
프로젝트 배경
개봉 예정 영화의 흥행을 예측할 수 있을까?
영화 산업은 흥행 여부를 가늠하기 매우 어려운 대표적인 고위험, 고수익 구조를 지니고 있습니다. 프로젝트를 시작하며 우리 팀은 "개봉 전에 수집할 수 있는 영화 자체의 기본 프로필 정보와, 대중의 실시간 관심도를 나타내는 외부 지표를 결합하면 흥행 성과를 신뢰성 있게 예측할 수 있을까?"라는 질문을 던졌습니다.
그리고 수동적인 관객수 예측에 그치지 않고, "개봉 전 데이터만으로 영화 순수 체급을 예측하고, 첫날 스크린 배정 규모에 따른 예상 관객 변화를 모의실험(Simulation)할 수 있는 데이터 기반 의사결정 보조 도구"를 개발하였습니다.
데이터 수집
1. 데이터 수집 파이프라인 및 연쇄 호출 구조
영화 정보와 대중의 사전 관심 지표를 결합하기 위해 공공 데이터와 포털 데이터를 수집하는 파이프라인을 구축하였습니다.
- 영화진흥위원회(KOBIS) Open API: 박스오피스 실적, 영화 상세 정보, 영화사 및 영화인 프로필 데이터 수집
- 네이버 검색어 트렌드 API (Naver Data Lab): 영화 개봉 전 30일 동안의 대중 상대 검색량 데이터 수집
API 호출 제한과 데이터 정합성을 보장하기 위해 다음과 같은 단계별 연쇄 호출(Cascade Request) 구조를 설계하여 수집을 진행하였습니다.
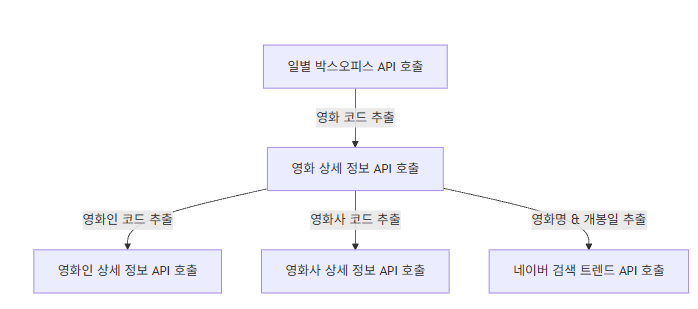
- 1단계: 일별 박스오피스 API를 호출하여 수집 기간 내 박스오피스에 1회 이상 진입한 이력이 있는 영화의 고유 코드(
movie_cd) 리스트를 추출하고 중복을 제거합니다. - 2단계: 추출된 영화 코드를 기반으로 영화 상세 정보 API를 호출하여 장르, 런타임, 관람등급 등 기본 정보와 해당 작품에 참여한 인물(감독/배우) 및 참여 회사(제작/배급사) 코드를 확인합니다.
- 3단계: 수집된 인물 및 회사 코드를 활용하여 영화인 상세 API와 영화사 상세 API를 연계 호출하여 과거 참여 내역 데이터를 확보합니다.
- 4단계: 영화의 제목과 확정된 개봉일을 조합하여 개봉 전 30일간의 네이버 일별 상대 검색 지수를 확인하여 시계열 데이터를 적재합니다.
2. RDBMS 스키마 설계 및 데이터 정규화
수집된 JSON 데이터를 분석 및 피처 연산에 적합하도록 관계형 데이터베이스(MySQL) 형태로 정규화하여 설계하였습니다. 특히 감독/배우의 Star Power나 제작/배급사의 Brand Power와 같은 누적 흥행 지표는 과거 시점 기준으로 매번 계산되어야 하므로, 테이블 간의 무결성과 관계를 명확히 설계하는 데 초점을 맞추었습니다.
