
리액트에서 global하게 상태를 관리해야할 때 편하게 해주는 몇 가지 라이브러리가 있다. (Redux, Mobx, Recoil 등)
이 중 리액트에서 가장 많이 사용하는 상태관리 라이브러리 Redux에 대해서 알아보자.
Redux 등장 배경
Redux가 등장하기 이전 프론트엔드에서 데이터 흐름을 관리하는 방식은 MVC패턴이였다.
- Model - 데이터의 형식이나 구조를 관리한다. 모델에 맞지 않는 데이터는 흐름을 제어 받을 수 있다.
- View - 사용자에게 보여지는 부분을 담당한다. 사용자에게 보여지는 모습과 형태를 관리한다.
- Controller - 변화하는 데이터를 관리한다. View에서 발생하는 이벤트로 변경되는 데이터나 서버로부터 받은 변경된 데이터를 Model과 View에 업데이트 해준다.
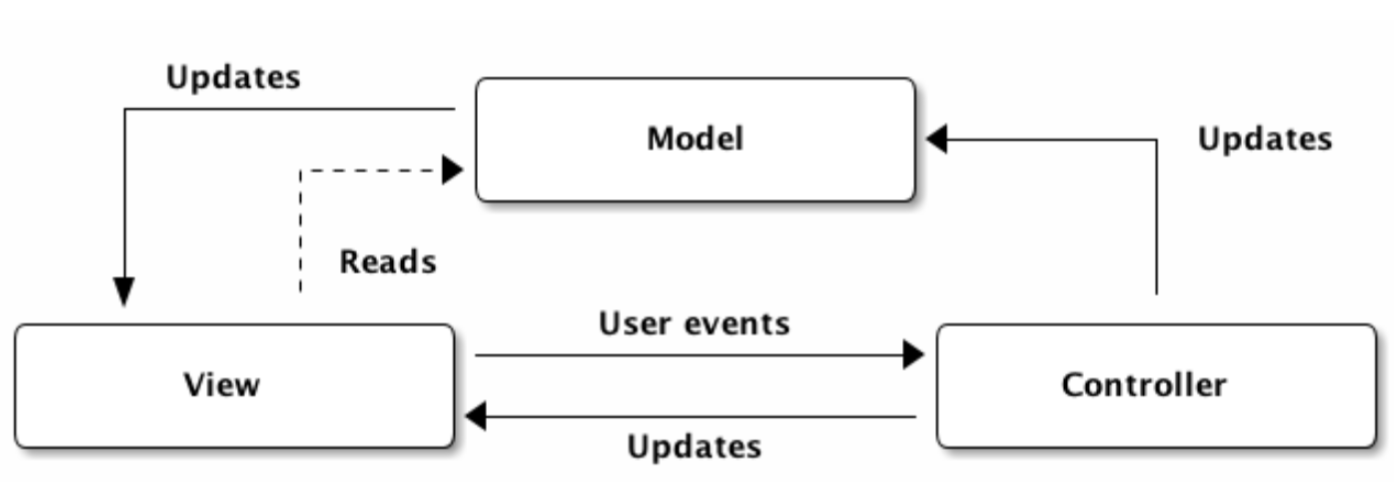
MVC 패턴의 특징 중 하나가 '양방향 데이터 흐름'이다. 모델이 변경된다면 뷰 또한 변경되고, 사용자에 의해 뷰에서 변경이 일어난다면 모델 또한 변경된다. 이러한 양방향 데이터 흐름은 설계하기 간단하고 코드 작성하기 쉬운 강점이 있다. 하지만 어플리케이션 규모가 커진다면 문제가 생긴다. 한 개의 모델이 여러 개의 뷰를 조작하고 한 개의 뷰가 여러 개의 모델을 조작한다면 데이터 흐름을 이해하기 힘들어 진다. 즉, 버그를 찾기 어려워지고 데이터 흐름을 추적하는데 많은 시간을 투자해야 한다.

Flux 패턴의 등장
MVC패턴으로 데이터 흐름을 관리하는데 많은 어려움이 있었기 때문에 이러한 문제를 해결하기 위해 데이터 흐름을 단반향으로 관리할 수 있는 새로운 아키텍처 패턴인 Flux패턴이 등장했다.
