문제 정의
프로젝트 수행 중에 Fastapi에서 작업시간이 5분이상 소요되는 작업이 존재했었다. 성능을 개선함으로써 시간을 단축하고자 한다.
이 글에서 예시로 들 SELECT문은 SIMULATION 테이블에서 해당 조건 (simulation) 을 만족하는 목록을 모두 가져오는 것이다.
- 기존 방식에서는 7분 18초 소요

-
기존 로직
from google.cloud import bigquery def simulation_iteration(simulation_list): # [{"simulation_id": "2dsadwq", "simulation_id": "22dsadwq", "simulation_id": "25dsadwq"}, ...] client = bigquery.Client() # Bigquery Client 객체 results = [] # 모든 결과를 담은 리스트 for idx, simulation in enumerate(simulation_list): query = f""" SELECT * FROM SIMULATION WHERE 1=1 AND SIMULATION_ID = '{simulation_id}'; """ # 작성할 쿼리문(SELECT .. FROM ...) query_job = client.query(query=query, location="asia-northeast3") results.append([row for row in query_job.result()]) # 1개의 쿼리결과가 list 형태
생성된 케이스 하나 당 10~15초 걸리기 때문에 배열의 길이가 길수록 처리시간이 매우 길어짐
MutiProcessing
MutiProcessing는 여러 개의 프로세스가 동시에 실행되는 시스템을 말한다. 각 프로세스는 독립된 메모리 공간과 자원을 가지며, 운영 체제에 의해 관리되고 스케줄링 된다.
- 장점
- 안정성: 각 프로세스가 독립적인 메모리 공간을 차지하기 때문에, 서로의 영향이 없다. 그리므로 프로그램 전체의 안정성을 확보할 수 있다.
- 시스템 확장성: 독립적인 특징이기 때문에, 기능을 추가하거나 수정할 때 시스템 규모를 쉽게 확장할 수 있다.
- 보안성: 프로세스 간에 독립적이기 때문에 보안성이 높다.
- 단점
- Context Switching: CPU 캐시 메모리를 초기화, 프로세스 상태 저장 등의 작업들의 비용이 그만큼 많다.
- 자원 공유 비효율성: 각 프로세스가 독립적인 메모리와 자원을 사용하기 때문에 그만큼 총 사용량이 증가한다.
변경 후 (MutiProcessing)
for 문을 실행한다면, 각 쿼리마다 10~15초 가량 소요된다. 그래서 쿼리를 실행해서 결과를 받는 부분을 함수로 분리한다. 그리고 그 부분을 Pool(as pool)에 넣어서 실행하면 된다.
-
변경 후 소스 코드
from multiprocessing import Pool from google.cloud import bigquery def run_query(query: str): # 실행할 쿼리 client = bigquery.Client() query_job = client.query(query=query, location="asia-northeast3") return [row for row in query_job.result()] def simulation_iteration(simulation_list): # [{"simulation_id": "2dsadwq", "simulation_id": "22dsadwq", "simulation_id": "25dsadwq"}, ...] queries = [] # 작업들을 담을 쿼리 results = [] # 쿼리 결과들을 모두 담은 리스트 for idx, simulation in enumerate(simulation_list): query = f""" SELECT * FROM SIMULATION WHERE 1=1 AND SIMULATION_ID = '{simulation_id}'; """ # 작성할 쿼리문(SELECT .. FROM ...) queries.append(query) with Pool(processes=4) as pool: # 프로세스 4개로 병렬 처리 수행 results = list(pool.map(run_query, queries)) # pool.map(<실행할 함수>, <<해당 매개변수>>...) return results -
처리 완료 결과 8분 → 2분으로 단축

-
5 → 10개 (2분 → 1분20초)

Context Switching
Context Switching이란 멀티태스킹을 수행하는데, 운영 체제가 하나의 프로세스 또는 쓰레드에서 다른 프로세스나 쓰레드로 CPU의 제어를 전환하는 과정이다. 멀티태스킹 시스템에서 작업 간에 CPU 시간을 공유하고, 시스템 자원을 효율적으로 관리하기 위해 필요하다.