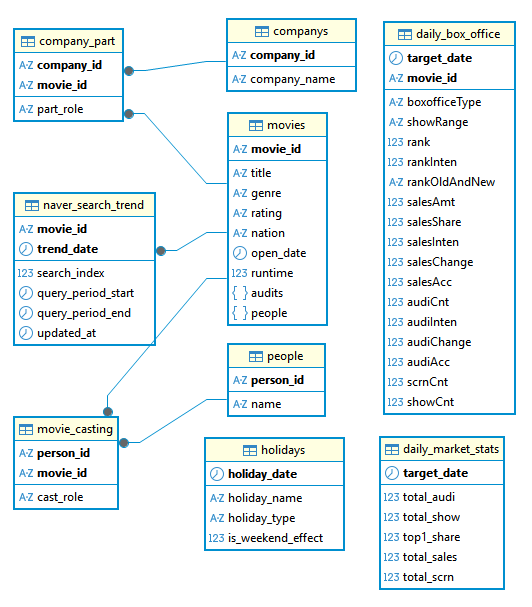
- 다대다(N:M) 관계의 해소:
영화(movies)와 인물(people), 영화와 회사(companys)는 다대다 관계에 놓여 있습니다. 이를 RDBMS 설계에 맞추어movie_casting및company_part라는 매핑 테이블로 분리하여 데이터 무결성을 충족하도록 정규화하였습니다. - 물리 ERD 구조:
3. 적재 규모 및 데이터 무결성 지표
2010년부터 2025년까지 총 16개년 범위에 걸쳐 적재를 진행하였습니다. RDBMS 내 각 테이블별 실제 적재 규모는 다음과 같습니다.
| 테이블명 | 주요 관리 데이터 | 적재 건수 (Rows) | ML 변수 활용처 |
|---|---|---|---|
movies | 장르, 국가, 등급, 상영시간, 개봉일 | 3,943 건 | 기본 독립변수 마스터 데이터 |
daily_box_office | 일별 순위, 관객수, 매출액, 스크린 수 | 58,440 건 | 타겟 변수 (total_audience) 추출원 |
daily_market_stats | 일자별 극장 총 관객수, 1위 점유율 | 5,844 건 | 개봉일 기준 외부 시장 경쟁도 지표 |
people | 배우 및 감독 인적 프로필 | 18,279 건 | 영화인 고유 식별 및 매핑 |
movie_casting | 영화-영화인 간 캐스팅 및 역할 매핑 | 50,575 건 | 과거 흥행 기여도를 산출하는 Star Power 피처 생성원 |
companys | 제작사 및 배급사 고유 정보 | 1,314 건 | 영화사 식별 |
company_part | 영화-영화사 간 제작/배급/수입 역할 매핑 | 6,966 건 | 유통력을 산출하는 Brand Power 피처 생성원 |
naver_search_trend | 개봉일 이전 30일간의 상대 검색 지수 | 83,575 건 | 사전 검색 관심도를 추적하는 피처 생성원 |
holidays | 법정 공휴일 및 연휴 정보 | 204 건 | 시즌성 및 연휴 영향 피처 생성원 |
4. 협업 및 데이터 재현성을 위한 마이그레이션 규칙
팀 프로젝트 수행 시 개별 팀원의 로컬 개발 환경에서 동일한 데이터베이스 구조와 기초 데이터를 무결하게 동기화하는 것은 중요한 과제입니다. 우리 팀은 DB 환경 불일치 문제를 방지하고 수집 파이프라인의 안전성을 위해 다음과 같은 장치와 규칙을 마련하였습니다.
- 자동화 셸 스크립트(
migrate.sh) 개발 및 도입 배경
- 파이썬 기반의 데이터베이스 마이그레이션 도구(예: Alembic 등)를 도입하는 대신, 로컬 시스템이나 Docker 환경에서 기본적으로 사용 가능한 표준 SQL 파일과 경량 셸 스크립트(
migrate.sh)의 결합을 채택하였습니다. - 이를 통해 팀원들이 파이썬 마이그레이션 라이브러리의 독자적인 문법과 가상환경 패키지 의존성을 추가로 학습해야 하는 장벽을 제거하였으며, 누구나 터미널 명령어 한 줄로 동일한 개발 환경을 구축할 수 있도록 지원하였습니다.