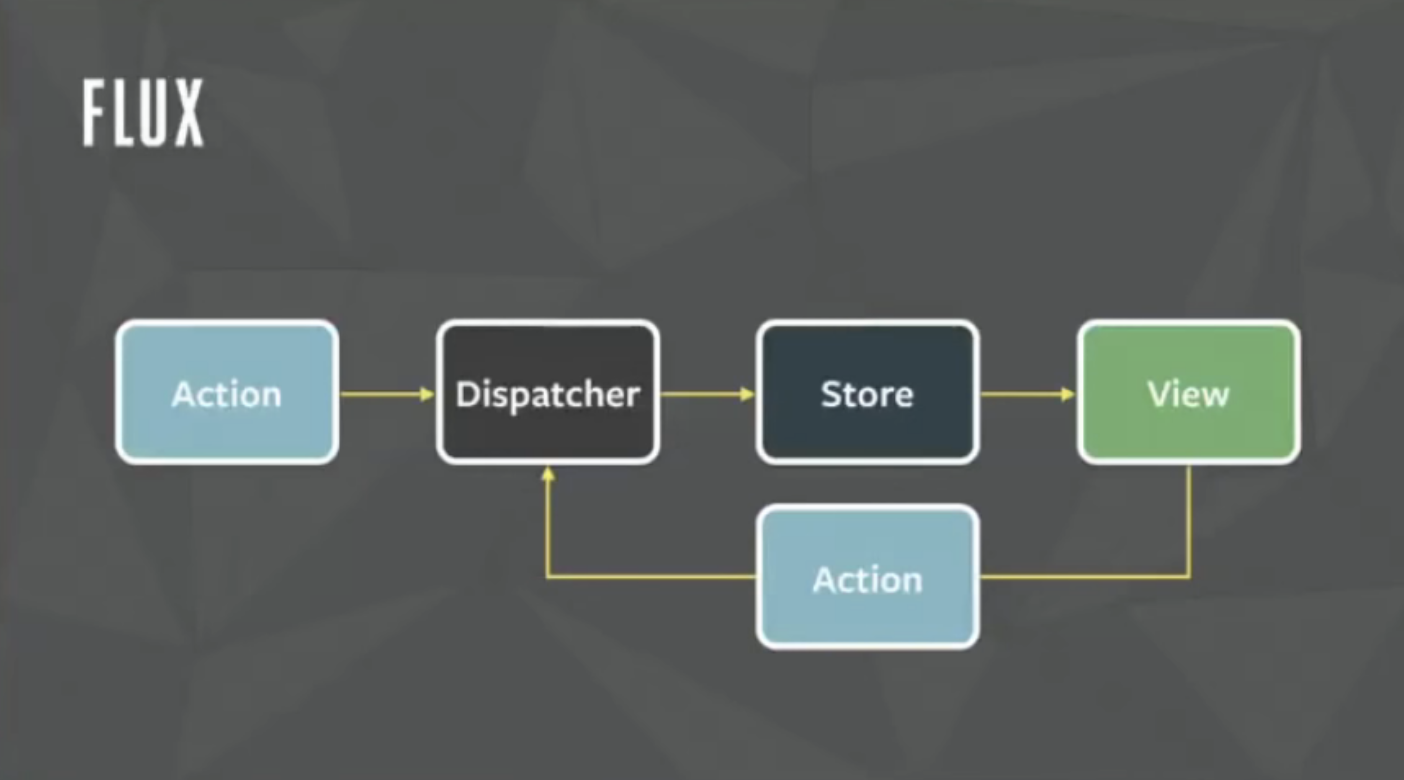
Flux는 MVC패턴에서 겪는 양방향 데이터 흐름의 복잡한 상황을 개선할 수 있도록 단방향 데이터 흐름 을 적용시켰다. 그래서 이제 View는 MVC 패턴과 달리 데이터를 직접 변경시키지 않고 Action에 넘겨준다. Action은 반드시 Dispatcher를 지나게 되고, 데이터의 변경은 Dispatcher를 통해서 일어난다.
View는 변경된 데이터를 Store를 통해서 전달 받는다. 이러한 단반향 데이터 흐름은 기존의 MVC 패턴에서 상태의 전이(뷰와 모델 사이의 데이터 변경이 연결된 수많은 곳으로 따라 변경되는 현상)을 없애주고 예측 가능하다는 특징을 갖는다.
Flux 패턴 동작 과정
-
사용자의 입력이 들어온다.
-
View는 action creator에게 들어온 action을 넘겨준다.
-
action creator는 dispatcher에게 넘겨준다.
-
dispatcher는 들어온 action 순서에 따라 store로 보낸다. 각 store는 모든 액션을 받지만 필요한 액션만을 골라 상태를 필요에 맞게 변경한다.
-
상태가 변경이 되면 새로운 상태에 맞게 뷰를 리렌더링한다.

