머신러닝이란?
머신러닝(Machine Learning)은 인공지능(AI)의 한 분야로, 컴퓨터가 명시적인 프로그래밍 없이도 데이터를 학습하고 패턴을 분석하여 스스로 예측하거나 결정을 내리는 기술입니다. 머신러닝은 주로 대량의 데이터를 활용하며, 이 데이터를 기반으로 알고리즘이 학습합니다. 머신러닝은 이미지 및 음성 인식, 추천 시스템, 자율주행, 금융 사기 탐지 등 다양한 분야에서 활용되며, 특히 빅데이터와 결합되어 더욱 강력한 성능을 발휘합니다. 머신러닝의 핵심은 컴퓨터가 반복적인 학습 과정을 통해 점점 더 높은 정확도를 달성할 수 있도록 하는 데 있으며, 이는 기존의 프로그래밍 방식과 차별화되는 점입니다.
-> 똑똑한 인간의 뇌를 만드는 과정
CreateML이란?
참고
먼저 ML의 약자는 Machine Learning이다. CreateML은 앱에서 사용되는 모델을 머신러닝을 통해 만드는것이다. CreateML을 이용하게 되면 이미지 인식, 텍스트에서 값구하기등을 구현할 수 있게된다.
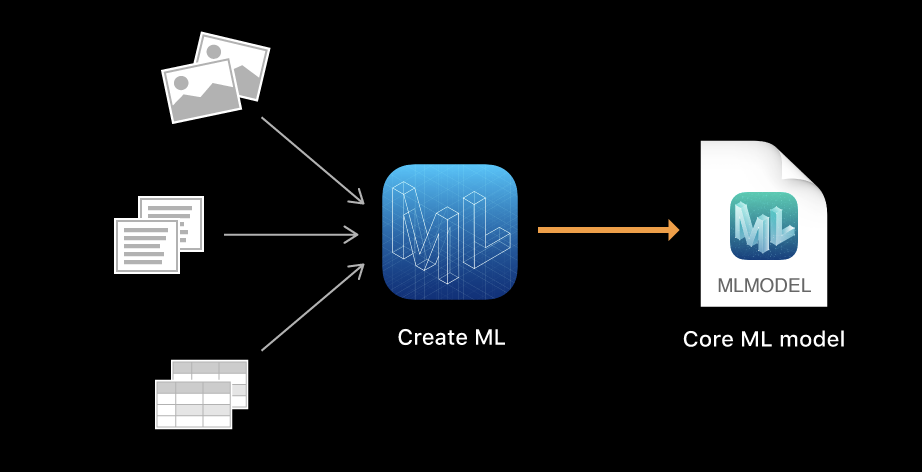
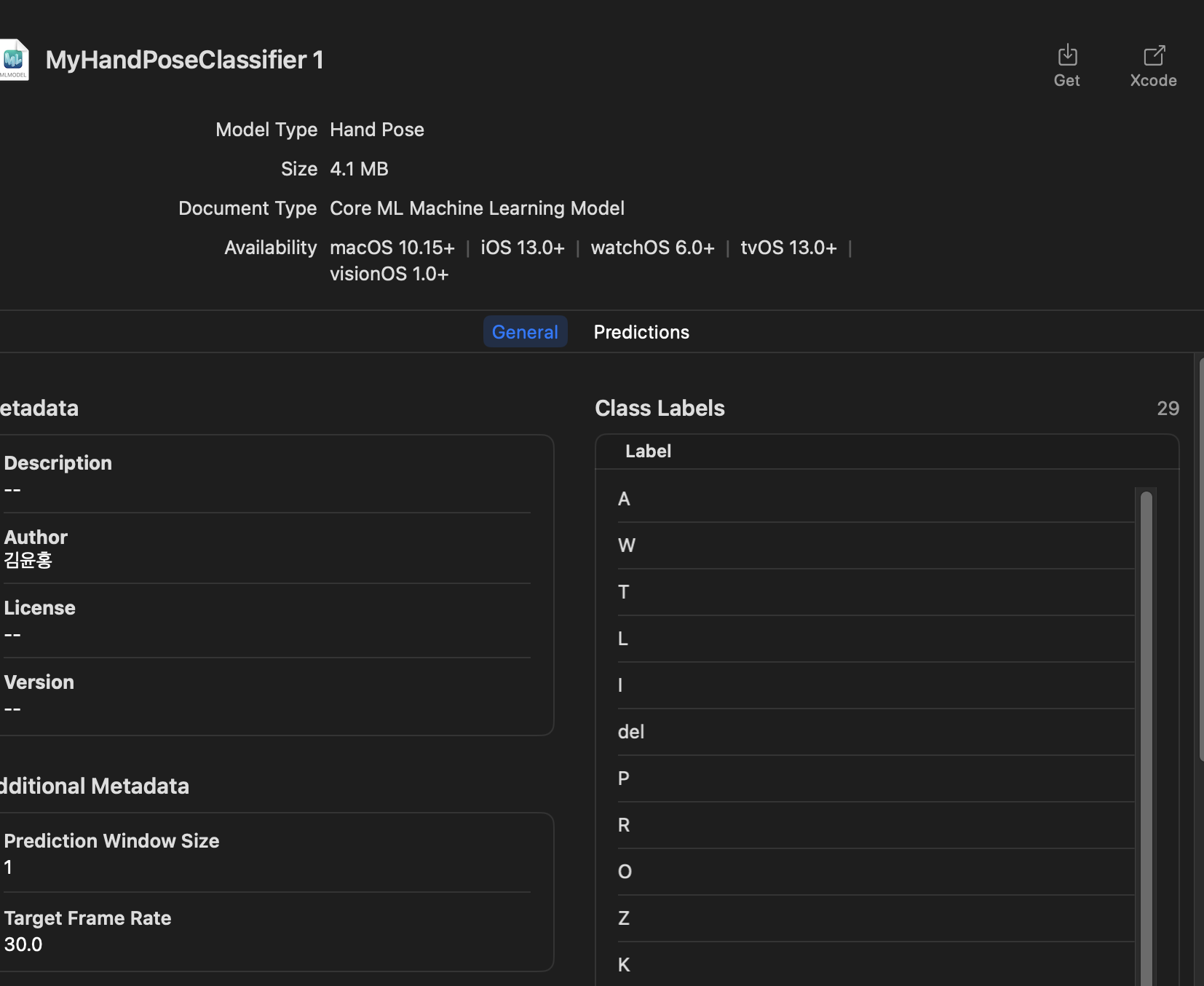
다양한 dataset을 바탕으로 모델을 학습시키면 CoreML모델이 나오게 된다.
예를 들어 다양한 강아지 사진들을 CreateML을 통해 학습을 시키면 학습된 CoreML모델이 나오게 된다. 아래 사진은 CreateML의 흐름을 나타낸 것이다.
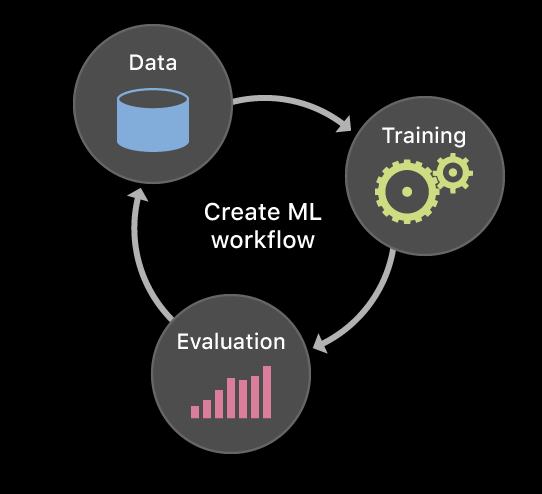