- 컨텍스트 저장
- 현재 실행 중인 프로세스 또는 쓰레드의 상태(컨텍스트)를 저장
- 컨텍스트는 CPU 레지스터, 프로그램 카운터(PC), 스택 포인터, 프로세스의 메모리 정보 등을 포함
- 스케줄러 실행
- 운영 체제의 스케줄러가 다음에 실행될 프로세스 또는 쓰레드를 결정한다.
- 컨텍스트 로딩
- 스케줄러가 선택한 프로세스 또는 쓰레드의 컨텍스트를 CPU에 로드한다.
- 실행
- 새로운 프로세스 또는 쓰레드가 CPU에서 실행을 시작
위와 같은 과정을 통해 여러 프로세스와 쓰레드 간에 공유하고 분배한다. 하지만 그만큼 비용이 증가하기 때문에 적절하게 사용할 수 있도록 고민이 필요하다.
MultiThreading
위와 같이 MutiProcessing의 비용 적인 단점에 대해 보완할 방법인 MultiThreading 기법이 있다.
MultiThreading은 MutiProcessing과 다르게 한 프로세스 내에서 여러 흐름을 사용하는 것이기 때문에, 메모리 영역인 Stack만 독립되어있다.
- 장점
- 자원의 효율성: 같은 프로세스 내의 쓰레드 들은 메모리와 자원을 공유하므로 중복될 요소들이 줄어 듦
- 오버헤드 감소: 같은 프로세스 내에서 생성되고 관리 되기 때문에 프로세스 생성 및 Context Switching의 오버헤드가 비교적 낮다.
- 단점
- 동기화의 복잡성: 여러 쓰레드가 메모리와 자원을 공유하기 때문에 일관성과 동기화 문제가 발생할 수 있다. → DeadLock, Race Conditions 문제
- 보안과 안정성: 잘못된 접근이나 경쟁 상태(race conditions)으로 인해 보안과 안정성 문제가 발생할 수 있다.
- 개발과 디버깅의 복잡성: 여러 쓰레드가 실행되기 때문에. 각 쓰레드의 동작을 추적하기 어려울 수 있다. → 순서를 파악하기 힘들 수 있다.
변경 후(MultiThreading)
사용법은 MutiProcessing와 거의 동일하다. Pool -> ThreadPoolExecutor 로 바꿔주면 된다.
