
웹 스크래핑과 웹 크롤링의 차이점
웹 스크래핑 : 웹 페이지에서 내가 필요한 데이터만 추출 해 오는것,
웹 크롤링은 웹페이지에 허용된 범위 내에서 링크를 따라가면서 모든 데이터를 추출해 오는것.
준비사항 : 웹을 기반으로 하기 때문에 HTML의 기본을 알아야 한다.
Visual studio code 에서 한글 깨짐현상으로
meta charset="utf-8" 추가
1 HTML : 웹페이지를 만드는 언어
<body>
<h1>안녕하세요, 나도 코딩입니다.</h1>
<input type="text" value="아이디를 입력하세요">
<input type="password" >
<input type="button" value="로그인"><br>
<a href="/www.google.com">구글로 이동하기.</a>
</body>
2.Xpath
비슷한 태그, 등 의 혼돈을 위해 정확히 데이터를 추출하기 위해 사용
예시) /학교/학년/반/학생[2]
/html/body/div/span/a
/학교/학년/반/학생[2]
//*[@학번="1-1-5"]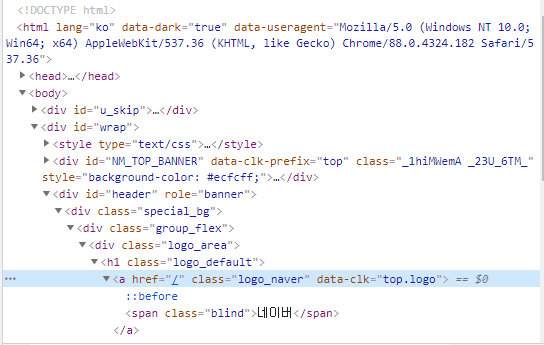
네이버에 이름부분을 태그로 떠려면
수많은 div부분을 복사해야한다
우클릭 > copy > Xpath 해서 Xpath를 한다면
긴줄을 요약해 간소화해 가져올 수 있다.
클래스랑 아이디나 이런 것들을 이용해
//*[@id="header"]/div[1]/div/div[1]/h1/a
크롬 > 네이버 > 우측 클릭 > 검사 > 좌측상단 화살표 클릭 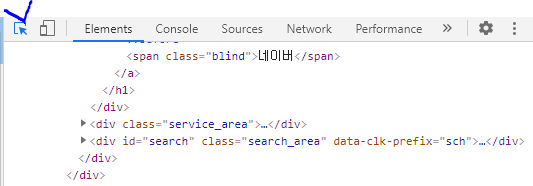
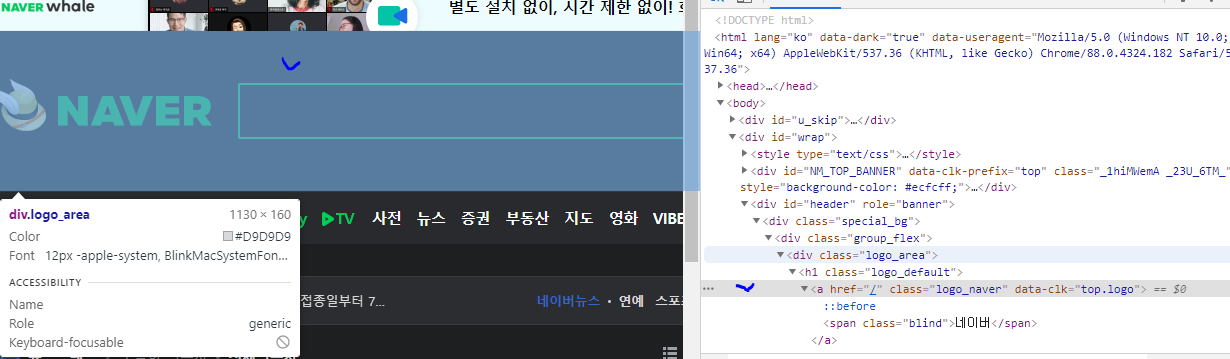
그럼 반대로 이미지를 클릭하면 오른쪽에 태그가 표시된다. 우클릭 > 카피 > copy Xpath or 최고 하단에 FUll copy 클릭
3. 리퀘스트 라이브러리
웹페이지 문서 정보를 가져와서 나의 웹 페이지 생성 후 필요 할 때 가져올 수 있는것을 리퀘스트 라이브러리 이다.
visual studio code 에서
pip install requests 해서 다운로드
이쪽 경로에 3_requests.py라는 파이썬 파일을 생성한다.