CreateML로 어떤 모델들을 만들 수 있을까?

CreateML로 만들수 있는 모델의 유형은 여러가지가 있는데 프로젝트의 목적에 맞게 선택하는게 좋을것 같다.
직접 만들어보기
CreateML을 Xcode상에서 만들기 위해서는 Xcode -> Open Developer Tool -> CreateML을 선택하면된다.
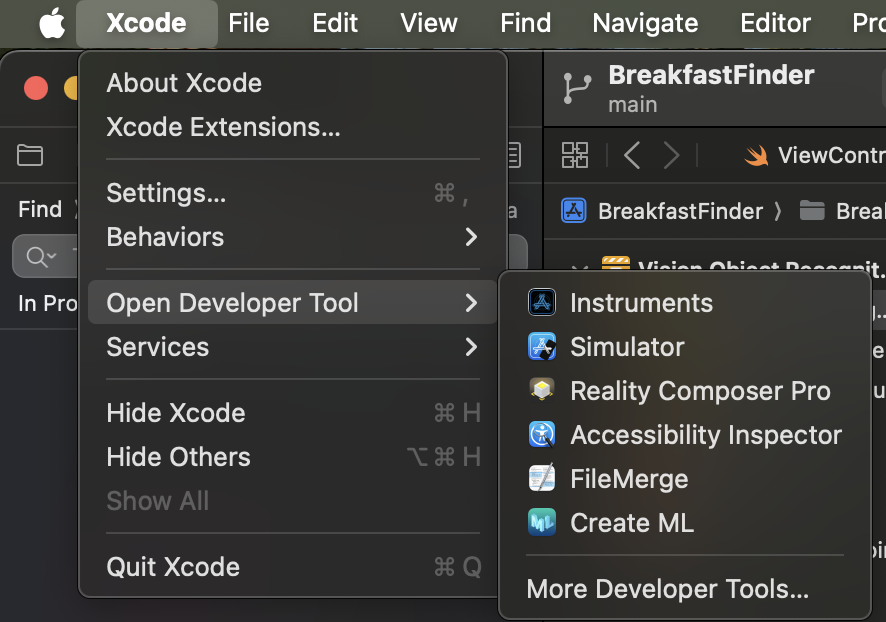
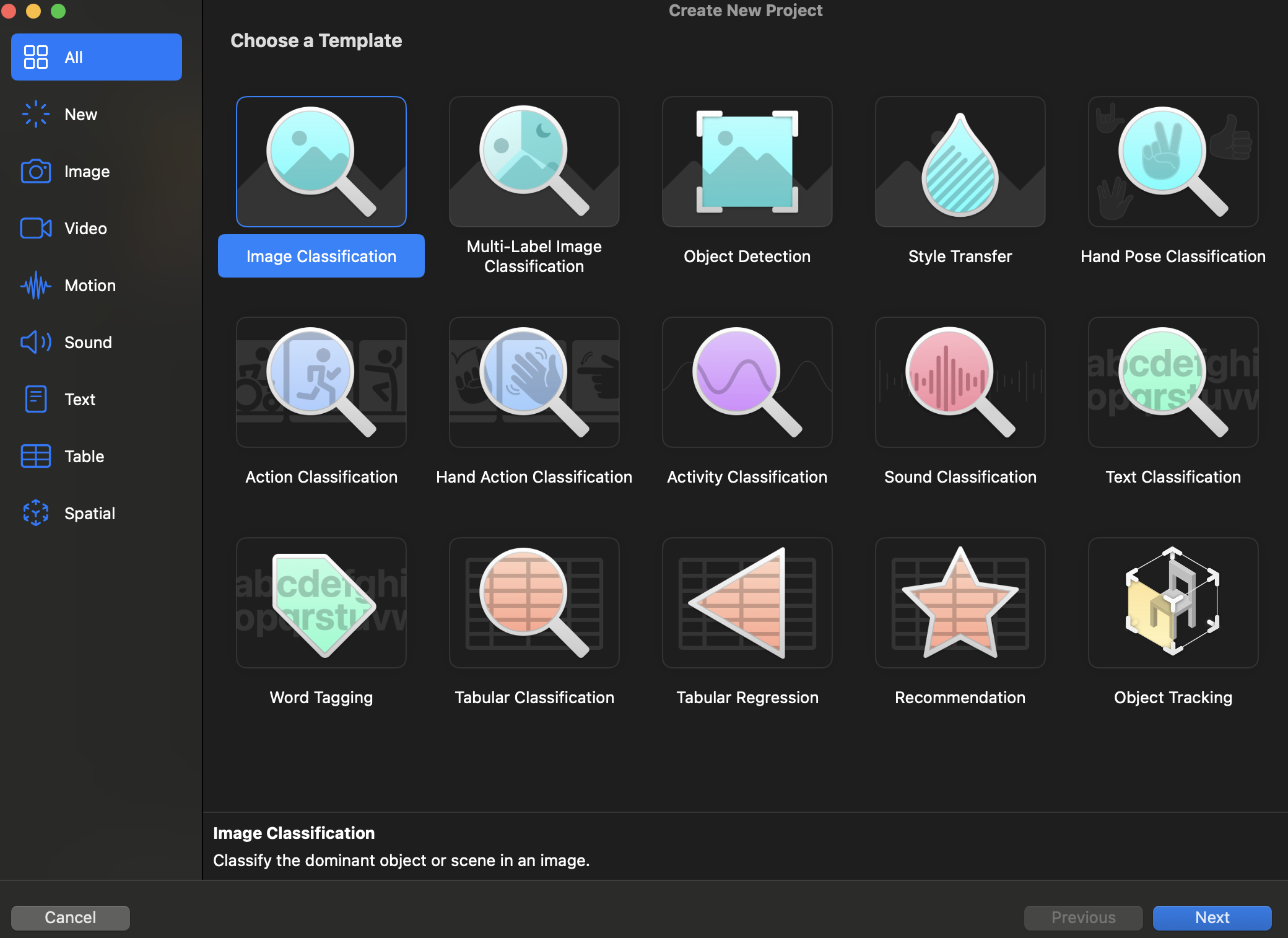
newDocument를 눌러 다음화면으로 넘어가게 되면 아래와 같이 많은 템플릿이 나오게 된다. 각각의 템플릿을 클릭하면 아래 설명이 나오니 참고해서 선택하면 될 것같다.
