배경
Django DRF에서 제공하는 기본 페이지네이션 구현은 SQL의 LIMIT, OFFSET 을 사용하도록 되어 있다. OFFSET의 경우 예전에 공부했을 때 조건에 해당하는 Row들을 다 읽고난 후 필요 없는 데이터를 버리는 방식이라고 했었는데.. 수 백, 수 천만 개의 데이터가 있는 테이블에서도 LIMIT, OFFSET을 활용한 페이지네이션이 잘 동작할지 궁금했다. 그래서 실험을 해보았다.
실험
postgresql DB에서 core_coursemodule이라는 테이블이 있고 테이블의 row개수는 2천만 개로 셋업하였다.
다음 쿼리를 실행시켰을 때,
select * from core_coursemodule order by id OFFSET 8000000 LIMIT 20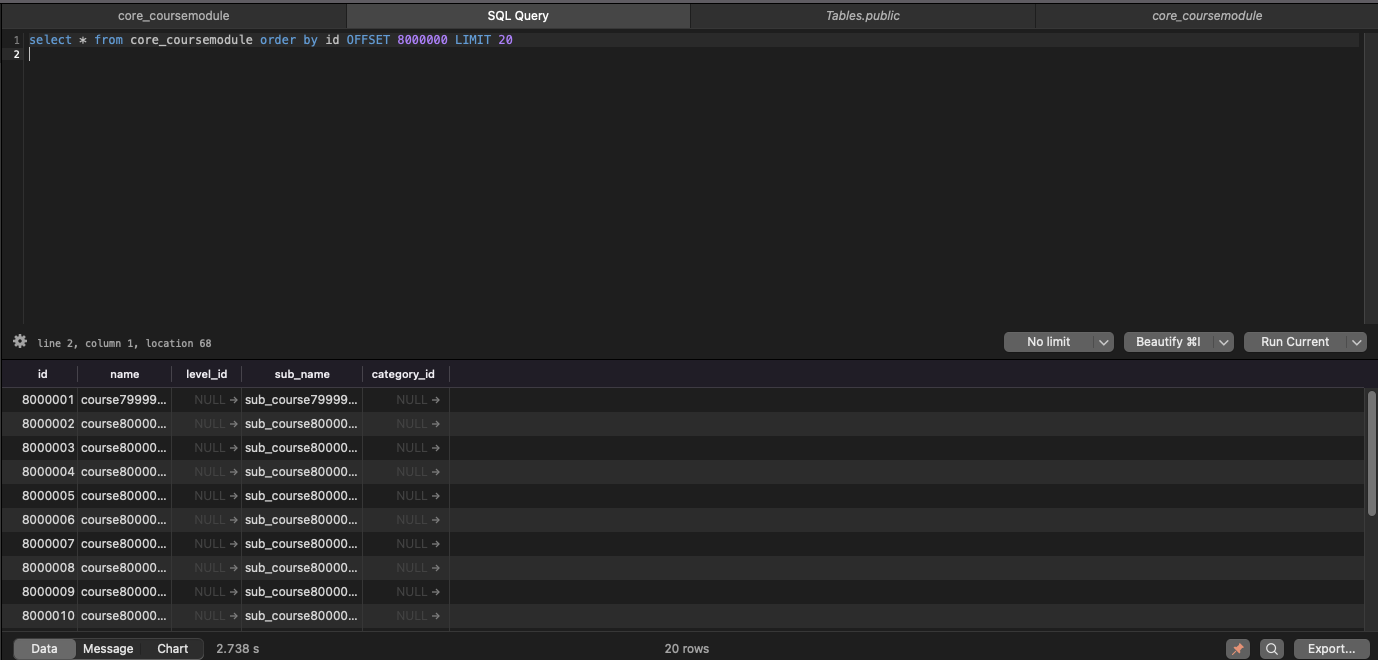
이 쿼리의 실행 시간은 대략 2.7초가 걸렸다. 쿼리 단에서 2.8초면 API 응답시간은 더 느릴테고, 사용자 입장에서 용납하기 힘든 지연시간이다.
왜 이런 현상이 일어날까? 그 이유는 처음에 언급한 OFFSET의 동작 방식 때문이다. OFFSET은 일단 쿼리 조건에 해당하는 모든 row를 읽은 다음 필요한 row를 제외한 나머지를 버리는 방식으로 동작한다. 따라서 테이블에 row가 많은 상황에서 OFFSET 값이 커지면 그만큼 읽을 Row가 많아져 디스크 I/O가 많이 발생해서 느려진다.
