
Colab 환경 설정
!apt-get install openjdk-8-jdk-headless
!wget -q https://dlcdn.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgz
!tar -xvf spark-3.4.0-bin-hadoop3.tgzimport os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.4.0-bin-hadoop3"
import findspark
findspark.init()
import pyspark
spark_version = pyspark.__version__
print("Apache Spark 버전 확인: " + spark_version) #3.4.0Sparksession 설정
from pyspark.sql import SparkSession
# SparkSession 생성
spark = SparkSession.builder\
.master('local[*]')\
.appName('Colab-Spark-Test')\
.getOrCreate();Google drive mount후, 예제 파일 가져오기
from google.colab import drive
drive.mount('/content/drive')
titanic_sdf = spark.read.csv('/content/drive/MyDrive/apach_spark/train.csv', header=True, inferSchema=True)
print('titanic sdf type: ', type(titanic_sdf))
---
titanic sdf type: <class 'pyspark.sql.dataframe.DataFrame'>spark.read.csv로 데이터 프레임을 가져온다.titanic_sdf.show(): pandas의 head()와 유사, head()는 5개의 행을 가져오지만 spark 데이터프레임은 20개를 가져온다.- 만약, 정해진 행만 가져오고 싶다면
titanic_sdf.limit(5).show()를 입력한다.
spark 데이터 프레임 -> pandas 데이터 프레임
import pandas as pd
titanic_pdf = titanic_sdf.select('*').toPandas()
print(type(titanic_pdf))
---
<class 'pandas.core.frame.DataFrame'>spark 기초 메서드 정리
printSchema(): pandas 데이터 프레임의 info()와 유사하나, data_type만을 출력, null도 출력을 하지 않기 때문에 별도의 SQL쿼리를 작성해야한다.
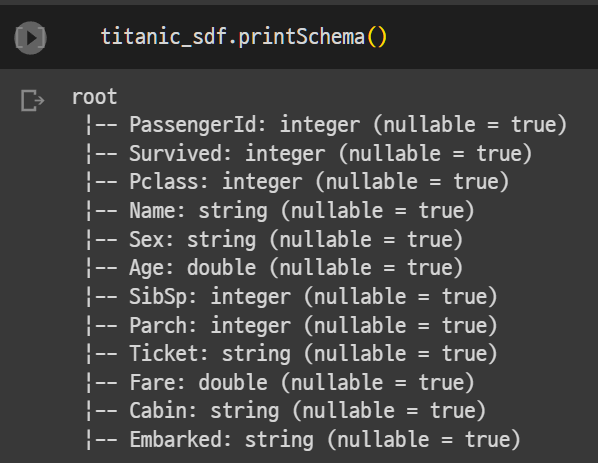
# null값을 확인하기
from pyspark.sql.functions import count, isnan, when, col
titanic_sdf.select([count(when(isnan(c) | col(c).isNull(), c)).alias(c) for c in titanic_sdf.columns]).show() 
describe(): spark describe()는 사분위수를 출력하지 않는다. 또한 결과를 확인하려면 .show()를 붙여야한다.
titanic_sdf.describe().show()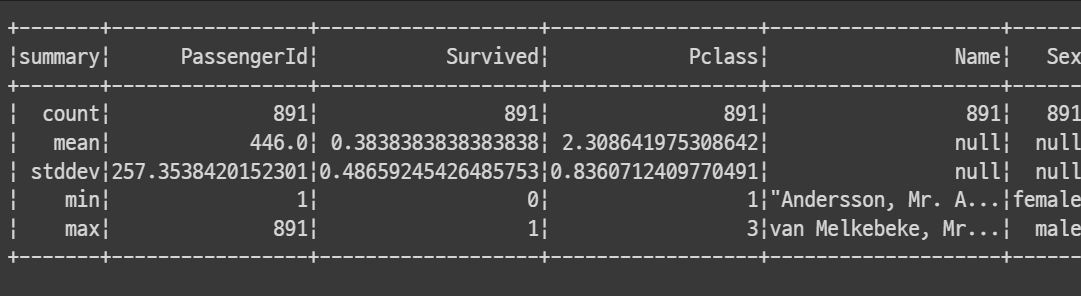
number 칼럼에만 describe()수행
number_columns = [column_name for column_name, dtype in titanic_sdf.dtypes if dtype!='string'] titanic_sdf.select(number_columns).describe().show()
count(), len(): spark DataFrame은 shape를 제공하지 않는다.
column의 개수는 Spark DataFrame의 columns속성으로 list로 반환된다.
row의 개수는 count()메소드 쿼리로 확인한다.
print('column들:', titanic_sdf.columns)
print('column개수:', len(titanic_sdf.columns))
---
column들: ['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked']
column개수: 12# titanic_pdf.shape =
print('titanic_sdf.shape: ', (titanic_sdf.count(), len(titanic_sdf.columns)))
---
titanic_sdf.shape: (891, 12)- select(), filter(), orderBy(), groupBY(), withColumn()등을 주말내로 한꺼번에 정리하겠다.

공대생의 코딩 정복기