BI 9장 텍스트 마이닝
텍스트 마이닝
텍스트로 부터 숨어있는 지식들을 발굴해 내는 기술
ex) SNS글로 부터 트렌드 분석, 문서내 주요 키워드 인식, 연관어 분석
정형 데이터: 엑셀같은
비정형 데이터: 영상, 이미지, 텍스트 데이터
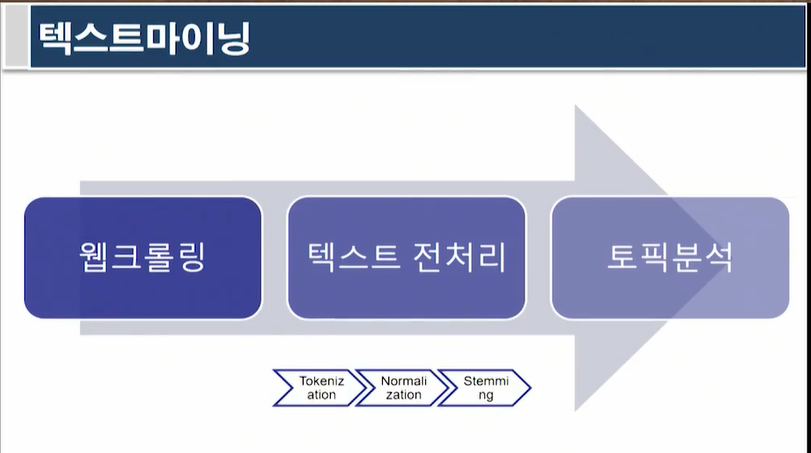
웹크롤링(데이터 수집): 웹사이트, 이메일, 트위터 등 비구조적 유형의 원시데이터
텍스트 전처리(데이터 전처리): 구조적 유형으로 변환
토픽 분석(데이터 분석): 군집화, 분류 등의 모든 설명적, 예측적 기법들을 사용
텍스트 전처리

토큰화: 뛰어쓰기 단위로 단어들을 잘라냄
정규화: 표준화를 시킴. 여기서는 캐피탈라이즈시킴
불용어 제거: 느낌표 마침표 제거 불용어 사전이 정의되어있음 거기 정의된것들은 제거 시킴
Stemming: 어근 찾기, fahionable -> fashion
과정
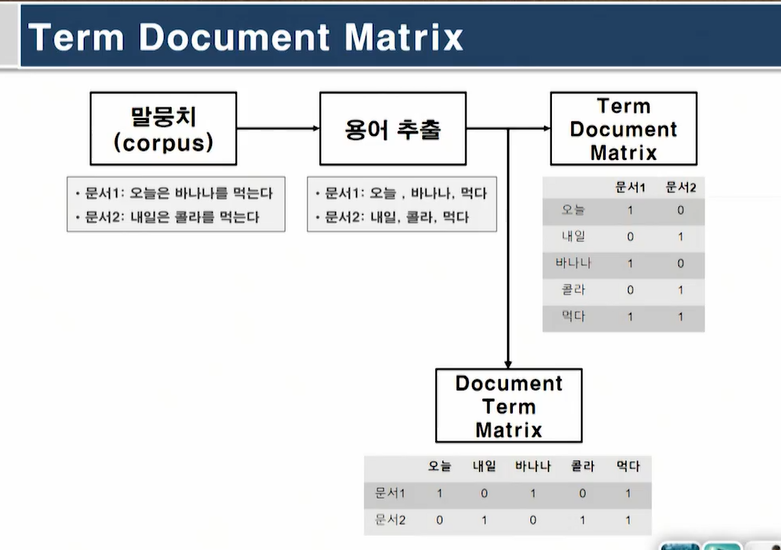
말뭉치: 컴퓨터가 이해할수 있는 구조
문장 유사도 계산