그럼 왜 Flux가 아닌 Redux를 쓸까요?
Redux는 Flux에서 처리하기 힘든 일을 할 수 있습니다. 대표적으로 핫 리로딩(hot reloading)과 시간 여행 디버깅(time travel debugging) 입니다.
핫 리로딩
애플리케이션을 개발하며 코드를 작성할 때 일반적으로 코드를 조금씩 수정 해가면서 만들게 된다.
이 때, 수정할 때마다 결과를 빨리 확인하고 혹은 작은 실수를 했을 때 고친 뒤 빨리 확인할 수 있다면 개발 속도를 충분히 끌어올릴 수 있다는 것을 많이 느끼는데, hot reloading 은 이런 부분에 대해 아쉬운 점을 개선해준 Redux 의 개념 중 하나이다.
즉, 매번 수정을 하더라도 이전 상태가 사라지지 않는다는 점인데, 설명에 앞서 hot reloading 이 적용되기 이전의 모습을 살펴보면 다음과 같다.

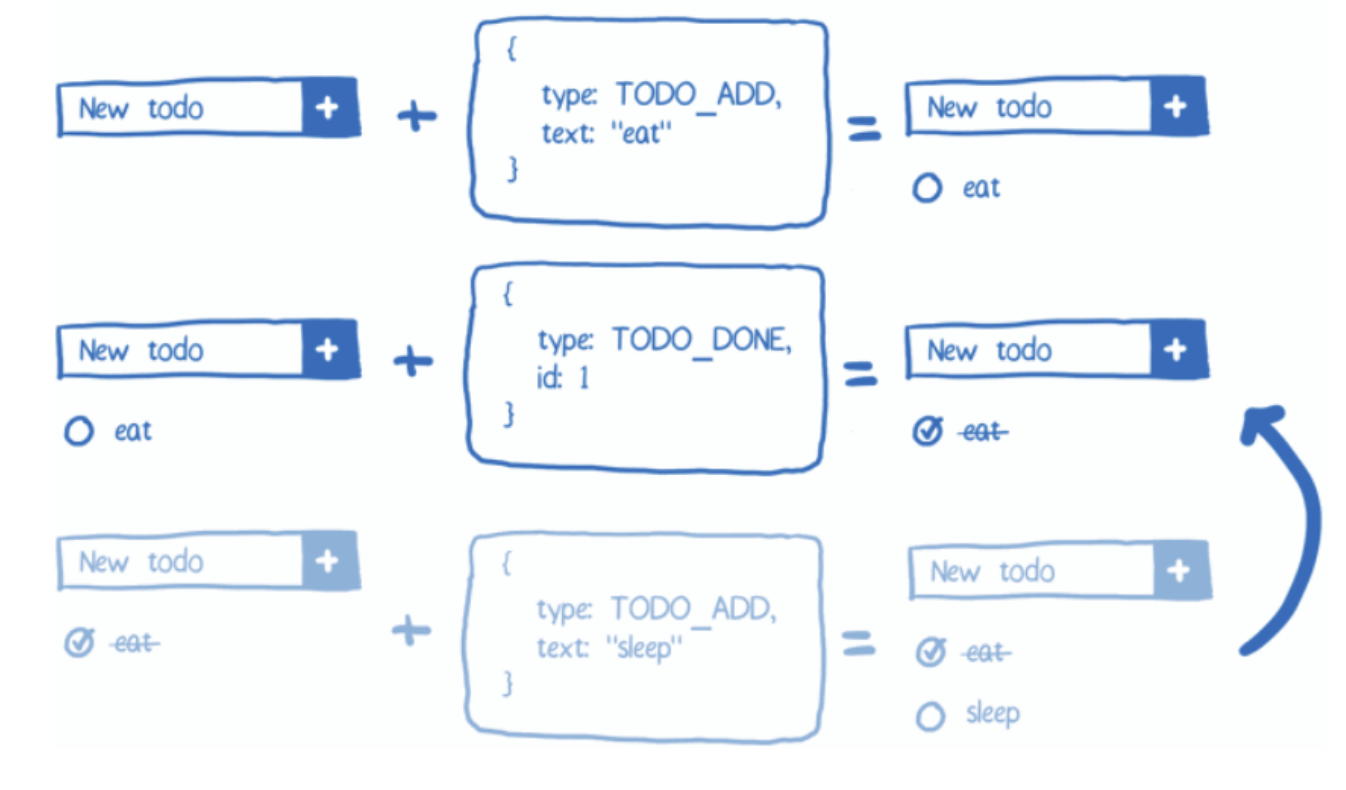
위의 그림은 핫 리로딩을 적용하기 전 그림이다. 왼쪽의 그림과 같이 todo 리스트를 몇 가지 추가한 후에 수정할 사항이 생겼다고 가정해보자.
