확률분포
확률변수(random variable)
: 랜덤한 실험결과의 의존하는 "실수" (표본공간의 부분집합)
- 이산확률 변수(discrete random variable)
: 모든 수의 값을 셀 수 있을 경우의 실험 결과 값 ex) 주사위, 동전 - 연속확률 변수(continuous random variable)
: 셀 수 없을 경우의 실험 결과 값 ex) 전교생 남학생의 키
확률분포(probability distribution)
확률 변수가 특정한 값을 가질 확률을 나타내는 함수를 의미한다.
ex) 주사위 2개를 던지는 실험 가정
- 확률 변수 X : 주사위 숫자의 차 (실수)
- X가 가질 수 있는 값 : 0,1,2,...,5
(1,6),(6,1)의 2가지 경우
주사위를 던질 때 마다 확률 변수 X값이 달라진다.
n번 실험하면 n개의 X값이 나온다.
n개의 숫자의 평균과 분산을 계산할 수 있다.
확률변수 X도 평균과 분산을 가진다.
(이때의 평균과 분산을 모집단의 평균과 분산이라 할 수 있다.)
이산확률분포
이산확률변수 X에 대한 확률 -> '확률질량함수'
이산확률변수 의 평균 (기대값, expected value)
이산확률변수 의 분산
: 의 평균
이산확률변수 의 표준편차
결합확률분포
두개 이상의 확률변수를 함께 고려하는 확률 분포이다.
ex) 확률 변수 X : 한 학생이 가지는 휴대폰의 수
확률 변수 Y : 한 학생이 가지는 노트북의 수
결합확률분포표에서 각 확률 변수의 확률 분포를 도출할 수 있다.
이를 주변확률분포(marginal probability distribution)
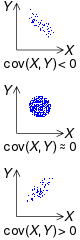
공분산(covariance)
X,Y 2개의 확률변수의 선형 관계를 나타내는 값이다.
0에 가까울수록 X,Y는 관계가 없다.
상관계수(correlation coefficient)
두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관 관계의 정도를 수치적으로 나타낸 계수이다.
(공분산은 각 확률 변수의 절대적 크기에 영향을 받으므로 공분산에 각각 확률변수의 표준편차의 곱으로 나누어주면 단위에 대한 영향을 상쇄할 수 있다.)
이항분포
n번의 베르누이 시행에서 성공횟수를 확률변수로 갖는 확률 분포 성공확률
일반적으로, 확률변수 K가 매개변수 n과 p를 가지는 이항분포를 따른다면,
라고 쓴다.
n번 시행 중에 r번 성공할 확률은 확률 질량 함수로 주어진다
※ 베르누이 시행(Bernoulli trial)
: 정확히 2개의 결과만을 갖는 실험 ex) 동전의 앞뒤, 주사위 홀수의 실패,성공
from scipy improt stats
f = 1-stats.binom.cdf(0,n=3,p=0.2)
#Cumulative distribution function 누적 분포 함수scipy 참고
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.binom.html
이항분포의 평균
(시행횟수 x 성공확률)
이항분포의 분산
이항분포의 표준편차
stats.binom.stats(n=3,p=0.2)
# array(0.6) array(0.48)
# 평균 = 0.6 , 분산 = 0.48정규분포
연속확률변수의 확률 분포(확률 밀도 함수)
정규분포의 확률밀도 함수
정규분포 표현
~
표준정규 확률변수(standard normal random variable)
표준정규분포
- ~ 평균 = 1, 표준편차 = 1
- 표준정규분포표 (https://bit.ly/3eQJpei)
ex) ~,
stats.norm.cdf(4,loc=4,scale=3) # loc = 평균, scale = 표준편차 -> 0.5포아송분포(poisson distribution)
일정 시간 단위 or 공간단위에서 발생하는 이벤트의 수의 확률 분포
ex) 하루 동안 웹사이트를 방문하는 방문자의 수
- ( x = 0,1,2 ~)
- 평균 = 분산 =
stats.poisson.cdf(2,mu=3) # mu = 평균지수분포(exponential distribution)
포아송분포에 의해 어떤 사건이 발생할 때, 어느 한 시점으로부터 이사건이 발생할 떄까지 걸리는 시간에 대한 확률분포
- ( 는 포아송분포의 평균)
- 평균 =
- 분산 =
lam = 3
stats.expon.cdf(0.5,scale = 1/lam) # scale = 표준편차
# 0.7768698398515702