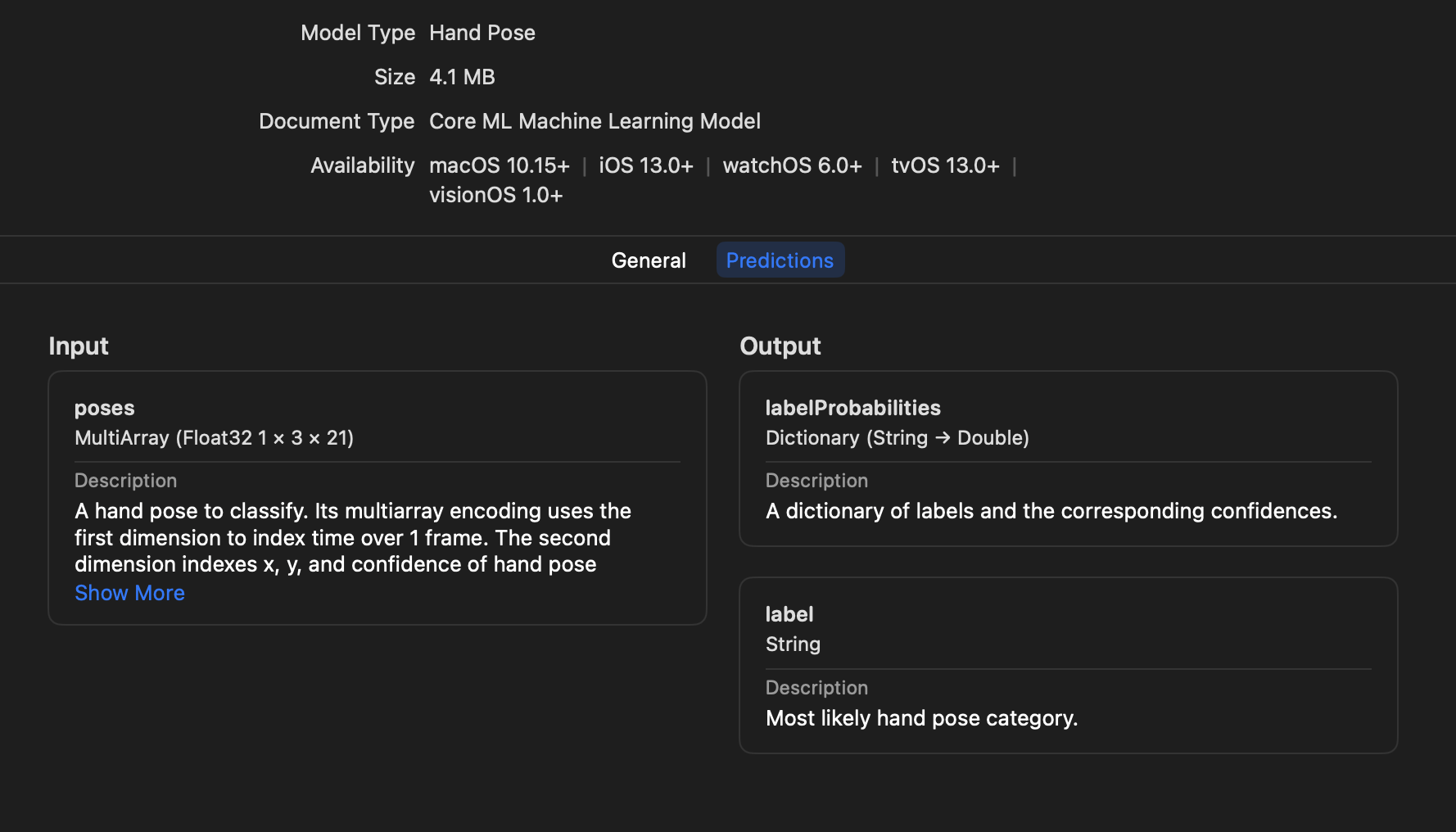
CoreML을 통해 결과를 확인하는 과정인 입력 -> 모델 판별 -> 출력 이라고 할 수 있다. 여기서 input과 output의 타입들을 잘 확인해서 어떻게 구현할지 고민하면서 선택을하게 되면 쉽게 사용할 수 있을 것 같다.
위의 예시대로 만들어 보면서 주의 사항 몇가지를 소개해보겠습니다.
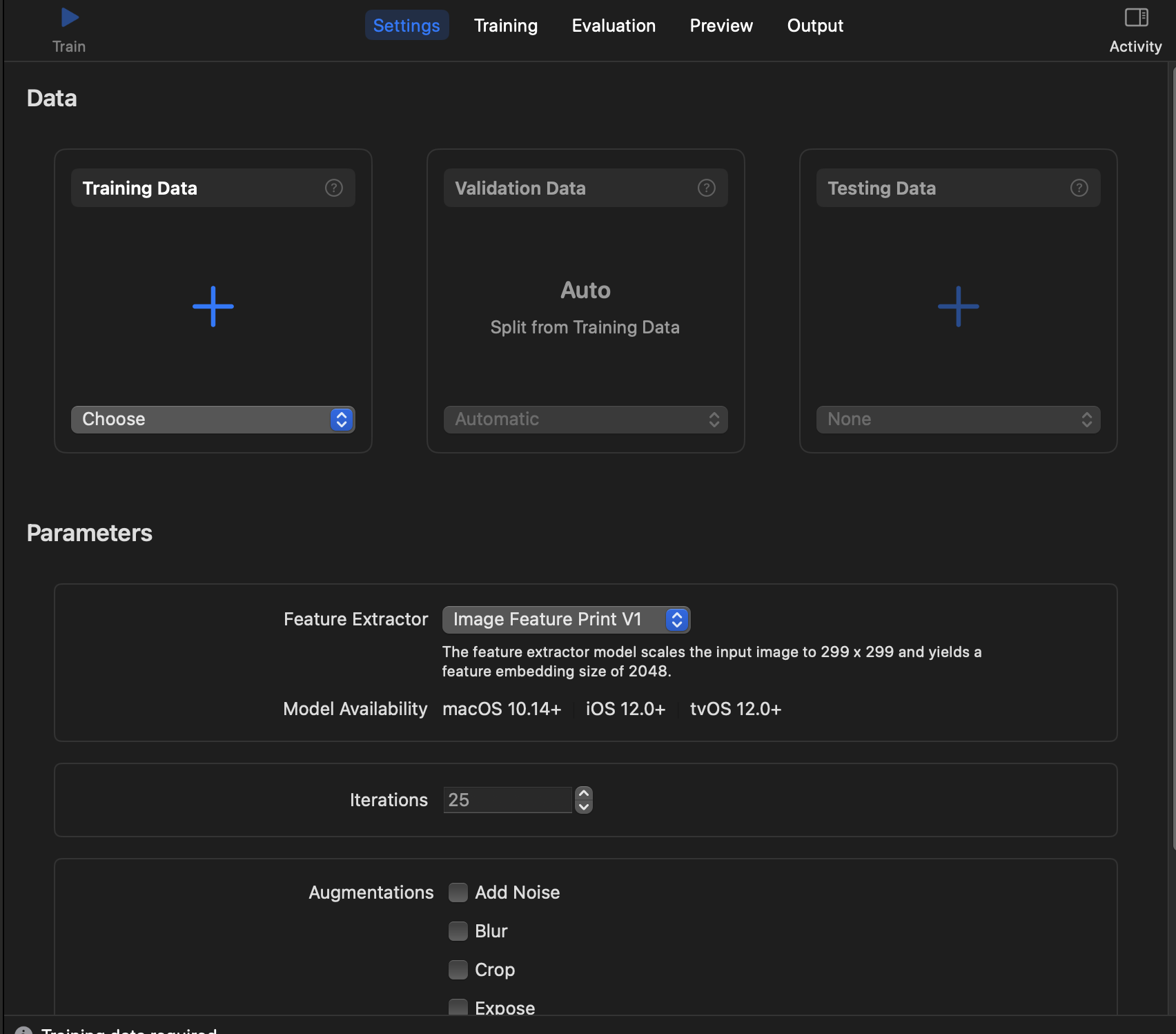
먼저 데이터를 넣는 부분입니다 training Data부분에 choose를 누르게 되면은 데이터의 폴더를 넣을 수 있는데 위의 링크 설명처럼 폴더 구조는 아래와 같아야합니다. 