응답속도 200이면 잘 접근 되는 것이다.
res = requests.get("html://naver.com") < 해당 사이트에서 get으로 가져온다
res.raise_for_status() < 문제가 없음 아래로 진행하고 문제가 있으면 종료 한다
저 2개의 코드는 항상 쌍으로 쓴다.
한줄 명령어 설명
- get : 함수로 웹 페이지를 추출
-.status_code : http 상태 코드 확인 가능
-.raise_for_status() : 웹 페이지를 불러오는 코드가 흐르고 문제가
생기면 멈추게 된다. 즉, get, raise_for_status()로도 간편하게 페이지를
불러올 수 있다.
-.
import requests
res = requests.get("http://naver.com")
print("응답코드:",res.status_code)응답코드: 200403은 접근권한이 없다라는 뜻이다.
html 올바른 문서를 가져올 수 없어서 웹 스크래핑을 할 수없다.
#### import requests
# res = requests.get("http://naver.com")
res =requests.get("http://nadocoding.tistory.com")
print("응답코드:",res.status_code)응답코드: 403
import requests
# res = requests.get("http://naver.com")
res =requests.get("http://nadocoding.tistory.com")
print("응답코드:",res.status_code)
응답코드: 200
정상입니다.
또는
import requests
res = requests.get("http://naver.com")
print("응답코드:",res.status_code)
res.raise_for_status()
print("웹 스크래핑을 진행합니다.")
응답코드: 200
웹 스크래핑을 진행합니다.네이버에서 긁어온 문자수를 검색
print(len(res.text))
182461 < 18만 문자수를 가져왔다.
너무 많으니까 가벼운 google로 바꿔보자
import requests
res = requests.get("http://google.com")
res.raise_for_status()
print(len(res.text))
13980
print(res.text) 라인 추가
import requests
res = requests.get("http://google.com")
res.raise_for_status()
print(len(res.text))
print(res.text) 
#파일 쓰기
with open("파일명","w") as 변수명:
변수명.write("내용")
#write 모드는 실행할 떄마다 내용을 덮어쓴다.
한국어 입력 시 외계어가 나올 수있다 그걸 방지 하기 위해 encoding="utf8"를 한국어라고 인식하게 해준다.
with open("mygoogle.html", "w",encoding="utf8") as f:
f.write(res.text)
2줄 추가 import requests
res = requests.get("http://google.com")
res.raise_for_status()
print(len(res.text))
print(res.text)
with open("mygoogle.html", "w", encoding="utf8") as f:
f.write(res.text)
좌측에 Editors 에 mygoogle.html 이 생기고 페이지를 열어보면
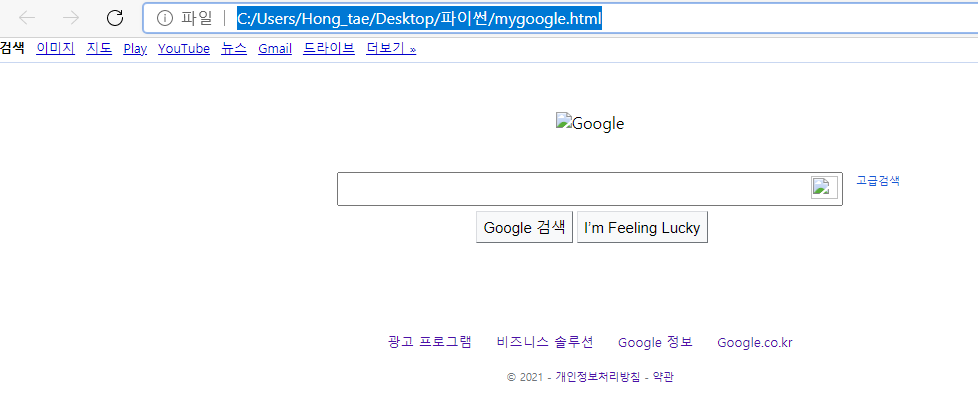
구글과 페이지 내용을 가져올 수 있다
4. 정규식
정해진 틀에 맞는것
ex) 주민등록 번호
앞에 6자리 뒤에 앞에 첫자리는 1 or 2
ex) 이메일주소
앞 이름 중간 @ 뒤에 메일 .com
ex) 차량번호
11가 1234
123가 1234
앞에 2~3자리가 있고 한글 이 있고
뒤에 숫자 4개 ex) IP 주소
192.168.0.1
1111.2000.3000.4000 < 올바른 아이피가 아니다.
