0. 개요
본 팀은 대학교 강의계획서에서 텍스트를 읽어 일정, 과제, 평가 방식 등을 정리하고, 유저의 어플에 강의 일정을 자동으로 등록해주는 어플리케이션을 구현하고 있다.
대학생을 타겟으로 하는 프로젝트로, 학기 초에 강의계획서를 여러 번 확인하고 체크해야 하는 대학생들의 부담을 덜어줄 수 있으리라 기대된다.
- 본 블로그 글에서는 읽어들인 텍스트를 전처리하는 것을 구현해볼 예정이다.
1. 구현계획
강의계획서의 자연어를 DB에 저장할 수 있는 형식으로 요약하고 정제하기.
2-1. 추출한 문장을 정제하기.
2-2. 정제한 문장을 추출요약하기.
3-1. 정보값을 DB에 저장하기.
2. 구현할 내용
앞서 추출한 text를 전처리하여 자연어처리 하기 좋은 형태로 만들 것. 다만 강의계획서는 한국어와 영어 버전이 있기 때문에 둘을 전처리하는 파일을 따로 분리한다.
preprocessKor: 한국어 강의계획서의 내용을 전처리해주는 파이썬 코드.
preprocessEng: 영어 강의계획서의 내용을 전처리해주는 파이썬 코드.
3. 필요한 라이브러리
from pykospacing import Spacing
from nltk.tokenize import sent_tokenize
from hanspell import spell_checker
import re
4. input 및 output
preprocessKor:
input: 이전에 추출한 한글 text.
output: 정제된 한글 text
preprocessEng
input: 이전에 추출한 영어 text.
output: 정제된 영어 text
5. 과정
전처리란? 컴퓨터가 자연어를 처리하기 위해 자연어를 우선 정제하는 과정이다. 띄어쓰기, 조사, 동사의 과거형과 미래형 등 복잡한 구조를 가진 자연어를 원형으로 정제하는 과정이기에 이 과정이 정확할 수록 자연어 처리가 쉬워진다.
- 특수 문자를 제거한다. 한글로 인식하지 못하는 문자를 제거하는 과정이다.
punct = "/-.,#$%\()*+-/:;<=>@[\\]^_`{|}~" + '∞θ÷α•à−β∅³π‘₹´°£€\×™√²—–&'
punct_mapping = {"₹": "e", "´": "'", "°": "", "€": "e", "™": "tm", "√": " sqrt ", "×": "x", "²": "2", "—": "-", "–": "-", "’": "'", "_": "-", "`": "'", '“': '"', '”': '"', '“': '"', "£": "e", '∞': 'infinity', 'θ': 'theta', '÷': '/', 'α': 'alpha', '•': '.', 'à': 'a', '−': '-', 'β': 'beta', '∅': '', '³': '3', 'π': 'pi', }
def clean_punc(text, punct, mapping):
for p in mapping: text = text.replace(p, mapping[p])
for p in punct: text = text.replace(p, f' {p} ')
specials = {'\u200b': ' ', '…': ' ... ', '\ufeff': '', 'करना': '', 'है': ''}
for s in specials: text = text.replace(s, specials[s])
return text.strip()- 띄어쓰기를 교정한다. 띄어쓰기를 잘못하여 문맥이 달라질 수 있기에, 띄어쓰기가 정확히 되어있는지 교정해야 한다.
def space_kor(word_list):
new_sent_list = []
spacing_list = []
for txt in word_list:
new_sent_word = []
new_sent_word.append(txt[0])
new_sent_word.append(txt[1].replace(" ", ''))
new_sent_list.append(new_sent_word)
for txt in new_sent_list:
new_space_word = []
spacing = Spacing()
new_space_word.append(txt[0])
new_space_word.append(spacing(txt[1]))
spacing_list.append(new_space_word)
return spacing_list
- 불용어를 제거한다.