.env파일에 선언된 공통 환경 변수 정보를 스크립트가 파싱하여 터미널 명령어 한 줄로 DB 스키마 구축(--step=1)과 공통 기초 데이터 적재(--step=2)를 단계적으로 제어할 수 있도록 자동화하였습니다.
- 데이터 무손실 복원 및 슬라이싱 수집 규칙
- 데이터 분할 백업 규칙: 대량 데이터를 단번에 다룰 시 발생하는 네트워크 부하와 수집 불안정성을 완화하기 위해 3개년 범위(약 1,000건 단위)로 조각내어 데이터를 개별 파일로 분리 수집하는 환경 구축 가이드를
data/db/README.md에 명시하였습니다. - 데이터 버전 관리 규칙:
mysqldump를 통해 추출된 백업본을 병합할 때 발생할 수 있는 스키마 충돌을 방지하기 위해, 각자 수집한 데이터를01_movies.sql,02_daily_box_office.sql과 같이 실행 순서에 맞춰 넘버링(Naming Convention)하여 관리했습니다. - 멱등성(Idempotency) 보장: 동일 데이터를 중복으로 밀어 넣거나 수집이 재개되더라도 DB 키 충돌로 실패하지 않도록
ON DUPLICATE KEY UPDATE전략을 기본 쿼리로 설정하여 데이터 적재 프로세스의 안전성을 공고히 하였습니다.
피처 엔지니어링
1. 데이터 누수 통제 원칙과 타겟 선정 이유
- 데이터 누수(Data Leakage) 차단
우리 모델은 '개봉일 이전 확정된 정보만으로 미래의 흥행을 예측한다' 는 비즈니스 제약을 엄격히 준수합니다. 개봉 이후에나 알 수 있는 첫 주 스크린 수, 실제 상영 횟수, 초기 평점 등은 학습 변수에서 배제하였습니다. - 타겟 피처 선정 및 변환 이유
타겟 변수는 최종 누적 관객수(total_audience)입니다. 관객 수는 실질적인 수요 규모를 가장 직관적으로 반영하는 표준 지표이기에 타겟으로 결정하였습니다. 다만, 최종 관객수 원본 데이터를 그대로 학습에 사용할 경우 모델이 왜곡되는 문제가 발생합니다. 영화 흥행 데이터는 소수의 대작 영화가 관객을 독점하고 대다수 영화는 하위 구간에 머무르는 극단적인 우편향(Right-Skewed) 롱테일 분포를 보이기 때문입니다.
-log_audience(회귀 타겟): 원본 관객수에 로그 변환(np.log1p)을 적용하여 스케일을 압축하였습니다. 이를 통해 이상치에 의해 오차 계산이 지배당하는 모델 편향을 방지하고, 손실 함수가 모든 관객수 구간을 균형 있게 학습하도록 유도하였습니다.
2. 협업을 통한 피처 테이블의 점진적 고도화 과정
[v1 베이스라인 고정] ──> [모델별 개별 분담 학습]
──> [유의변수 개별 도출] ──> [v2 통합 피처 병합]
──> [v3 고도화 루프]1. 모델 역할 분담
- 팀원 A: Baseline ML 모델 (Linear, Ridge, Lasso, Random Forest 등)
- 팀원 B: Boosting ML 모델 (XGBoost, LightGBM, CatBoost 등)
- 팀원 C: 딥러닝 모델 (MLP 회귀 및 분류)
2. v1 피처 고정 및 동시 학습
모든 모델이 동일한 환경에서 평가받고 모델별 베이스라인 기준점을 명확히 수립할 수 있도록 초기 21개 독립변수로 구성된 feature_table_v1.csv를 생성 및 고정하였습니다. 모든 팀원은 이 v1 데이터셋을 이용해 각자 맡은 모델을 기본 학습시켰습니다.
