소규모 팀에서 데이터 파이프라인 구축
구축 배경
데이터 요청 상황
"최근 ~한 유저의 수가 궁금해요"
"결제 전환율이 궁금해요"
"프로젝트의 성과를 측정하고 싶어요"
etc..처음에는 소규모 팀이라 데이터 팀이 별도로 존재하지 않고, 위와 같이 들어오는 요청들을 그때 그때 리소스를 투자해서 추출해주는 방식으로 데이터를 제공하게 되었다. 그렇게 진행하다보니 크게 다음과 같은 문제점을 식별할 수 있었다
- 들어오는 데이터 요청에는 명확한 기준과 정의가 없다
- 어떤 목적으로 요청되는 데이터인지 맥락 공유가 되지 않는다
- 요청시마다 대응하는 팀원이 달라 코드가 쉽게 휘발되고, 하나의 기준으로 데이터가 관리되지 않는다 위 3가지를 관통하는 내용이 결국은 "팀의 데이터 기준이 없다" 이다.
예를 들어, "결제 전환율"은 '신규 유저의 결제 전환율인지', '재결제 유저의 전환율인지'
신규 유저라면 신규 유저의 정의나 기준은 무엇인지, 전환율이라면 분모는 무엇인지 가 정의되어 있지 않았다.
또 한 가지는 '데이터를 어떻게 전달할 것인가?'의 문제였다.
처음에는 개인 DM으로 데이터 요청이 오게되어 데이터도 개인적으로 전달되다보니 팀에 공유되지 않았다
이 후 채널을 파서 요청을 처리하다보니 지속적으로 똑같은 데이터, 혹은 약간의 변형이 있는 데이터 요청들이 중복된다는 사실을 알게되었다.
중복적으로 혹은 자주 요청되는 데이터에 대해서는 날짜 시간에 맞춰 스크립트를 직접 실행시켜 전달해줘야했다.
무엇보다 채널에 데이터가 쌓이더라도 파편적으로 분산되어있어 데이터를 연관지어 보기 힘들다는 것이다. 이는 데이터를 통해 문제를 파악하고 추가 분석으로 이어지기 보다는 단발적인 호기심 해결이나 사실 전달로 끝나게 되었다.
문제 정의 및 채택 해결 방식
문제는 크게 다음과 같다
- 데이터에 명확한 기준이 없어 하나의 지표로 관리되지 않는다.
- 반복적인 요청으로 인해 백엔드 리소스가 분산되고 이로 인해 요청이 줄어들고 관심도가 낮아진다.
- 제공되는 데이터가 하나의 보드(Board)에 모이지 않고 파편적으로 제공되어 찾기 힘들다.1. 데이터에 명확한 기준이 없어 하나의 지표로 관리되지 않는다.
해당 문제를 해결하기 위해서는 팀이 현재 소통에 자주 사용하는 지표들에 대해서 명확하게 정의 내리는 회의를 주도하게 되었다.
해당 회의에서는 해당 지표를 지속적으로 봐야하는 이유는 무엇인지, 서비스에 맞는 정의는 무엇인지를 정했다.
예를 들어 다음과 같다
- 간단한 결제 전환율이어도, '온보딩 시작 대비 결제 전환율', '추천 대비 결제 전환율'로 명확한 시작점을
- 신규 결제 전환율이라면 신규 유저의 정의는 무엇인지
- Retention의 이벤트는 어떤 것으로 할 것인지, 해당 이벤트가 발현했다고 볼 수 있는 기준은 무엇인지
- Retention을 어떤 방식으로 볼 것인지 (Classic/Range/Rolling)
중요한 것은 이런 지표를 정의하는 과정에서 그럼 해당 지표의 목표는 무엇이고 왜 그런 목표를 잡아야 하는지 논의가 일어날 수 있다는 것이였다.
2. 반복적인 요청으로 인해 백엔드 리소스가 분산되고 이로 인해 요청이 줄어들고 관심도가 낮아진다.