학습할 데이터를 넣고 나서 선택적으로 testData도 같이 넣을 수 있습니다.
학습시킬 데이터들을 찾고 싶다면 kaggle 사이트에 접속하셔서 많은 데이터들을 검색할 수 있습니다.

다음은 lterations 반복 횟수를 지정할 수 있습니다.
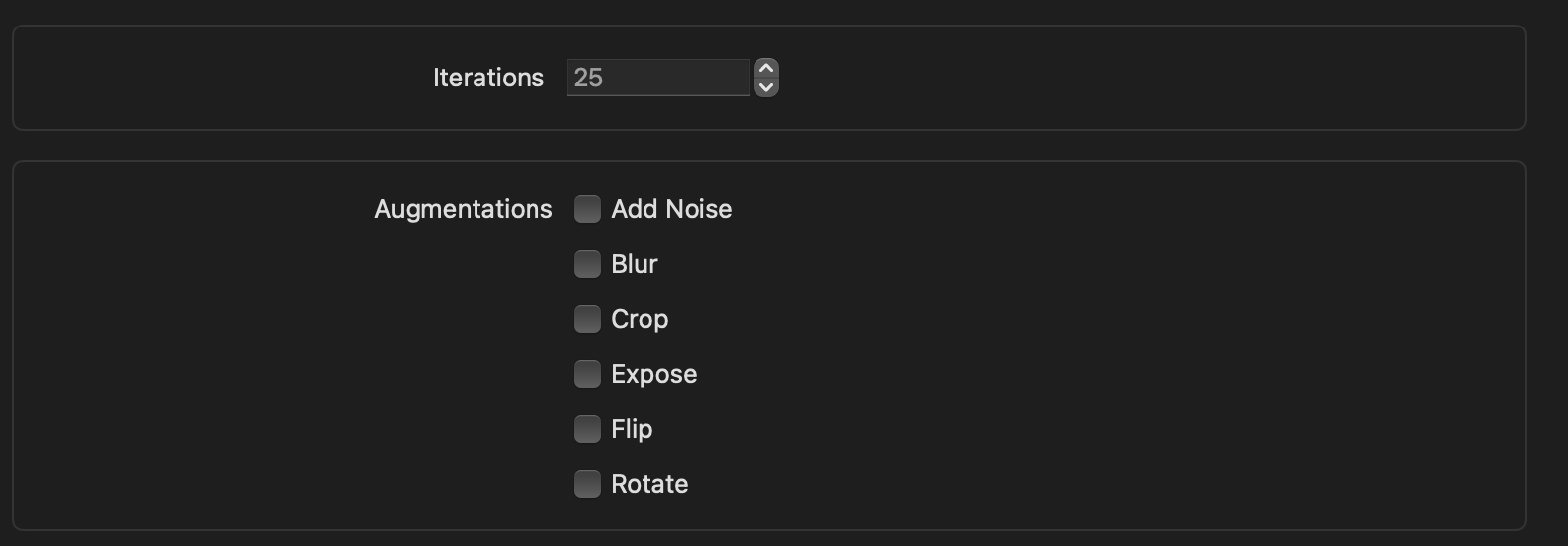
Augmentations 설정등을 통해서 다양한 변화등을 학습시킬 수 있습니다. Augmentations참고
각 데이터 세트의 이미지를 복사하여 추가 이미지를 수집하지 않고도 변환 또는 필터를 적용합니다.