다만 데이터가 많아도 OFFSET 값이 작으면 빠르게 읽어올 수 있다. 다음의 쿼리는 실행시간이 얼마 걸리지 않는다.
select * from core_coursemodule order by id OFFSET 1 LIMIT 20 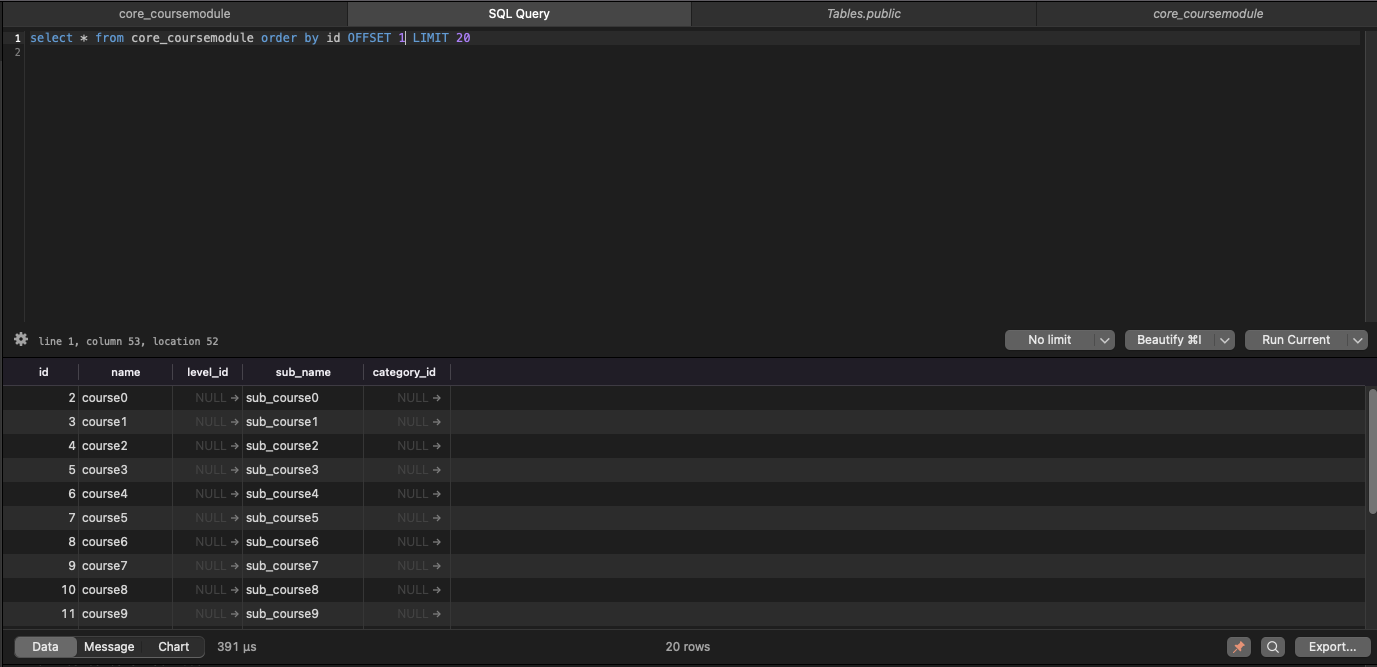
500 us(마이크로초)도 채 걸리지 않는다.
생각해보면 사람들이 많이 이용하는 게시판 서비스의 경우 수 십, 수 백만 개 이상의 게시물이 있어도 일반적으로 대다수의 사람들은 앞에 있는 최신의 게시물을 주로 보는 경우가 많기 때문에 OFFSET 값이 커질 경우는 적지만, 간혹 맨 뒤의 게시물을 보고자 하는 사용자가 있을 수 있다. 그런 경우에는 소수의 사용자들이 실행한 쿼리가 시스템 성능에 영향을 미칠 수 있다. 우리는 이런 워스트 케이스에 대해서도 대비책을 세워놓아야 한다.
다음 두 가지 방법을 사용하여 해결할 수 있다.
