1. Introduce
1.1. A GNN Layer
- GNN Layer의 두가지 구성요소 = Message transformation + message Aggregation
- 각 방식들은 위 두가지 구성요소 측면에서 차이를 보임
- e.g. GCN, GraphSAGE, GAT, ...
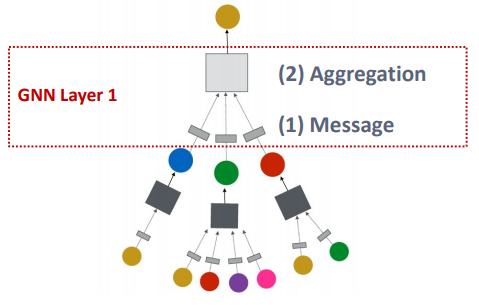
1.2. A Single GNN Layer
- Idea:
- 자식들로부터 오는 벡터 집합인 메시지 세트를 압축하고 싶음!
- 2-step process:
- 번째 GNN Layer의 Input과 Output
- Input: : 자기자신 노드, 이웃노드
- Output:
- GNN Layer에서는 아래의 2-step을 수행:
- (1) Message
- (2) Aggregation
- 번째 GNN Layer의 Input과 Output
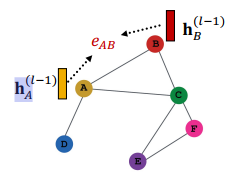
1.3. Message computation
-
Message function
- Intuition : 각 노드들은 메시지를 생성하며, 이것은 후에 다른노드들에게 전달됨
- 개념 : 이전 노드의 임베딩값들을 가져와서, 메시지 정보로 변환
- e.g. Linear layer에 적용됨을 가정하면, 아래와 같은 행렬수식과 같음
- 노드의 이전레이어 임베딩을 가져와서, 행렬 와 multiply (선형변환)
- : 이 때의 메시지함수는 단순한 행렬
- Message function에서 의 기능을 정의해야함!
- 추후 살펴볼 것.
1.4. Message Aggregation
- Aggregation
- Intuition : 각 노드가 이웃의 메시지를 집계함
- 을 받아와서, 이것을 압축하여 집계하여 하나의 메시지 형태로 만들고 싶음
- 집계함수의 예시 : Sum(), Mean(), Max() aggregator
- 모든 집계함수들은 order invariant(순서불변) 특성을 만족
- : 메시지들을 합산
- Intuition : 각 노드가 이웃의 메시지를 집계함
1.5. Message Aggregation의 Issue
- 노드 자체의 정보가 손실될 수 있다는 Issue가 존재
- 를 계산할때, 을 직접적으로 사용하지않음
- Sum등 aggregation을 해버리니, '자기자신'의 특징인 중요정보가 손실되어버림
- 를 계산할때, 을 직접적으로 사용하지않음
- 솔루션: 계산 시, 를 포함하여 계산
- (i) Message computation : 자기자신과, 이웃을 다룰 때 각각 다른 계산 사용
- 이웃계산:
- 자기자신:
- (ii) Aggregation : 이웃들을 집계한 후, 노드 자기자신으로부터의 메시지를 집계
- Concatenation이나, Summation을 이용하여 자기자신의 정보를 유지
- 일단 이웃들을 집계하고, node 자기자신의 메시지를 concat하여 계산!
- [질문]❓Summation은 2단계를 거쳐서 진행해도 정보 손실이 없나?