다양한 상황을 가정해(노이즈가 있거나, 블러, 크롭 된 사진 등) 이미지 후처리를 한 후 학습을 진행해 구분 성능을 높입니다.
학습 시간이 굉장히 늘어나는 단점이 있으며, 이미지가 매우 많을 경우는 이미 이미지 수 자체가 그러한 상황이 반영되어 있을 확률이 높기 때문에 그대로 진행하는 것이 나을 수 있습니다.
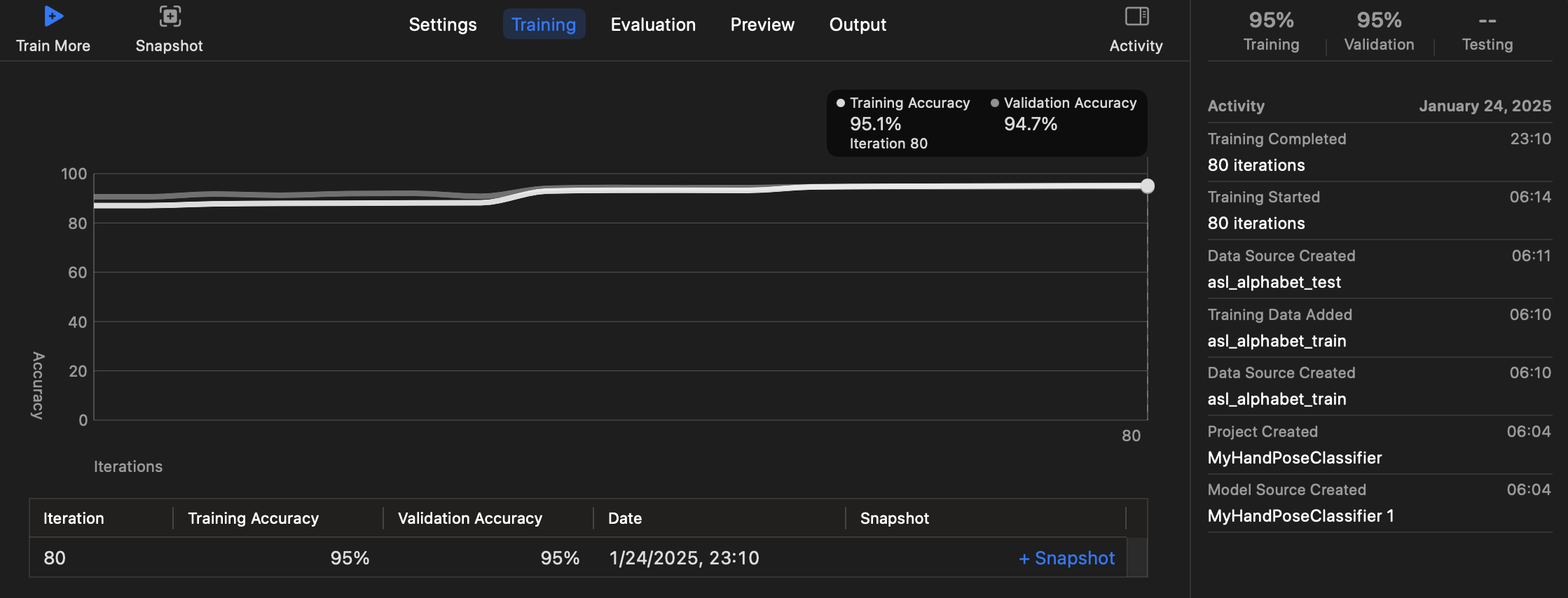
학습이 끝나고 나면 저는 87000개를 80번 반복을 돌렸더니 약 7시간 정도가 걸렸습니다..
이제 Trainig, Preview, Output탭을 살펴 보겠습니다.
학습 후 결과 살펴보기
Preview탭에서 이미지를 넣고 테스트를 해볼수 있습니다. 아래의 Y는 사진별로 분류된 Label값이 나오게 됩니다.