해결 방법
No OFFSET
한 가지 방법은 페이지네이션에 OFFSET을 쓰지 않는 것이다. OFFSET 대신 인덱스가 걸린 컬럼을 기준으로 where 절을 활용하면 된다. (이를 커서 기반 페이지네이션이라고 부르기도 한다. )
select 컬럼
from 테이블
where id > 가장 마지막에 읽은 조회 ID
order by id
limit 페이지 사이즈예제 쿼리를 실행해보자.
select * from core_coursemodule where id > 8000000 order by id LIMIT 20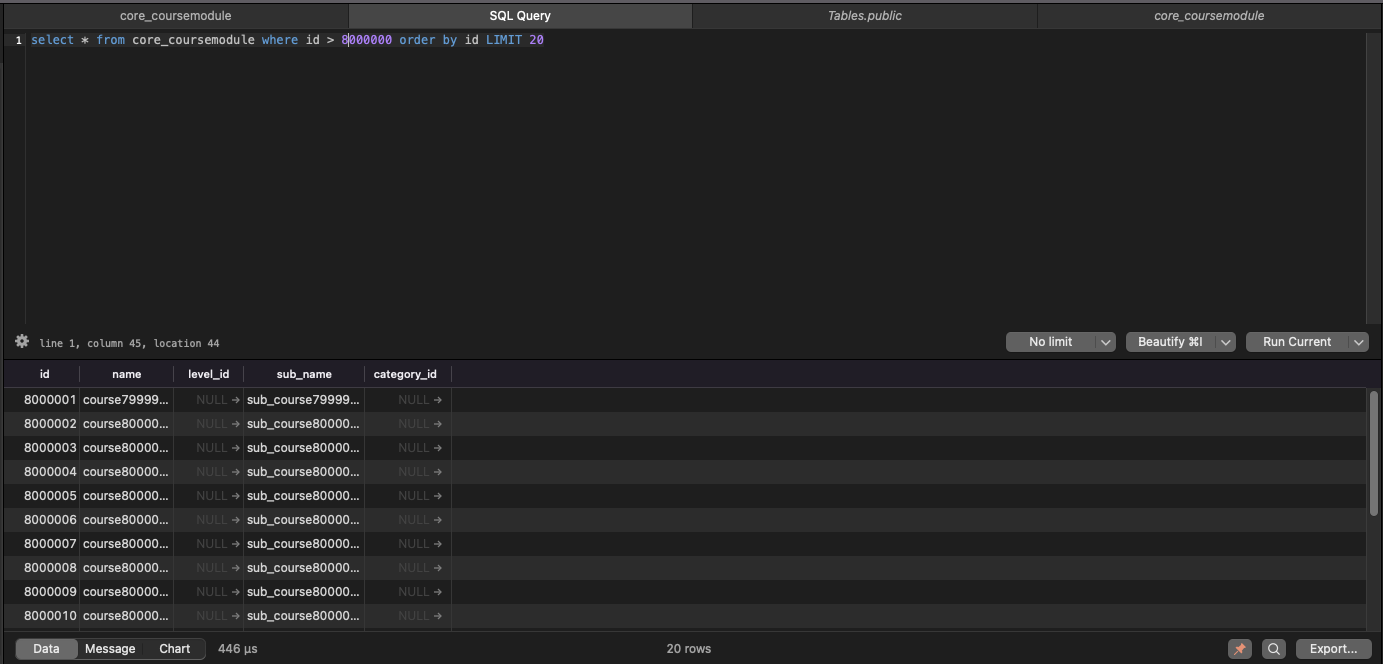
쿼리를 수행하는데 446us 밖에 걸리지 않는다. 인덱스는 검색속도를 최적화하는 자료구조이다. 위에서 id는 pk이므로 인덱스가 걸려있다. where 절에서 인덱스를 활용하니 인덱스 위치를 바로 탐색하기 때문에 훨씬 빠르다.
explain을 통해 쿼리 실행 계획을 살펴보면 index scan을 통해 효율적으로 데이터에 대해 접근하는 것을 알 수 있다.