- Concatenation이나, Summation을 이용하여 자기자신의 정보를 유지
- (i) Message computation : 자기자신과, 이웃을 다룰 때 각각 다른 계산 사용
1.6. 요약
- Single GNN Layer는 다음 각 단계들의 조합으로 구성:
- Message : 각 노드들은 메시지를 계산함
- Aggregation : 이웃들의 메시지를 집계함
- Nonlinearity (activation): 지수적으로 표현하는 활성화함수
- Message : 각 노드들은 메시지를 계산함
2. Classical GNN Layers
2.1. Graph Convolutional Networks(GCN)
기존의 GNN 레이어를 언급하고, 이를 메시지+집계 관점에서 해석해보자
-
GCN 레이어의 표현:
-
위 수식을 Message + Aggregation으로 다시 써보면,
- Message : 를 에 multiply
- 이 때, 이웃노드의 개수로 1/N해주는 것은, 노드차수로 정규화하는 개념
- Aggregation : 모든 이웃노드에 대한 Summation
- Nonlinearity : activation
- Message : 를 에 multiply
-
결론 : GCN 레이어도 Message+aggregation 개념으로 설명가능
2.2. GraphSAGE
GraphSAGE는 GCN이 기반이며, 이를 확장한 approach
-
GraphSAGE의 레이어 표현:
- 이때, GraphSAGE는 함수에서, 평균뿐만아니라 다양한 집계함수의 선택을 허용함
- 또한 self-message를 CONCAT하여 자기자신정보손실을 방지(표현력증가에 기여)
-
위 수식을 Message + Aggregation으로 다시 써보면,
- Message: 를 통해 계산됨
- 2-stage Aggregation:
- Stage 1: 이웃노드들을 집계
- Stage 2: 자기자신을 CONCAT하고, 선형,비선형레이어 통과
- Stage 1: 이웃노드들을 집계
2.2.1. GraphSAGE의 Aggregation Function
- Mean: 이웃노드들의 가중평균 (GCN에서의 Aggregation과 동일)
- Pool: 이웃노드들이 벡터를 변환하여, 최소/최소와 같은 대칭벡터 함수를 적용하는 것
- 메시지변환시, 다층퍼셉트론을 적용함 (선형변환 꼭 할 필요X)
- LSTM: 시퀀스 모델을 이웃에서 오는 메시지에 적용할 수 있음
- 단, 시퀀스 모델의 경우 순서불변이 아님
- 순서를 변경하여 시퀀스 모델을 가르치고
- 수신하는 메시지의 순서를 무시하지 않게 하려 함
- 단, 시퀀스 모델의 경우 순서불변이 아님
추후 강의에서, 집계함수 선택의 이론적 속성과 결과에 대해 다룰것
2.2.2. GraphSAGE의 L2 Normalization
- Normalization:
- 선택적으로, 각 모든 레이어의 임베딩 에 Norm 적용 가능
- 임베딩 벡터의 유클리드 길이가 항상 1이 되도록 유지:
- 이 정규화가 없을 시, 임베딩 벡터가 각각다른 스케일을 가지게 됨
- 임베딩 벡터를 정규화 하면 성능이 향상될수있음 (not always)
- 정규화 이후, 모든 벡터는 동일한 표준으로 표현됨
- 모두 길이가 1이 됨
2.3. GAT(Graph Attention Network)
GAT는 attention(주의)라는 개념에서 시작됨
- GAT의 레이어 표현:
- : Attention weights
- 모든 이웃과 관련된 가중치 (노드가 주어질때, 이웃에 얼마나 많은 관심을 기울여야 하는지에 대한 가중치를 표현한 값)
- 가중치를 각기 다르게주면, 합계(aggregation)에서 다른 가중치를 가지게 된다는 의미가 있음
- : Attention weights
왜 GAT가 좋은 아이디어인지 생각해봅시다
- GCN/GraphSAGE를 GAT 관점에서 생각해보면?
- GCN/GraphSAGE에도 Attention weight와 같은 개념이 존재
-
- 노드 에서 오는 메시지의 가중치, 중요성을 나타냄
- 그러나 매우 제한적인 수식표현임
- 에는 의존하지않고, 에만의존(의 차수만을 이용하므로)
- 모든 이웃이 동등하게 중요하다는 표현이 될 수 있음!
-💡GAT에서는 모든 이웃이 각기 다른 중요도를 가짐을 반영
`이제 Attention의 아이디어를 살펴보자**
- Attention :
- 인지적 주의라는 의미에서 영감을 얻음
- 실제 인간의 뇌가 "인지"할 때에도, 주요부분에만 초점을 맞추고
- 다른 부분에 대해 복잡하게 연산하지 않음 (배경을 outfocusing)
- attention 는
- 입력데이터의 중요한 부분에 초점을 맞추고,
- 나머지 부분은 거의 무시됨
- 인지적 주의라는 의미에서 영감을 얻음
그럼 weighting factors인 alpha를 어떻게 학습할까?