3. 개별 피처 엔지니어링 및 유의 변수 도출
각자 모델을 기동하며 오차 패턴을 시각화하고 피처 기여도(Feature Importance) 분석을 수행하였습니다.
- 선형 모델 담당자는 다중공선성(Multicollinearity) 문제를 식별하여 변수 축소 필요성을 도출하였습니다.
- 트리 및 딥러닝 담당자는 신인/영세 데이터의
0값에 의한 학습 왜곡과 대중 관심 지표의 부재로 인한 성능 한계를 규명하였습니다.
4. v2 통합 피처 병합 및 순환 피처 고도화 (v3)
개별적으로 유의함이 확인된 피처 개선 기법(네이버 검색 Buzz 통계, cold-start 방지 중위값 보정, 장르 타겟 인코딩, 극장 외생 환경 변수 등)들을 단일 피처 테이블로 취합하여 v2 피처 테이블을 병합해 냈습니다. 이후 동일한 과정을 반복하여 v3 피처 테이블을 최종 완성하였습니다.
3. 피처 테이블 버전별 요약
| 버전 | 주요 변경점 요약 | 피처 수 | R² 성능 추이 (CatBoost 기준) |
|---|---|---|---|
| v1 | - 식별자 2개, 타겟 3개, 독립변수 21개 결합 - 감독/배우/배급사의 과거 단순 평균 및 단순 편수 정보 수집 - 범주형 변수의 순서형 인코딩 적용 | 21개 | 0.3802 |
| v2 | - 다중공선성 피처 7종 제거 및 원-핫 인코딩 전환 - 신인/영세 결측값 Non-Zero Median 대체 및 지시 변수( is_new_*) 추가- 네이버 트렌드 Buzz 변수 4종 도입 (2016년 이후 데이터로 필터링) - 외생 변수 도입 ( ticket_price_pre30, is_covid_period, is_peak_season) | 26개 | 0.5342 |
| v3 | - 개봉일 기준 과거 장르 평균 관객수의 타겟 인코딩 적용 - 2-Stage 시뮬레이션을 위한 데이터 결합 및 피처 정제 완료 | 26개 | 0.5633 |
모델링 및 성능 평가
1. 검증 방법론: 시계열 분할의 필요성
우리의 목적은 미래 시점의 영화 관객수를 예측하는 것입니다. 무작위 분할(Random Split, shuffle=True) 방식을 적용하면 미래 시점의 극장 관람료 인플레이션, 코로나19 등 거시적인 극장 시장 정보가 과거 시점의 데이터 학습에 영향을 미치는 데이터 누수가 발생합니다.
이러한 성능 과대평가 현상을 규명하기 위해 동일한 피처 테이블과 모델 조건 하에서 데이터 분할 방식에 따른 성능 변화를 비교 실험하였습니다.
- 무작위 랜덤 분할 (
shuffle=True): RandomForest R² = 0.6645 - 시계열 분할 (
shuffle=False): RandomForest R² = 0.4904
데이터 분할 방식의 차이만으로 R² 지표가 약 0.17 수준으로 다르게 도출되었습니다. 무작위 분할의 높은 수치는 실제 배포 환경에서 재현되지 않는 가공의 성능이므로, 본 프로젝트는 데이터를 개봉일 순으로 정렬한 뒤 과거 80% 데이터를 학습(Train) 세트, 최신 20% 데이터를 평가(Test) 세트로 격리하는 시계열 분할 방식을 적용하였습니다.