백엔드 작업자가 자신의 메인 작업 이외에 갑자기 들어오는 요청을 처리하기 위한 업무 스위칭으로 인해 깨지는 집중력이 문제였다. 따라서 처음에는 다음과 같이 해결했다
'백엔드 서버에 스크립트 작성' -> Firebase로 주기적으로 요청 -> 'S3에 저장' -> Firebase + Slack bot을 이용해 특정 채널에 업로드 그러나 여러 개의 스크립트로 분산되고 결과물이 3.하나의 보드로 합쳐지는게 아니라 분산적으로 채널에 올라오는 문제가 여전히 남아있었다.
3. 제공되는 데이터가 하나의 보드(Board)에 모이지 않고 파편적으로 제공되어 찾기 힘들다.
처음에는 Pyplot 이나 Pandas를 사용해서 이미지 파일, 엑셀 파일로 만들어서 처리했지만 이를 하나의 보드로 관리할 수가 없었고 매번 채널에서 파일을 찾아서 봐야하는 수고로움이 생긴다.
이런 과정의 Depth를 줄이고 지속적으로 데이터가 스케쥴링으로 인해 처리되는 것을 중심으로 찾다보니 '데이터 파이프라인'의 선택지를 고려하게 되었다.
파이프 라인 안에서도 실시간/배치 파이프라인 중 배치 파이프라인을 선택했다. 소규모 팀으로 실시간으로 누적되는 지표를 보기보다는 반나절, 혹은 1일 단위의 업데이트로 충분하기 때문이다. 배치 파이프라인 구축으로는 GCP Composer를 이용한 Airflow를 선택했다. 선정 이유는 GCP 크래딧이 있어 0원의 비용을 들이고 1년 이상 운영할 수 있었고 클라우드 환경에 구축하기 때문에 로컬 환경에 별도의 Airflow를 위한 환경을 구축하지 않아도 된다는 이점이 있기 때문이다.
결과적으로 GCP 생태계 안에서 Airflow, Bigquery, LookerStudio를 사용해서 데이터 배치 처리 및 시각화를 해결하게 되었다. 이로 인해 고정적인 보드 하나로 지표를 확인 및 관리할 수 있는 환경을 구축하게 되었다.
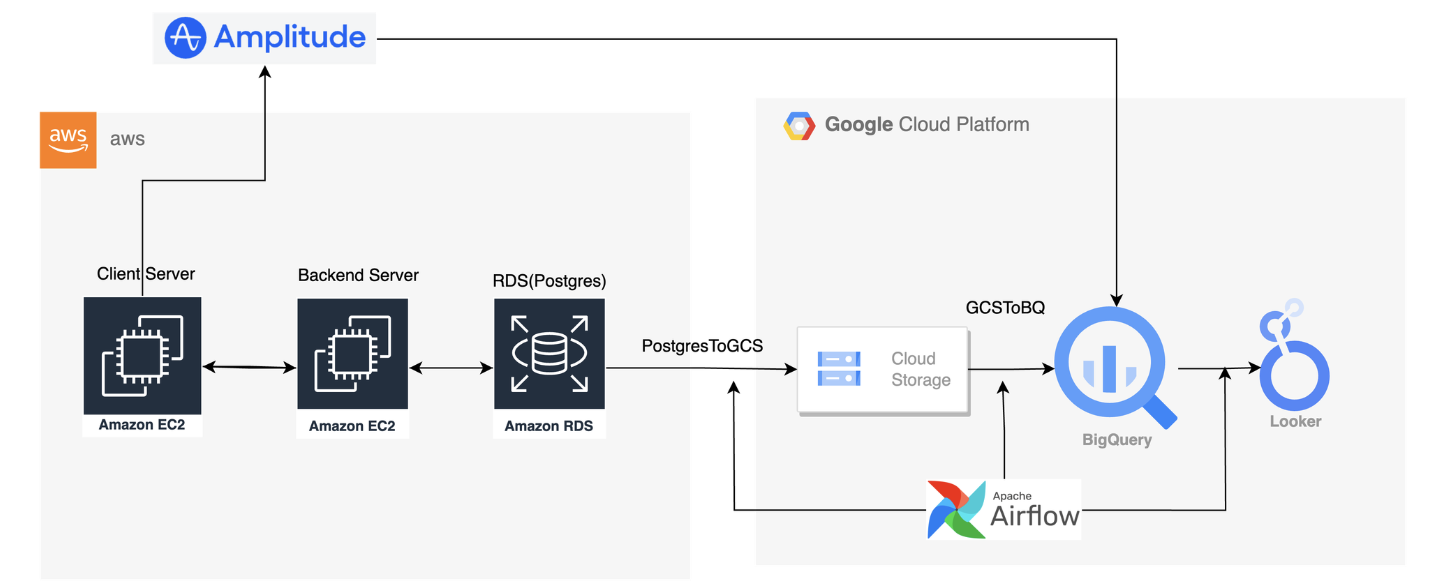
마주한 기술적 문제
-
source database에서 Bigquery까지 어떤 방식으로 데이터를 옮길 것인지
이는 간단하게 구글링을 통해서 해결하거나, GPT에게 물어보는 방식을 사용했는데 GPT는 실제로 존재하지 않는 Operator를 말해주는 경우가 많아서 해당 답변을 기반으로 구글링을 진행했다. -
source database에서 데이터를 추출하고 Bigquery에 적재할 때 APPEND, TRUNCATE 방식 중 어떤 것을 사용할 것인지