-
목표 : 그래프의 각 노드의 서로 다른 이웃에 대해 임의의 중요도를 특정하는 것
-
아이디어 : 다음 attention strategy에 따라 각 노드의 임베딩 을 계산
- attend : 노드에 서로 다른 중요도를 부여하는 것
- 이웃에 있는 서로 다른 노드에 서로 다른 가중치를 부여
-
매커니즘
- 1) 노드쌍간에 서로 얼마나 중요한지 알아내기
1번 단계
(i) 는 어텐션 매커니즘 의 부산물로 계산됨
- 노드쌍 의 메시지 기반으로 attention coefficient 를 계산함
👆 는 노드 에 대한 의 중요도를 나타냄
- 1) 노드쌍간에 서로 얼마나 중요한지 알아내기
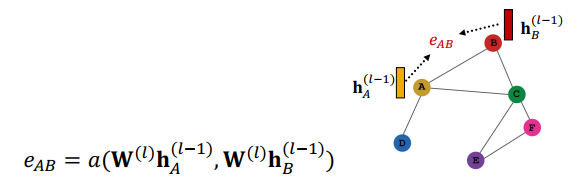
-
2) Normalize & Weighted sum
2번 단계(i) Normalize: 를 정규화하여, 최종적으로 로 표현
,
(ii) weighted sum: (i)에서 구한 를 기반으로, 가중합을 계산
-
3) 중요도 를 계산할 때의 매커니즘을 어떻게 표현할까?
- e.g. 간단한 single-layer NN을 활용
- 를 학습가능한 파라미터로 구성
- 의 파라미터들은 모두 공동으로 훈련됨 (trained jointly!)
- end-to-end fashion(?)으로 weight행렬들과 함께 학습
- e.g. 간단한 single-layer NN을 활용
- 4) Multi-head attention: 어텐션 매커니즘의 학습 과정을 안정화시키는 방법
-
Idea : 여러개의 attention score를 생성하고, 동시에 배우도록 훈련!
...- (i) 서로다른 를 통해 표현된 메시지들을 구하기
- 임의의 시작 매개변수로 초기화 후 학습 진행
- 결론적으로 각기 다른 파라미터를 갖게 될 것
- 학습 이후 각각 다른 local minimum에 도달하게 될 텐데,
- 이 여러개를 집계하여 성능을 향상! (robust model, stabilize)
- (ii) output을 모두 집계함: concatenation / summation
- (i) 서로다른 를 통해 표현된 메시지들을 구하기
-
2.3.1. Benefits of Attention machanism
- 주요 이점
- 서로 다른 이웃에 대해 서로 다른 중요도 값을 암시적으로 지정 가능
- 그 외
- 병렬화: attentional coefficient 계산 시, 모든 메시지에 걸쳐 병렬화 가능
- Aggregation 역시 모든 노드(메시지)에 걸쳐 병렬화 가능
- 자원효율성: 희소행렬연산 시, 정도의 저장공간만 필요함
- 저장량은 그래프 사이즈에 선형적이며, 매개변수는 그래프 사이즈와 무관한 고정사이즈임
- 질문❓ 왜 그래프사이즈와 무관한가?
- 저장량은 그래프 사이즈에 선형적이며, 매개변수는 그래프 사이즈와 무관한 고정사이즈임
- 지역화: attention weight는 지역 네트워크(이웃)에 집중하는 특성
- Inductive capability(귀납성?): 질문❓무슨말인지..?