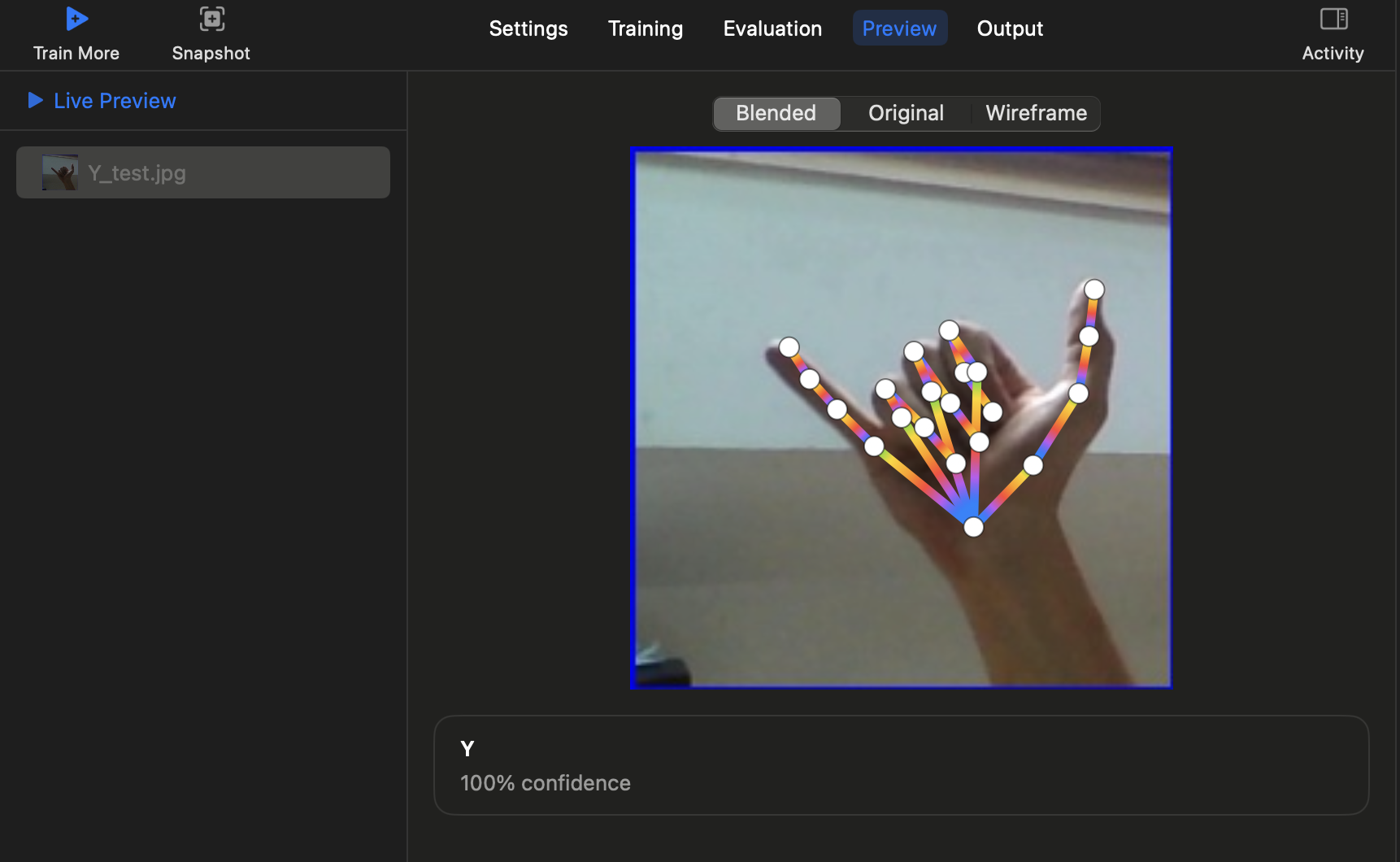
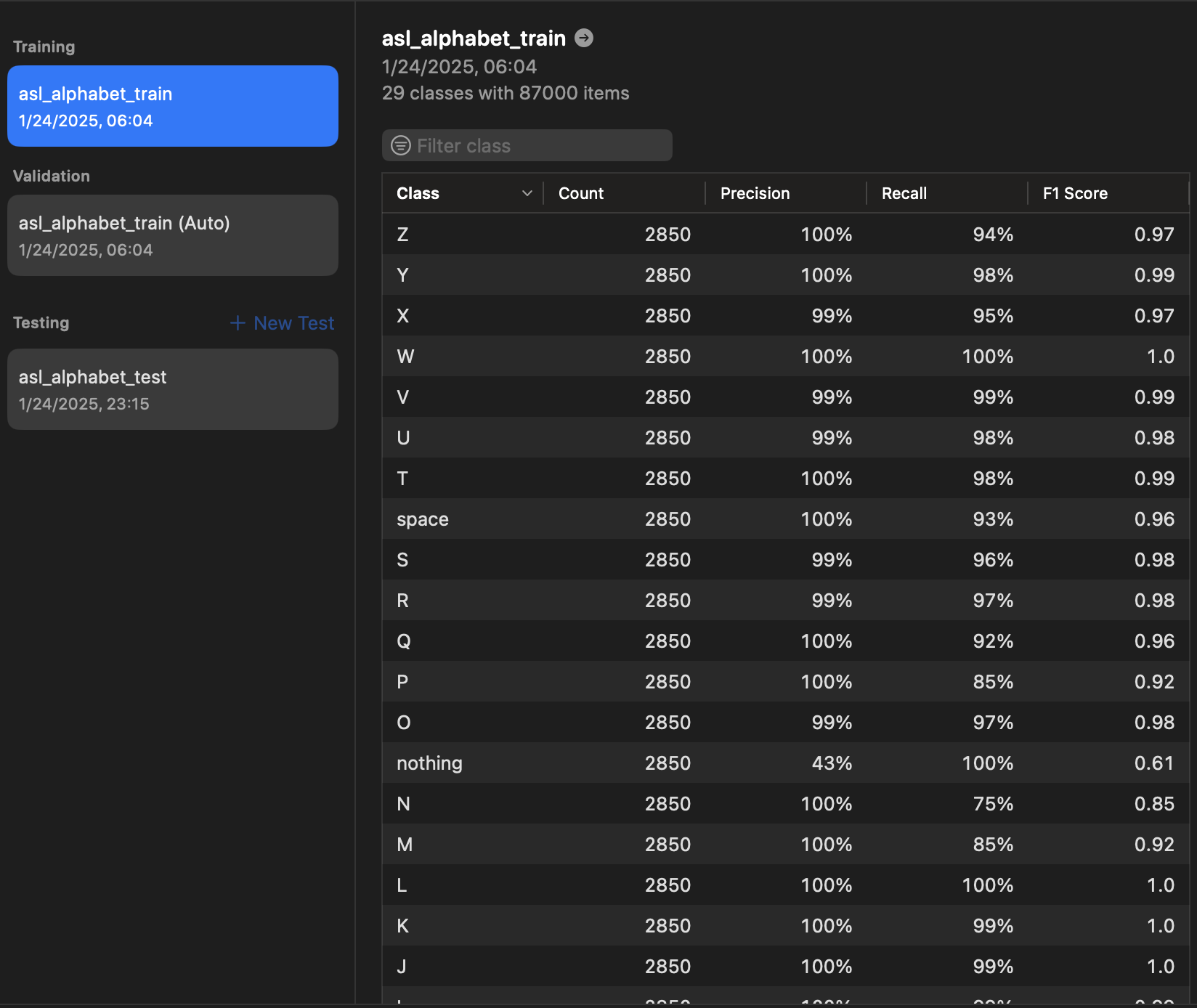
또한 평가표도 확인해 볼수 있습니다.
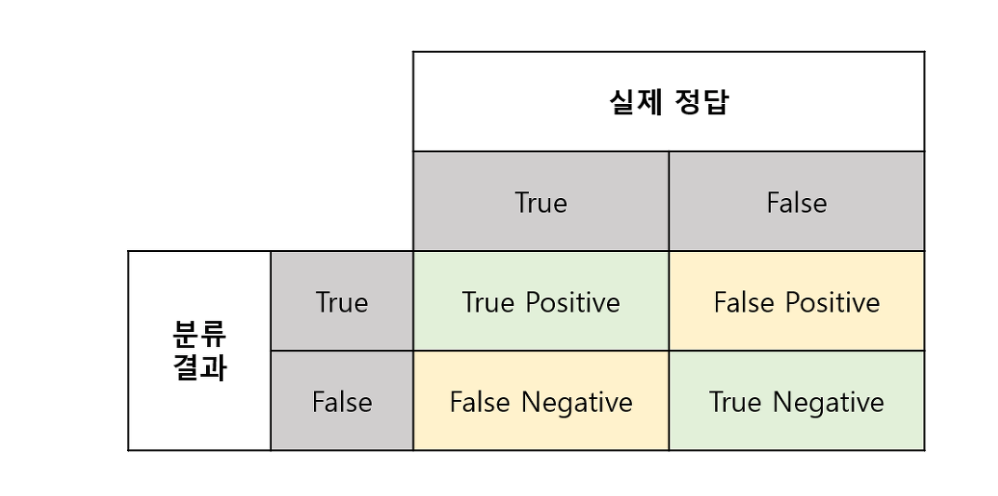
Create ML에서 훈련 후 평가 지표로 제공되는 Precision, Recall, 그리고 F1 Score는 모델의 성능을 평가하는 데 사용됩니다.
Precision(정밀도)
- 정확하게 예측한 양성 값의 비율 입니다.
모델이 양성(Positive)으로 예측한 데이터 중에서 실제로 양성인 데이터의 비율입니다.
False Positive(거짓 양성)가 적을수록 Precision 값이 높아집니다.
Recall(재현율)
- 전체 실제 양성 데이터 중에서 정확히 예측된 비율을 의미합니다.
실제 양성 데이터를 얼마나 잘 찾아냈는지 측정합니다.
False Negative(거짓 음성)가 적을수록 Recall 값이 높아집니다.
F1 Score
- Precision과 Recaall의 균형을 평가합니다.
특정 애플리케이션에서 Precision과 Recall 중 하나에 치우치지 않고 전반적인 모델 성능을 확인할 때 유용합니다.
F1 Score는 Precision과 Recall이 비슷할 때 가장 높으며, 둘 간의 불균형이 심할수록 낮아집니다.
마지막으로 Output탭에서 Get을 통해 학습된 모델을 추출할 수 있습니다.