tokenizer = Okt()
def text_preprocessing(text,tokenizer):
stopwords = ['을', '를', '이', '가', '은', '는']
txt = re.sub('[^가-힣a-z]', ' ', text)
token = tokenizer.morphs(txt)
token = [t for t in token if t not in stopwords]
return token6. 결과
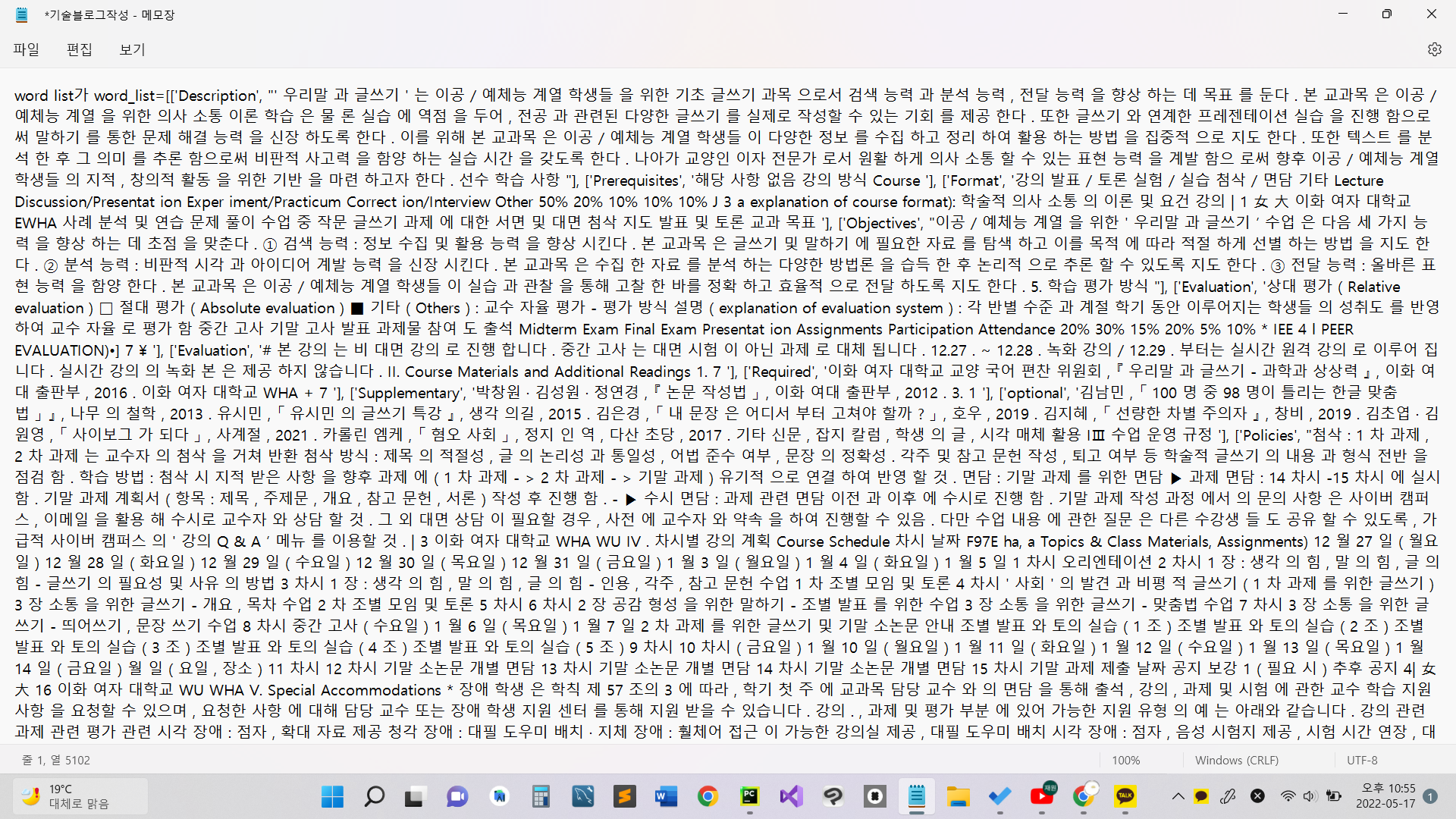
아래 사진은 이전에 추출한 텍스트이다.
해당 텍스트를 전처리할 경우.