2. 개별 모델 학습 및 성능 비교
피처 테이블 v3 데이터를 기반으로 단일 알고리즘 5종에 대해 하이퍼파라미터 최적화(Optuna 활용)를 적용하여 시계열 분할 테스트 세트에서 성능을 측정하였습니다. 평가 지표로는 결정계수()와 평균제곱근오차(RMSE)를 활용하였습니다.
| 모델 구분 | 테스트 R² | 테스트 RMSE | 모델별 특징 및 평가 요약 |
|---|---|---|---|
| RandomForest (단일) | 0.4904 | 1.4548 | 과적합 제어 수준이 낮고 시계열 변화에 가장 민감하여 낮은 일반화 성능 기록 |
| MLP (단일 딥러닝) | 0.5069 | 1.4310 | 층을 깊게 설계하여 학습을 시도하였으나 정형 데이터 특성상 성능 향상이 제한적임 |
| LightGBM (단일) | 0.5180 | 1.4148 | 학습 속도가 빠르나 데이터 개수가 아주 많지 않은 시계열 분할 환경에서 상대적으로 오버피팅 발생 |
| XGBoost (단일) | 0.5517 | 1.3645 | 세분화된 트리 성장을 통해 잔차 패턴 파악에 우수한 예측력 달성 |
| CatBoost (단일) | 0.5633 | 1.3467 | ordered boosting 기법을 통해 오버피팅을 억제하여 단일 모델 기준 가장 안정적인 일반화 성능 기록 |
3. 최적 앙상블 조합 도출 (CatBoost + XGBoost Stacking)
단일 모델의 한계를 극복하고 모델 간 예측 편차를 상호 보완하기 위해 앙상블 학습을 설계하였습니다.
OOF(Out-of-Fold) 예측값 활용
- 앙상블 학습 시 발생할 수 있는 타겟 누수(Target Leakage) 문제를 통제하기 위해, 학습 세트 내에서 5-Fold 교차 검증을 통해 구한 OOF(Out-of-Fold) 예측 벡터를 학습 데이터로 구축하였습니다.
쉽게 말해, 모델이 이미 정답을 알고 있는 데이터셋을 다시 예측하여 최종 모델을 기만하는 과적합을 방지하기 위해, 학습 과정에서 철저히 격리되어 '한 번도 보지 못한 데이터'만 예측한 결괏값(OOF)을 모아 최종 앙상블의 입력 데이터로 활용하였습니다.
노이즈 모델 배제 및 가중 평균 설정
- 모델 제외: 시계열 예측 성능이 떨어지는 일부 모델(RandomForest, MLP 등)이 포함되자, 오히려 전체 성능이 깎이는 '하향 평준화' 현상이 발생하여 제거하였습니다.
- 최적의 시너지 비율 (8:2): 가중치 그리드 서치를 통해 0.1 단위로 조합을 테스트한 결과, CatBoost 80% + XGBoost 20%의 가중 평균 모델에서 좋은 시너지가 발생했습니다.
- 최종 앙상블 성능 (v3 Test): , (단일 최고 모델 대비 오차 추가 감소)
최종 모델 선정 사유
-
CatBoost의 안정성: 우리 데이터에는 영화 장르, 관람 등급 등 범주형(Categorical) 피처가 많았습니다. 범주형 변수 처리에 특화되고 오버피팅 제어력이 뛰어난 CatBoost가 전체 모형의 단단한 뼈대(80%)를 잡으면서 예측의 흔들림(분산)을 최소화했습니다.
-
XGBoost의 보완성: CatBoost가 대세적인 흐름을 안정적으로 잡아준다면, XGBoost는 CatBoost가 놓친 오차를 20%의 비중으로 깎아내는 역할을 했습니다. 결과적으로 서로의 약점을 보완하도록 했습니다.
2-Stage 시뮬레이터 설계
1. 배급 스케일 변수 활용 가능성
개봉 첫날 배정되는 스크린 수(scrnCnt_day1)와 상영 횟수(showCnt_day1)는 누적 관객수에 직접적인 영향을 미치는 주요 변수입니다. 그러나 이는 다른 독립변수(개봉 전 스타파워 등)들에 의해 결정되는 내생성(Endogeneity)을 안고 있습니다.