-
소스코드
from concurrent.futures import ThreadPoolExecutor from google.cloud import bigquery def run_query(query: str): client = bigquery.Client() query_job = client.query(query=query, location="asia-northeast3") return [row for row in query_job.result()] def simulation_iteration(simulation_list): # [{"simulation_id": "2dsadwq", "simulation_id": "22dsadwq", "simulation_id": "25dsadwq"}, ...] queries = [] # 작업들을 담을 쿼리 results = [] for idx, simulation in enumerate(simulation_list): query = f""" SELECT * FROM SIMULATION WHERE 1=1 AND SIMULATION_ID = '{simulation_id}'; """ # 작성할 쿼리문(SELECT .. FROM ...) queries.append(query) with ThreadPoolExecutor(max_workers=16) as executor: # 객체 부분만 다르다. results = list(executor.map(run_query, queries)) return results -
실행 결과

적절한 worker수 설정
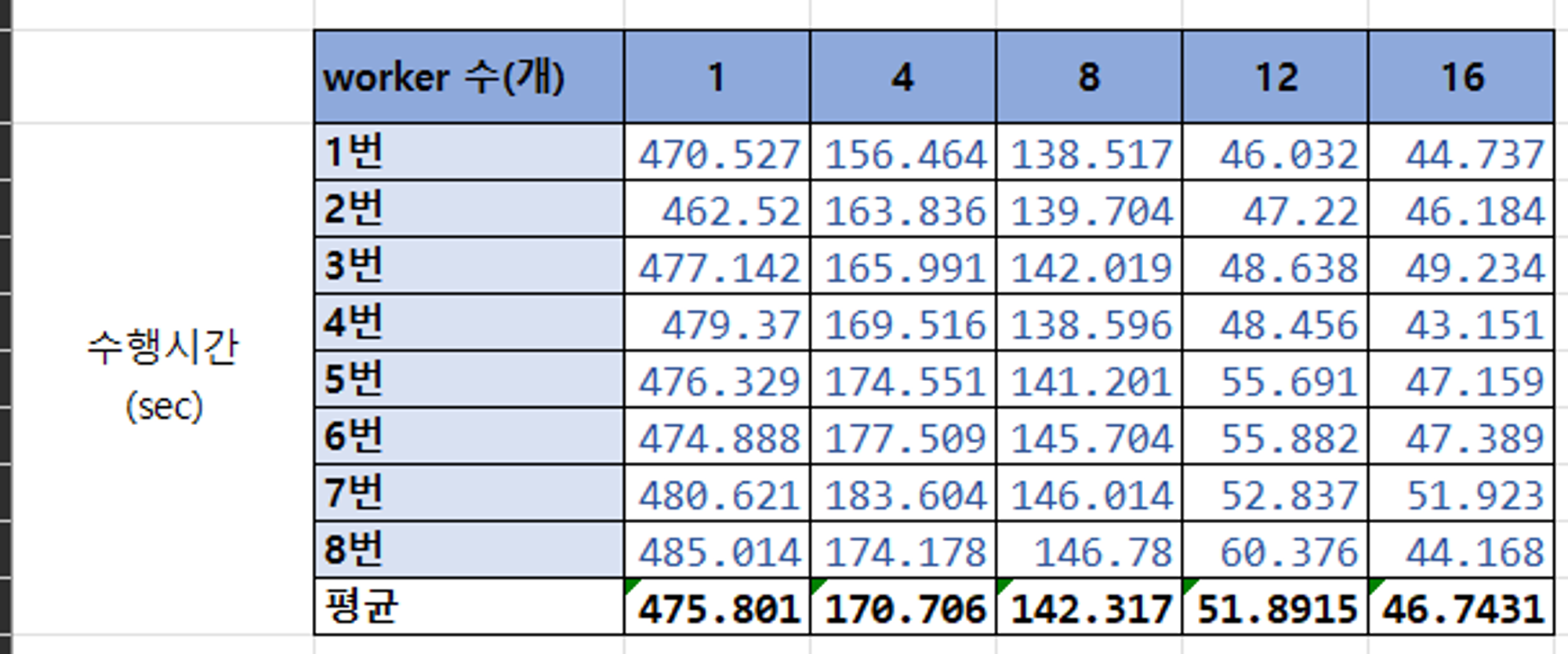
Core 개수가 서버에서 4개의 Core를 사용하기 때문에 4의 배수로 측정하였다. 총 8번의 요청에서 해당 PC에서 사용했을 때 worker 수 대비 처리 시간을 나타냄. 16개 까지는 적어도 수행 시간이 단축되는 결과가 나왔다.