두 문장이 같은지 비교할 떄는 코사인 유사도를 많이 이용함
코사인 유사도: 벡터의 크기와 상관없이 사용가능

두번쨰는 Tdm형태로 카운팅한 예임
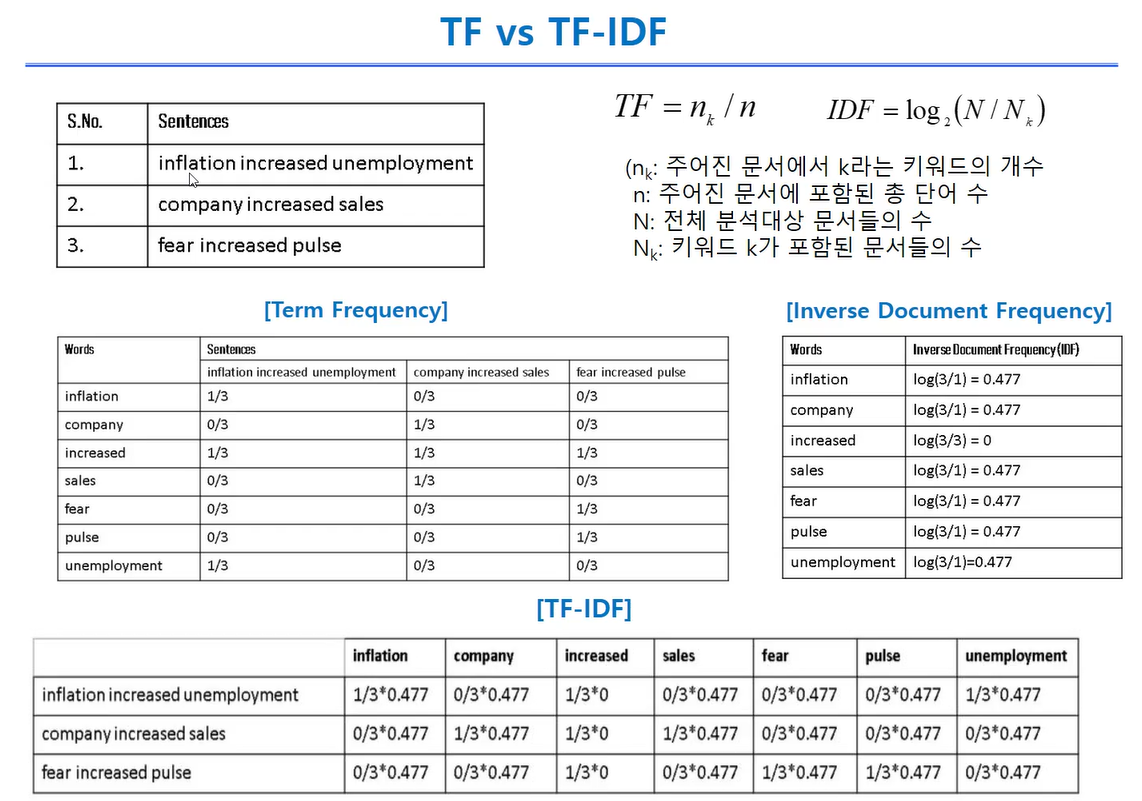
TF IDF
"A팀이 B팀을 이기다", "B팀이 A팀을 이기다"는 TDM관점에선 유사도가 같음

