
1. 언어별 메모리 구조 비교
| Python | Java | C |
|---|---|---|
| 객체 지향 | 객체 지향 | 절차 지향 |
| 모든 것이 PyObject (객체) | 클래스만 객체 | 변수, 포인터 중심 |
| 객체 = Heap에 저장 | 객체명 = Heap, 내부 데이터 = Stack | 변수 = Stack, 메모리 관리 직접 |
| 타입·메모리 크기 생성 순간 고정 | - | - |
| 리스트 크기 초과 시 새로 메모리 할당 후 주소 복사 | - | - |
2. Python의 특징과 장점
📌 1) 메모리 관리가 자동이다
C는 malloc/free로 직접 관리
Python은 내부적으로 참조 카운트 기반으로 자동 관리
개발자가 신경 쓸 필요 없이 Garbage Collector가 정리해줌
참조 카운트란?
파이썬 객체마다 "참조 카운트"라는 숫자가 붙어있어.
그 객체가 몇 군데에서 쓰이고 있는지를 알려주는 숫자야.ex
a = [1, 2, 3]→ 리스트 객체 참조 카운트 1
b = a→ 같은 객체 참조하니까 참조 카운트 2로 증가
del a→ 참조 카운트 1로 감소
del b→ 참조 카운트 0 → ✅ 메모리에서 제거(Garbage Collection)
Garbage Collector란?
파이썬의 기본 메모리 관리 방식은 참조 카운트 기반
근데 순환 참조(자기 자신을 참조하는 구조) 같은 케이스는 참조 카운트로 해결 불가능
그래서 파이썬도 Garbage Collector 내장하고 있어서 주기적으로 순환 참조 같은 거 찾아서 정리해줘
📌 2) 리스트는 다양한 타입 저장 가능
내부적으로 "메모리 주소를 저장하는 배열" 구조
그래서 리스트 안에 int, str, list 등 다양한 타입 저장 가능
But. 리스트의 실제 데이터는 메모리 상에 순차적이지 않을 수도 있다.
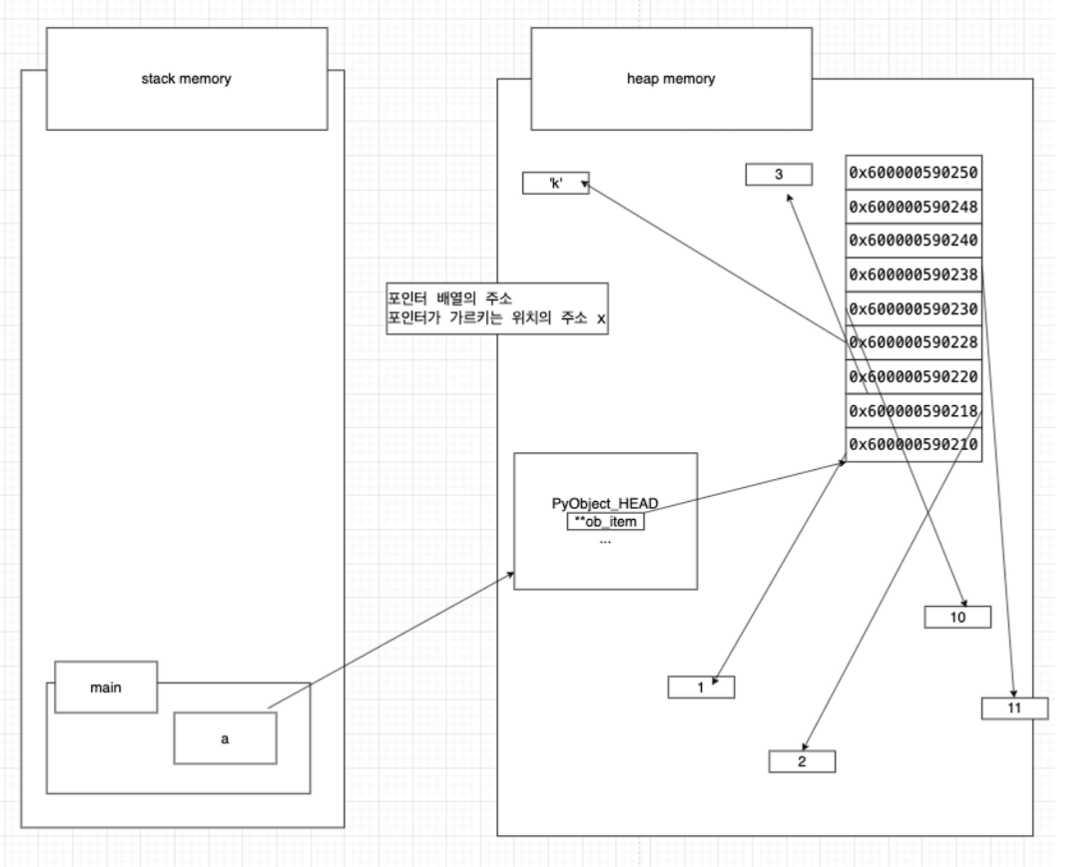
a = [1, 2, 10, 11, 'k', 3]
- a는 리스트 이름이고, 이는 스택 메모리(stack) 상에서 이름만 가지고 있어요.
- 리스트 자체(객체)는 힙 메모리(heap) 에 생성되며, PyObject_HEAD, *ob_item 등의 내부 구조를 가짐.
- ob_item은 실제 원소들이 저장된 포인터 배열을 가리킵니다.
- 이 포인터 배열은 각각의 요소(1, 2, 10, 'k', 3, 11 등)의 메모리 주소를 담고 있어요.
- a[0]은 1 객체의 주소를, a[1]은 2 객체의 주소를 가리키는 식으로 구성됨.
3. "모든 것이 객체"라서 좋은 점은?
- 변수, 숫자, 함수, 심지어 클래스까지 전부 PyObject
메서드도 달려있고 속성도 가짐 - 파이썬스럽게 (pythonic) 코딩 가능
🎯Mini Quiz
아래 코드 중 무엇이 더 효율적인가요?
# 1번
if A != True:
print('A is not true')
# 2번
if not A:
print('A is not true')정답 : 2번 처럼 쓰는 게 훨씬 pythonic하고 효율적
내부적으로 이렇게 돌아감
1번 코드
- A가 True와 같은지 먼저 비교 연산을 수행
- PyObject_Compare 같은 무거운 함수 호출 발생
/* 1번 */ PyObject *T = Py_True; Py_INCREF(T); PyObject *R = PyObject_Compare(A, T, Py_NE); Py_DECREF(T); if (PyObject_IsTrue(R)) { PyObject_Print(xxx); } Py_DECREF(R);
2번 코드
- A의 진위값만 체크
- 조건 검사 하나로 끝남 (비교 연산 자체가 필요 없음)
- PyObject_Not 호출 → 훨씬 가볍고 빠름
/* 2번 */ if (PyObject_Not(A)) { PyObject_Print(xxx); }

낭비하지마 네 시간은 은행🐰