저는 그럼에도 이 변수들을 사용하고 싶었고 그러기 위해 영화 고유의 매력도와 배급 스케일의 영향을 분리하는 독립적인 2단계 연계 구조를 고안하였습니다.
2. 2-Stage 연계 파이프라인 구조
영화 콘텐츠의 고유 모객력과 상영관 확보 전략의 영향을 논리적으로 격리하기 위해 다음과 같이 2단계 추론 구조를 정립하였습니다.
[Stage 1: 흥행 잠재력 평가]
- 입력 피처: 개봉 전 영화 프로필, 검색 트렌드, 외생 변수 등 (상영관 변수 전면 배제)
- 출력 피처: 영화 고유의 잠재 흥행력 점수 (pred_potential)
│
▼ (전달)
[Stage 2: 배급 스케일 보정 및 시뮬레이션]
- 입력 피처: pred_potential + 제어 변수 (log_scrnCnt_day1, log_showCnt_day1)
- 출력 피처: 최종 예상 누적 관객수 (log_audience)- Stage 1 (콘텐츠 잠재력): 상영관 변수 없이 순수 개봉 전 정보만 학습하여 영화가 시장에서 가질 수 있는 체급과 고유 모객 가치를 평가하여
pred_potential점수를 도출합니다. - Stage 2 (배급 보정 시뮬레이터): Stage 1의 예측값과 사용자가 제어하는 스크린 및 상영 수(로그 변환 적용)의 조합만을 입력받아 최종 예상 관객수를 연산합니다.
이 구조 하에서 모델은 "영화의 기본 체급이 주어졌을 때, 첫날 배급 지원을 늘리거나 줄이면 관객 반응이 어떻게 변화하는가"를 인과적으로 모사할 수 있게 되었습니다.
3. 단조 증가 제약(Monotonic Constraints) 조건의 적용
시뮬레이션 환경에서 일반적인 머신러닝 알고리즘을 사용하면 국소적인 데이터 분포의 한계로 인해 "스크린 수를 늘렸는데 최종 관객 예측치가 소폭 감소하는" 수학적 역설이 발생할 수 있습니다.
의사결정 보조 도구로서의 논리성을 확보하기 위해, Stage 2 XGBoost 모델 학습 시 단조 증가 제약(Monotonic Constraints) 조건을 적용하였습니다.
- 수학적 보장:
pred_potential,log_scrnCnt_day1,log_showCnt_day1중 어떤 변수의 수치가 상승하더라도 최종 관객수 예측값은 감소하지 않고 반드시 유지되거나 증가하도록 제약을 부과하였습니다. - 결과: 스크린 수가 일정 수준에 도달함에 따라 관객 동원 증가 효율이 점진적으로 둔화되는 비선형 한계 효용 반응 곡선을 도출하면서도 논리적 오작동 가능성을 차단하였습니다.
시뮬레이터 연계 성능 결과 (테스트 세트)
최종 연계 평가 결과, Stage 2 시뮬레이터 모델은 R² = 0.6682, RMSE = 1.1739의 향상된 정확도를 기록하였습니다.
Stage 2 모델 내의 변수 중요도는 콘텐츠 잠재 흥행력 점수(pred_potential)가 85.06%로 모델의 중심을 잡고, 스크린 수(log_scrnCnt_day1, 5.53%)와 상영 횟수(log_showCnt_day1, 9.41%)가 보완적인 스케일 보정 역할을 수행하도록 안정적인 구조가 구축되었음을 입증하였습니다.