코드 수정을 하고 새로고침을 하면 오른쪽 그림과 같이 todo 리스트는 사라진다.사라지는 이유는 store가 하고있는 두 가지 역할 때문이다.
첫 번째는 애플리케이션의 상태를 store가 가지고 있는 것이다.
두 번째는 상태가 action에 따라 업데이트 되는 것이다.
상태 업데이트에 관련 된 코드를 리로딩 하게 되면 애플리케이션 상태도 같이 리로딩 되기 때문에 저장된 상태 정보를 잃어버리게 된다.
그럼 Redux는 이 문제를 어떻게 해결할까?
Redux에서는 store에서 하는 두 가지 역할을 분리함으로써 이 문제를 해결했다.
Redux에선 store가 애플리케이션의 상태만을 가지게 되고, 상태 변경 로직은 Reducer에서 관리하도록 하였다.
따라서 Reducer를 리로딩하는 것으로는 상태를 잃어버리지 않게 된다.

time travel debugging
time travel debugging은 특정 상태로 되돌아갈 수 있게 해주는 기능이다.
한 가지 예시로 todo 리스트에서 첫 번째 데이터는 정상적으로 추가되지만 그 이후에 todo 아이템을 추가할 때 버그가 발생했다고 가정해보겠다.
만약 핫 로딩과 time travel debugging이 없다면 이 버그를 해결하기 위해선 코드를 수정하고 다시 버그가 발생한 시나리오대로 재현한 뒤 버그가 정상적으로 해결됐는지 확인하는 과정을 반복해야한다.
하지만 time travel debugging을 이용한다면 바로 이전의 상태로 돌아간 후 todo 아이템을 추가해봄으로써 기능을 테스트 할 수 있다.
Redux의 3가지 규칙
- 애플리케이션의 모든 상태는 하나의 스토어 안에 하나의 객체 트리 구조로 저장된다.
- 상태를 변화시키는 유일한 방법은 무슨 일이 벌어지는 지를 묘사하는 액션 객체를 전달하는 방법뿐이다.
- Reducer는 순수 함수로 작성되어야한다.
Reducer가 순수 함수로 작성되어야 하는 이유
리덕스는 두 객체의 메모리 위치를 비교하여 이전 객체가 새 객체와 동일한 지 여부를 단순 체크한다. 따라서, 리듀서 내부에서 이전 객체의 속성을 변경(mutate)하면 "새 상태"와 "이전 상태"가 모두 동일한 객체를 가리킨다. 그러므로 리덕스는 아무것도 변경되지 않았다고 생각한다. 그렇기 때문에 이것이 동작하지 않는것이다.
그럼 왜 이렇게 설계 되어있을까?
이렇게 하지않고 비교를 하려면 이전 상태와 새 상태를 깊은 비교(deep-compare)하는 것 뿐이다.
하지만 객체가 커지거나 비교해야 하는 횟수가 많다면 실제 앱에서는 엄청나게 무거운 작업이다.
따라서 이것의 해결 방법으로는 변경 사항이 있을 때마다 개발자에게 새 객체
를 만들어서 프레임 워크로 보내도록 하는 정책을 만드는 것이다.
그리고 변경 사항이 없다면 이전 객체를 그대로 되돌려 보내면 된다.
다시 말하면, 새로운 객체는 새로운 상태를 나타낸다.
이것이 리듀서가 순수함수여야 하는 이유이다.
Redux의 장점
- 데이터가
집중화(Centralized)되어 있어서예측 가능하다(Predictable) - 데이터 흐름이 단방향이라서
디버깅하기 쉽다(Debuggable). - 리덕스와 연관된 좋은 생태계가 구축되어 있어서 필요에 맞게
유연하게(Flexible)구현할 수 있다.
Redux 꼭 써야할까?
아니다. 상태를 관리함에 있어서 복잡성이 높지 않다면 Redux를 반드시 사용할 필요는 없다. React만으로도 단반향 데이터 흐름을 구현할 수 있기 때문에 꼭 필요하지 않은 상태에서 Redux를 사용한다면 불필요한 라이브러리만 하나 더 사용하게 되어 애플리케이션 사이즈만 커지게 되는 것이다.
다음 포스팅에선 redux와 context API를 비교해보도록 하겠습니다.
참고자료
