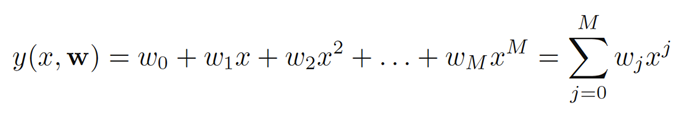
Machine Learning(기계학습)
- 학습데이터
입력벡터 ~ , 목표값 ~
목표값을 예측하는 함수 y(x)를 알아내는 것이 목표
지도학습의 회귀(regression)에 해당하는 예제
다항식 곡선 근사(Polynomial curve fitting)
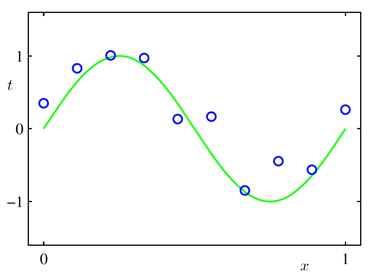
- 학습데이터
입력벡터 ~ , 목표값 ~ - 목표 : 새로운 입력벡터 이 주어지면 목표값 을 냄.
- 확률이론 : 예측값의 불확실성을 정량화시켜 표현 할 수 있는 수학적 프레임워크 제공.
- 결정이론 : 확률적 표현을 기반으로 방법론 제공
오차함수(Error function)
: 일반적인 목표값과 예측값 차이의 제곱합 함수
{}
과소적합(under-fitting) & 과대적합(over-fitting)
데이터가 다차원일 경우,
RMS = Root Mean Square = 제곱평균제곱근
데이터가 많아 질수록 복잡한 모델도 잘 맞는다.
규제화(Regularization)

ML 확률이론
확률변수, 확률분포는 둘다 '함수'다
(대문자 X,Y : 확률 변수, 소문자 x,y : 확률변수가 가질 수 있는 값)
확률변수 : 표본집합 S의 원소 e를 실수값 에 대응시키는 함수
확률분포 : 확률변수가 가질 수 있는 값에 대해 확률로 대응 시켜주는 함수
연속확률변수(Continuous Random Variables)
: 연속확률변수란, 어떤 범위에 속하는 모든 실수 값을 취할 수 있는 확률변수를 연속확률변수라고 한다 ex) 학교 남학생의 키
참고 : https://www.youtube.com/watch?v=ujZuGxsO-AE
-
누적확률함수(Cumulative distribution function, CDF)
: 주어진 확률 변수가 특정 값보다 작거나 같은 확률을 나타내는 함수이다. -
확률밀도함수(Probability Density Function, PDF)
: 확률 변수의 분포를 나타내는 함수로, 확률 밀도 함수 f와 구간 [a, b]에 대해서 확률 변수 X가 구간에 포함될 확률 P는 가 된다
모든 실수값 ,
확률변수의 성질
확률변수의 함수 (함수의 함수)
inverse CDF Technique
기댓값(Expectation)
: 확률분포 p(x)하에서의 함수 f(x)의 평균값
분산, 공분산
빈도주의, 베이지안
정규분포
곡선근사(curve fitting)-확률적 관점

K-PALACE