모델 실제 테스트 결과
1. 테스트 셋 준비 및 웹 데모 구현
- 2026년 테스트 데이터셋 구축:
편의를 위해 2026년 개봉 영화들의 메타데이터와 사전 네이버 검색량 추이를 동일하게 적용하여v3규격의 입력 피처 테이블(feature_table_2026.csv)을 구축하였습니다. - Streamlit 시뮬레이터 연동:
웹 UI 환경에서 영화를 선택하면 해당 영화의v3피처를 기반으로 Stage 1 콘텐츠 잠재력을 실시간 평가하고, 사용자의 스크린 조절값에 따라 Stage 2 누적 관객 예측치와 Elbow Point(투자 대비 최적 배급 효율 구간)를 동적으로 연산하여 시각화하도록 데모를 구현하였습니다.
2. 2026년 개봉작 3편에 대한 실제 시뮬레이션 결과

- Stage 1 (순수 콘텐츠 잠재력): 약 163만 명
- Stage 2 (실제 배급 반영 예측): 약 358만 명 (실제 첫날 1,964개 스크린 및 8,116회 상영 기준)
- 의사결정 보조 및 Elbow Point 추천:
모델이 추천하는 가장 자원 효율적인 스크린 구간은 2,291~2,800개로 산출되었습니다. 이 구간을 초과하는 대규모 상영관 추가 확보 전략은 스크린당 관객 유입 증가 효율이 크게 정체되는 양상을 나타냈습니다.

- Stage 1 (순수 콘텐츠 잠재력): 약 21만 명 (중간 이하 체급)
- Stage 2 (실제 배급 반영 예측): 약 173만 명 (실제 첫날 1,734개 스크린 및 6,157회 상영 기준)
- 의사결정 보조 및 Elbow Point 추천:
외국 드라마 장르 특성상 스크린 확대에 따른 한계 효율 정체가 빠르게 시작되는 구조를 보입니다. 모델은 2,572~3,143개 구간을 스윗스팟으로 제시하였습니다.

- Stage 1 (순수 콘텐츠 잠재력): 약 148만 명
- Stage 2 (실제 배급 반영 예측): 약 347만 명 (실제 첫날 1,658개 스크린 및 6,932회 상영 기준)
- 실제 관객수 대비 오차율: -79.4% (실제 최종 관객수 약 1,688만 명)
- 모델 한계 분석:
실제 최종 관객수인 1,688만 명에 비해 모델이 크게 과소 예측하였습니다. 이는 개봉 전 정형 지표들만으로는 입소문과 극장 흥행 폭발로 인한 슈퍼스타 효과(Superstar Effect) 또는 극단적인 아웃라이어 흥행 사례를 완전히 포착하기 어렵다는 모델의 구조적인 한계를 명확하게 시사합니다. - Elbow Point 추천: 스크린 2,196~2,685개 구간이 최적의 효율 배정 범위로 계산되었습니다.
프로젝트 회고
그래도 1차 때 보다 더욱 더 소통하려고 했고 전체 진행 상황 파악 및 조율을 통해 팀원 모두 프로젝트에 잘 참여할 수 있도록 노력했습니다. 결과물에 매우 만족하며 재밌게 했던 프로젝트였습니다!
교훈
- 도메인 이해: 영화 흥행 성과는 대칭을 이루는 정규분포가 아닌 소수 대작이 독식하는 분포를 보입니다. 이러한 도메인 특성상 동일한 기준으로 모든 영화를 모델링하는 것은 불가능하며, 중소 체급/대작 영화 등으로 분류하여 다각화된 전략이 필요함을 느꼈습니다.
- 피처 협업 과정에서의 한계: 단일 피처 테이블만으로 모든 모델의 성능을 동시에 극대화하려 했던 방식은 각 알고리즘 고유의 특성을 제한하는 병목이 됨을 깨달았습니다. 각 알고리즘에 대한 공부가 부족하였고 소통이 부족하여 이것으 더 체감했던 것 같습니다.
- 2 stage의 실효성: 단순한 수치 예측 소프트웨어에 그치지 않고, 배급 실무 현장에서 직접 예산 배정과 스크린 수 시나리오를 검토할 수 있는 '실질적인 비즈니스 도구'를 구현해냈다는 점에서 가장 큰 기술적 보람을 느꼈습니다.