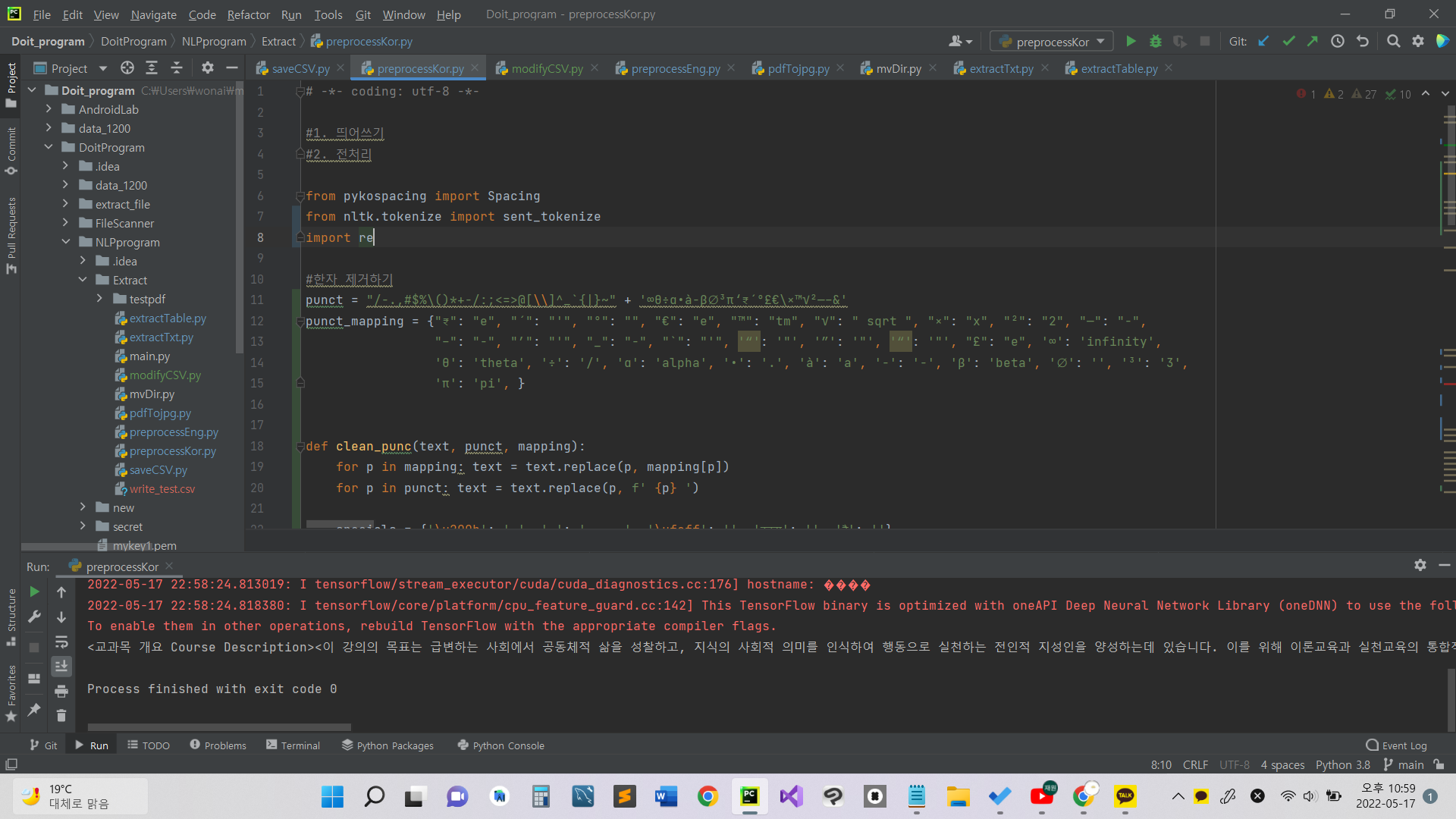
이전과 전처리한 후의 텍스트를 비교하면, 특수 언어가 제거되고 띄어쓰기가 정렬된 모습을 볼 수 있다.
- 강의계획서의 저작권 상 텍스트를 모두 보여줄 순 없습니다.