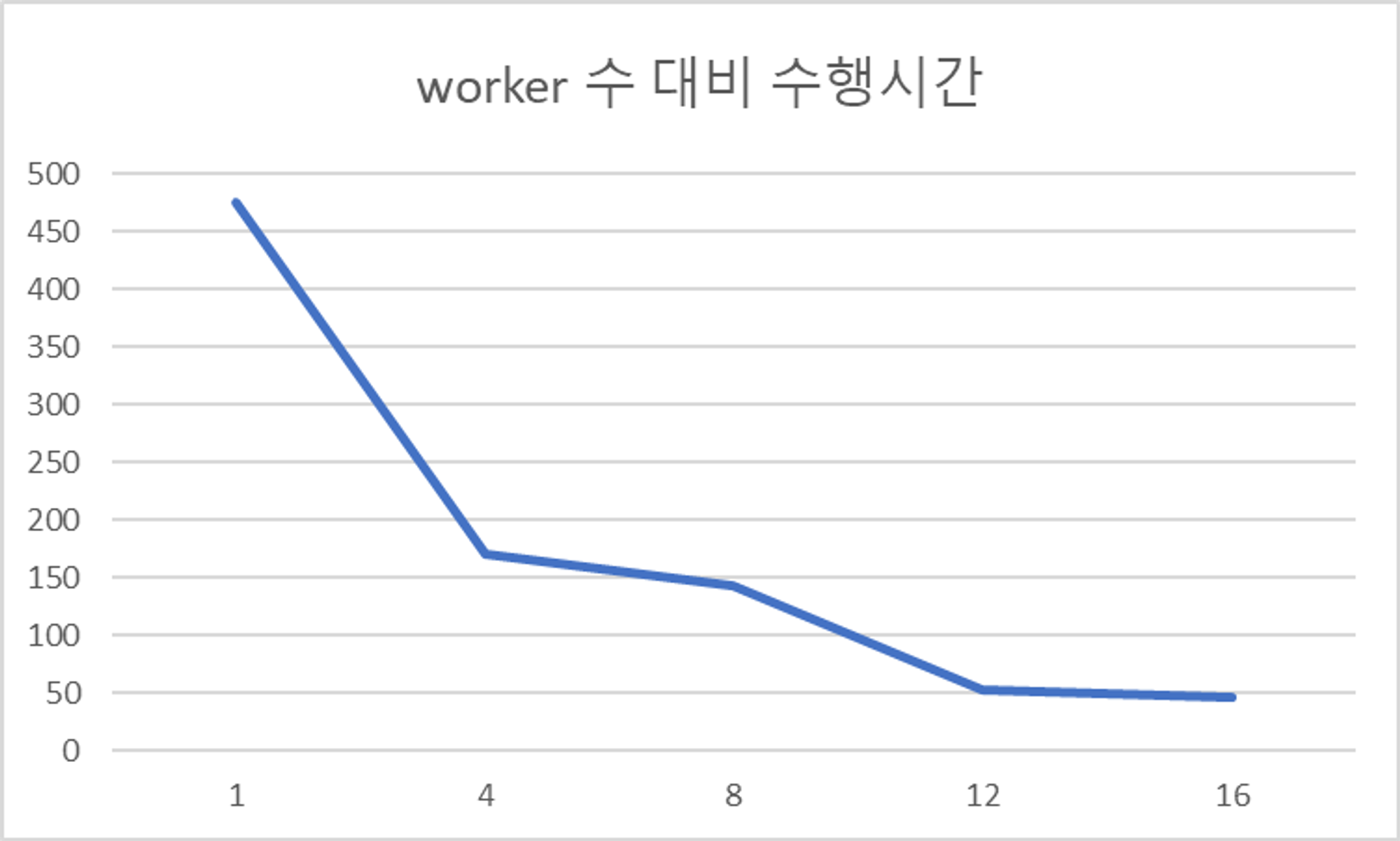
그래프를 그려보니 worker수가 12개까지 가파르게 수행 시간의 차이가 보인다.
MultiThreading을 선택한 이유
- 해당 로직은 I/O 바운드가 높은 작업이고 작업 순서에 영향을 줄만한 공유 객체가 없다.
- 컨텍스트 스위칭에 유리하고 자원에 효율적인 멀티프로세싱보다 멀티 쓰레딩 방식이 적절하다고 판단
- CPU 바운드작업이 아니기 때문에 Global Interpreter Lock이 발생함에 따른 병목현상의 위험이 적다.
결론
평균 7~8분정도 되는 작업을 1분 이내로 줄임으로써 작업속도를 크게 향상시켰다. 그리고 멀티쓰레딩과 멀티프로세싱의 장단점을 고려해보며 해당 방법을 선택하였다.
References