- 공유된 edge-wise mechanism이라 칭할 수 있음
- global graph 구조에 의존적이지 않음
- 병렬화: attentional coefficient 계산 시, 모든 메시지에 걸쳐 병렬화 가능
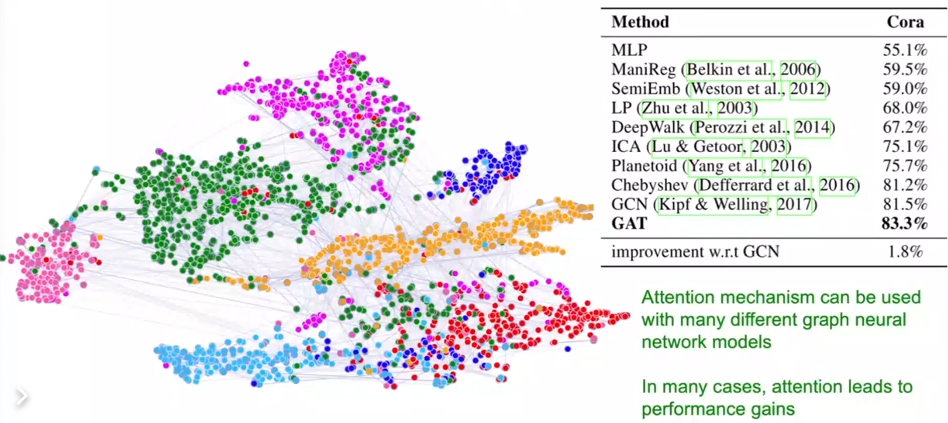
2.3.2. GAT Example: Cora citation Net
- GAT 기반의 노드 임베딩의 t-SNE plot
- 각각의 노드 color는 7개의 publication class를 나타냄
- Edge의 두께: 정규화된 attention coefficient를 나타냄 (비대칭적일수있음)
- 성능을 보면, GAT가 83.3%로 GCN보다 개선된 성능을 보임
3. GNN Layer in Practice
3.1. 개요
- 실례에서 아래와 같은 클래식한 GNN Layer를 시작모델로 사용할 수 있음
- 일반적인 GNN 레이어 설계로도 좋은 성능을 볼 수 있으며,
- 현대의 DL 모듈들을 포함하는 것도 유용하다는 것이 많은 도메인을 통해 증명됨
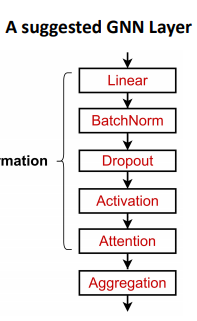
- 여러가지 최신 딥러닝 모듈과 기술들
- Batch Normalization: NN 학습 안정화
- Dropout: 과적합 방지
- Attention/Gating: 메시지 중요도에 대한 제어
- More: 기타 다른 DL modules..
3.2. Batch Normalization
-
Goal : Neural networks training의 안정화
-
Idea
- 배치의 입력이 주어졌을 때(노드임베딩값),
- 노드임베딩의 중심을 0으로 맞추고, 단위 분산(unit variance)을 갖도록 크기 조정

- embedding에 대한 평균과 분산을 구하고, 이를 이용하여 정규화(평균 0 분산 1)
- 이를 선형변환의 입력으로 사용하여 파라미터 학습
3.3. Dropout
-
Goal : 과적합(over-fitting) 방지
-
Idea
- 학습 : 작은 확률 로, 임의의 뉴런 집합을 0으로 설정해버림 (turn-off)
- 테스트 : 모든 뉴런에 사용
- 즉, Neural을 과적합하지않게 만드는 효과가 있어 모델 성능이 좋아짐
-
GNN에서의 활용 사례
- message function의 linear layer에서 dropout이 적용됨 (GNN)
- 의 일부를 0으로 설정하여, dropout
3.4. Activation (비선형함수)
- 임베딩 의 -th 차원을 활성화하
- ReLU : 일반적으로 많이 사용됨
- Sigmoid : 출력범위[0,1], 입력범위 무한대
- Parametric ReLU(PReLU): 경험적으로 가장 잘 동작, ReLU보다 고성능
- 0보다 크면, x그대로 출력, 0보다 작으면, x에 특정계수를 곱한값을 출력
- PReLU에서 x에 곱하는 계수는 학습파라미터임 (그래서 성능이 좋음!)
- ReLU : 일반적으로 많이 사용됨
4. Summary
- 현대의 Deep learning module들이 GNN layer의 성능향상을위해 사용됨
- GNN layer를 설계하는 것은 여전히 활발하게 논의되고 있음
- 다양한 GNN layer설계에 대해 탐구해보기: GraphGym에서!