기존 백엔드 모델링시에 일부 모델은 created_at, updated_at과 같이 시간을 이용한 조건 검사를 할 수 있는 필드가 없어서 전체를 dump하는 방식인 TRUNCATE를 사용하고 별도로 update 없이 create로 누적되는 로그의 경우에는 Airflow 내부에 {{ ds }}를 사용해서 시간을 이용한 조건 검사를 통해 APPEND 하는 방식을 채택했다. -
과거 데이터 백필은 어떻게 할 것인지
나의 경우에는 처음에는 모든 데이터를 TRUNCATE하는 방식의 백필 DAG을 만들고 쓰고난 뒤에는 비활성화 시켰다. 이 후 메인 DAG에서는 APPEND를 사용해서 데이터를 누적해나가도록 했다 -
Bigquery 내부의 데이터셋은 어떤 기준으로 나눌 것인지
데이터 마트를 구성한다고 하기에는 소스가 RDB와 Amplitude밖에 없었지만, 팀마다 실제 요청하는 데이터의 종류가 달랐다. Bigquery를 DataWarehouse 이지 Mart로 사용하였고 RDB의 모델링 그대로 먼저 Bigquery에 올렸고 Amplitude는 별도 코드 작성없이 Connection 설정을 통해 데이터를 받을 수 있었다(물론 Merged Id는 따로 처리해줘야했다)이 후 수집된 데이터에 대해서 용도에 따라 새로운 테이블을 정의하고 관리했다. 예를 들어 유저의 메타 정보들을 관리하는 user table, 상품 별 추천, 판매, 재고현황을 볼 수 있는 sku_table, 대시보드 시각화를 위한 각 종 테이블을 모델링하여 관리하였다.
-
테이블을 새롭게 만들고 관리할 때 필요한 테이블에 유효한 값이 있는지 확인할 수 있는지
데이터의 신뢰성을 위해서는 가공에 사용되는 테이블들에 정상적으로 데이터가 올라왔는지 확인할 필요가 있었다. 이를 위해서 Sensor에 대해 리서치하고 Sensor Operator를 상속받아 원하는 조건을 처리하도록 하였다.
-
중복 코드 관리
반복적으로 사용되는 경우 하나의 Operator로 별도로 만들어서 관리했다. 예를 들어
PostgresToGCSOperator, GCSToBigQueryOperator, BigQueryExecuteQueryOperator 각각을 매번 반복해서 사용하기 보단 3개의 Operator를 이용한 PostgresToBigqueryOperator를 새롭게 정의하여 사용했다.
배운점
처음에는 데이터 요청에 대한 리소스 분산 문제로 시작되었지만 결국에는 '팀 내 데이터 기준 정의', '지표 목표 설정'이라는 근본적인 문제를 건드리게 되었다. 어떤 일이든 목표를 명확히해야 현재 상황과의 비교로 문제가 있는 부분을 파악하고 목표를 달성하기 위한 방식을 탐구하게 된다. 파이프라인을 구축하고 대시보드를 만드는 과정에서 결국 팀의 목표 ROAS달성을 위해서 각 종 지표의 목표는 무엇이고 목표를 달성하기 위한 단계적인 목표는 무엇인지 고민하는 시간을 갖게 되었다.
