열) 개수 확인 |
| nrow() | df관측치(행) 개수 확인 |
| dim() | df컬럼(열)의 개수와 행 개수 확인 |
| quantile() | 분위수 |
| var() | 분산 |
| sd() | 표준편차 |
| kurtosil() | 첨도 (psych 패키지) |
| skew() | 왜도 (psych 패키지) |
| freq() | 빈도 (psych 패키지) |
(3) 데이터 탐색하기
| 함수 | 기능 |
|---|---|
| barplot() | 막대 그래프 그려요. |
| hist() | 히스토그램 그려요. |
| boxplot() | 상자그림 그려요. |
| pie() | 파이차트 그려요. |
| stem() | 줄기 잎 그림 그려요. |
| plot() | 산점도 그려요. |
| pairs() | 산점도 행렬 그려요. |
| pairs.panel() | 산점도 행렬 그려요. (psych 패키지) |
6) 숙제
1) 기본 숙제 : p. 169의 iris 내장 데이터 세트의 데이터 구조 출력하고 인증하기
2) 추가 숙제 : p. 191 상자 그림 그래프의 각 요약 값 정리하기