import re
#abcd, book, desk
#ca?e
#care, cafe, case, cave
#caae, cabe, cace, cade, ...
p = re.compile("ca.e") # . :
#. (ca.e): 하나의 문자를 의미 > care, cafe, case | caffe(x)
#^ (^de) : 문자열의 시작. desk, destination | fede (x)
#& (se$) : 문자열의 끝 > case, base (0) | face(x)
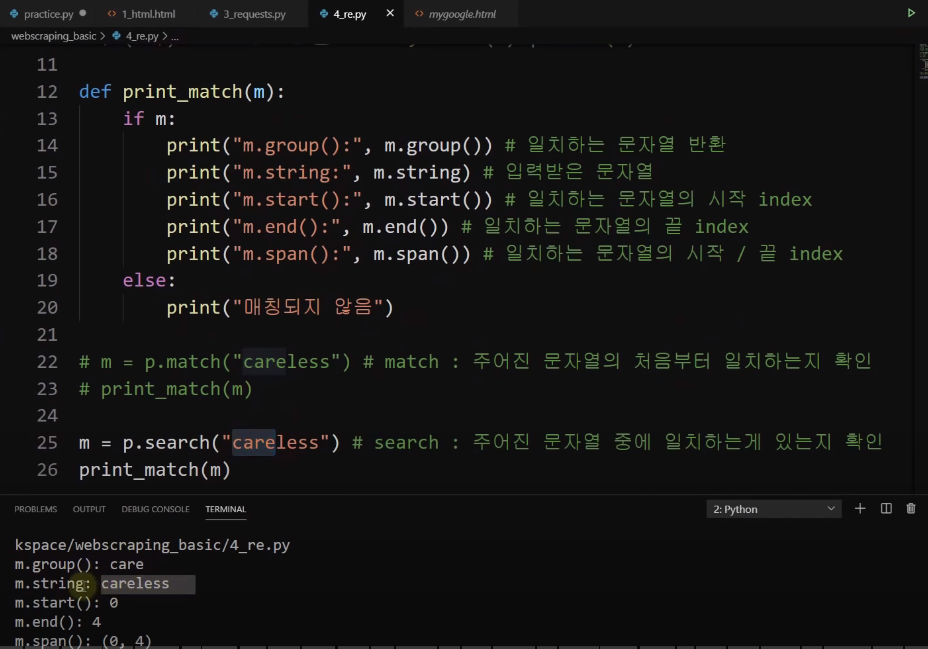
m = p.match("case")
print(m.group())
python 4_re.py
case
만약 re.compile과 p.match의 값이 다르면
compile은 ca.e
match는 caffe
import re
#abcd, book, desk
#ca?e
#care, cafe, case, cave
#caae, cabe, cace, cade, ...
p = re.compile("ca.e") # . :
#. (ca.e): 하나의 문자를 의미 > care, cafe, case | caffe(x)
#^ (^de) : 문자열의 시작. desk, destination | fede (x)
#& (se$) : 문자열의 끝 > case, base (0) | face(x)
m = p.match("caffe")
print(m.group())결과
print(m.group())#매치되지 않으면 에러가 발생
import re
#abcd, book, desk
#ca?e
#care, cafe, case, cave
#caae, cabe, cace, cade, ...
p = re.compile("ca.e") # . :
#. (ca.e): 하나의 문자를 의미 > care, cafe, case | caffe(x)
#^ (^de) : 문자열의 시작. desk, destination | fede (x)
#& (se$) : 문자열의 끝 > case, base (0) | face(x)
m = p.match("case")
if M:
print(m.group())
else:
print("매칭되지 않음")5. 정규식 2
사실 정규식은 이해가 안되서 모르겠다..
그럼에도 공부하고 싶다면
W3SCHOOLS에서 하단에 PYTHON 클릭
AND
PYTHON RE 검색