DF:가 높으면 모든 문서에 있으면 높으므로 의미가 없는 경우가 있음
그래고 iDF(역수값)을 사용함
BOW의 정단점
장점: 비교적 단순하며, 문서의 특징을 효율적으로 포착함
단점: 단어의 순서를 고려하지 않기 떄문에 문맥적인 의미가 무시됨. 희소행렬 발생
ex)"A팀이 B팀을 이기다", "B팀이 A팀을 이기다"는 BOW관점에선 유사도가 같음
, "누구도 그를 훌륭하지 않다고 할 수 없었다" 는 이해 불가능
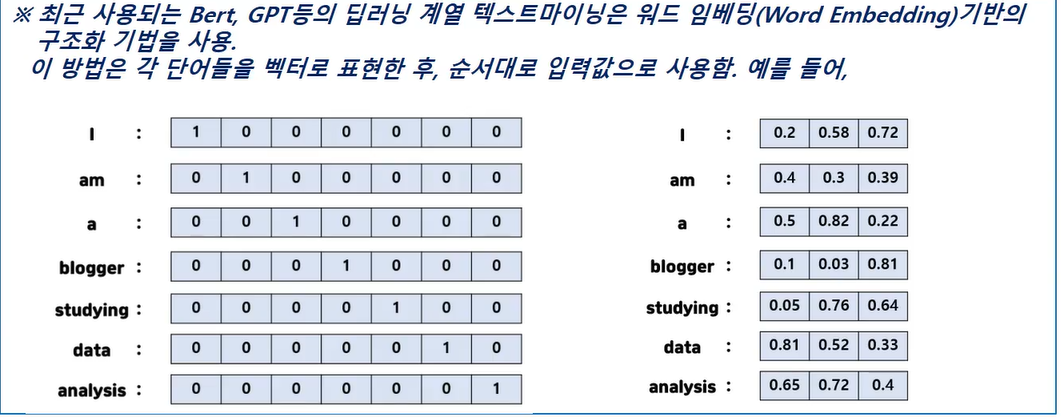
실습
영화 리뷰의 감성 분석
데이터: 영화 리뷰데이터로 긍정/부정 극성을 포함
목적: 상품평을 TF-IDF의 구조호된 형태로 변환
TF-IDF를 활용하여 의사결정나무로 긍정/부정을 분류하는 감성 분석
프로세스 화면
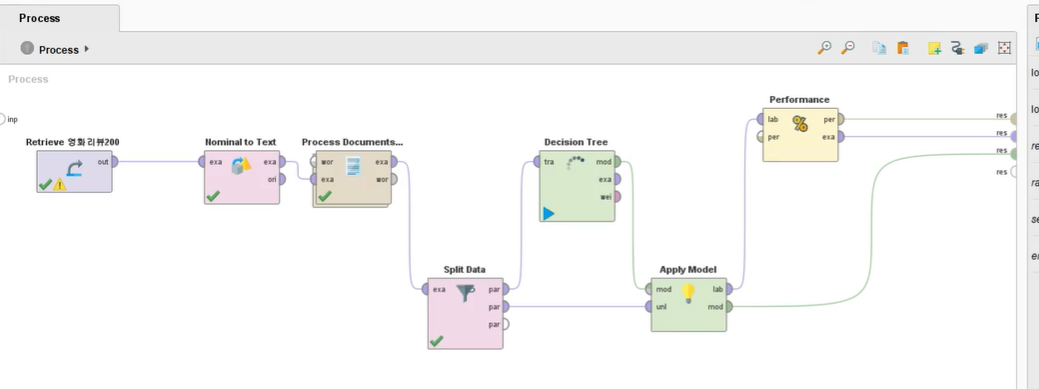
Nominal to Text
데이터를 가저온 후 text 형태로 수정
감성 분석 수행을 위해 긍정/부정을 종속변수 레이블로 설정
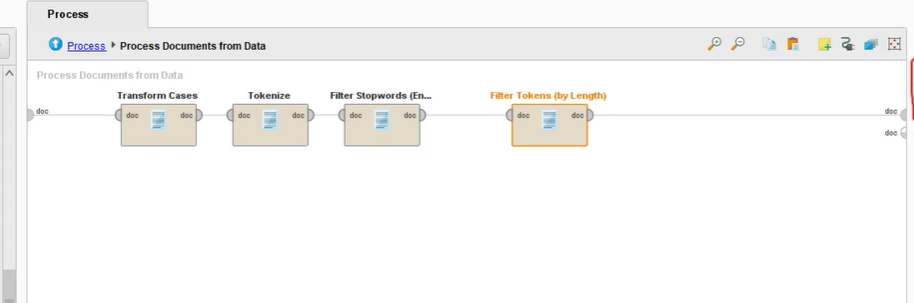
Process Documents From Data

서브 프로세스