explain select * from core_coursemodule where id > 8000000 order by id LIMIT 20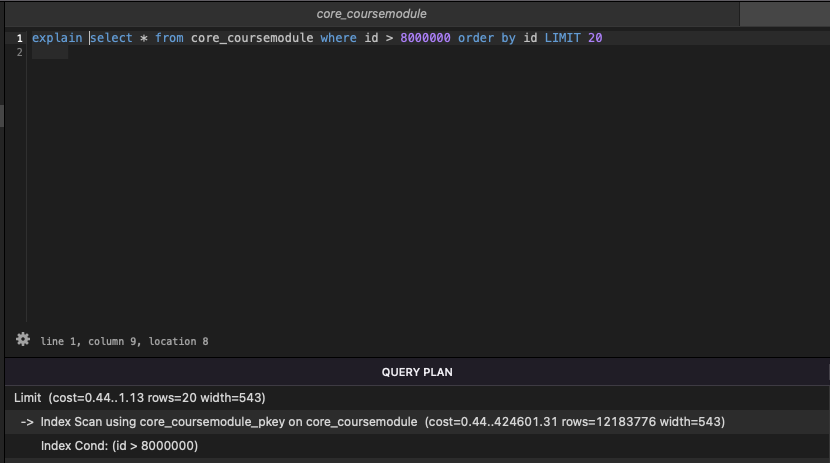
앗 그럼 where 절에 인덱스가 없으면 어떨까? 그래도 OFFSET 방식보단 낫지 않을까? 실험해보자.
core_coursemodule의 컬럼 중 name 컬럼은 인덱스가 걸려있지 않다. 위 쿼리에서 id를 name으로 대체하면 어떤 결과가 나올까?
select * from core_coursemodule where name > 'course144' order by name LIMIT 20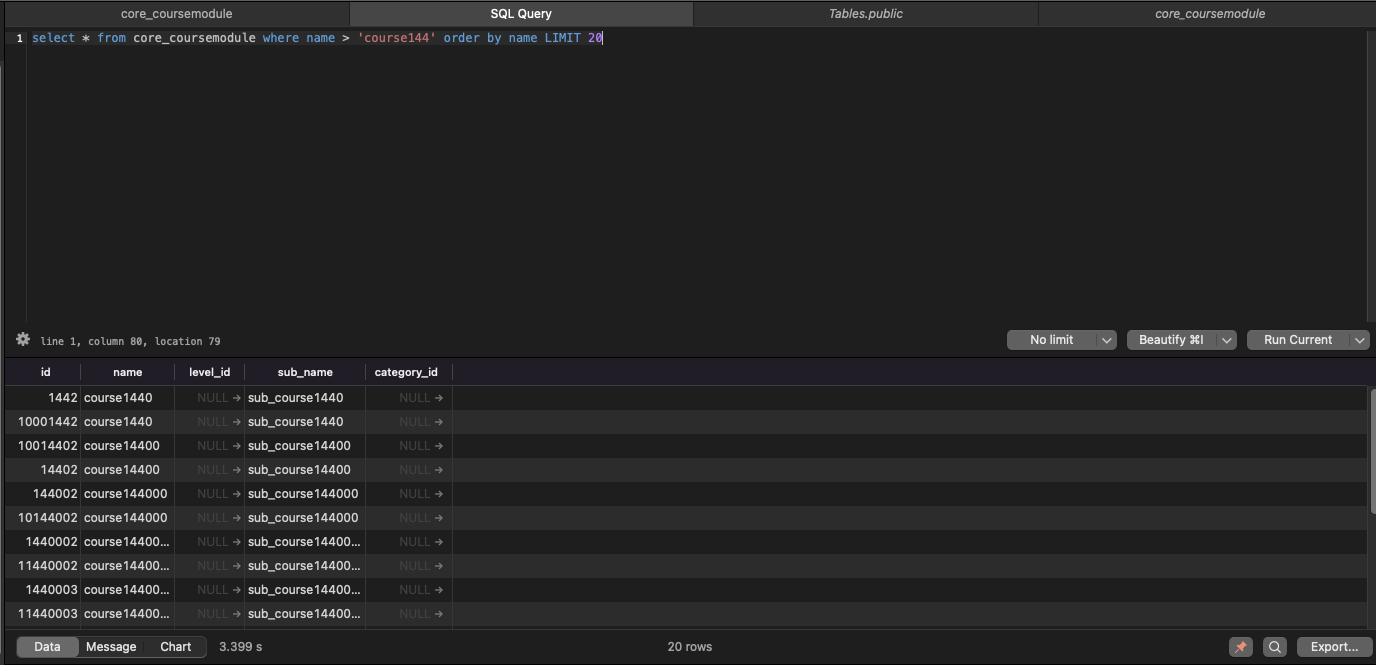
대략 3초가 걸렸다.
쿼리 실행계획을 살펴보면,
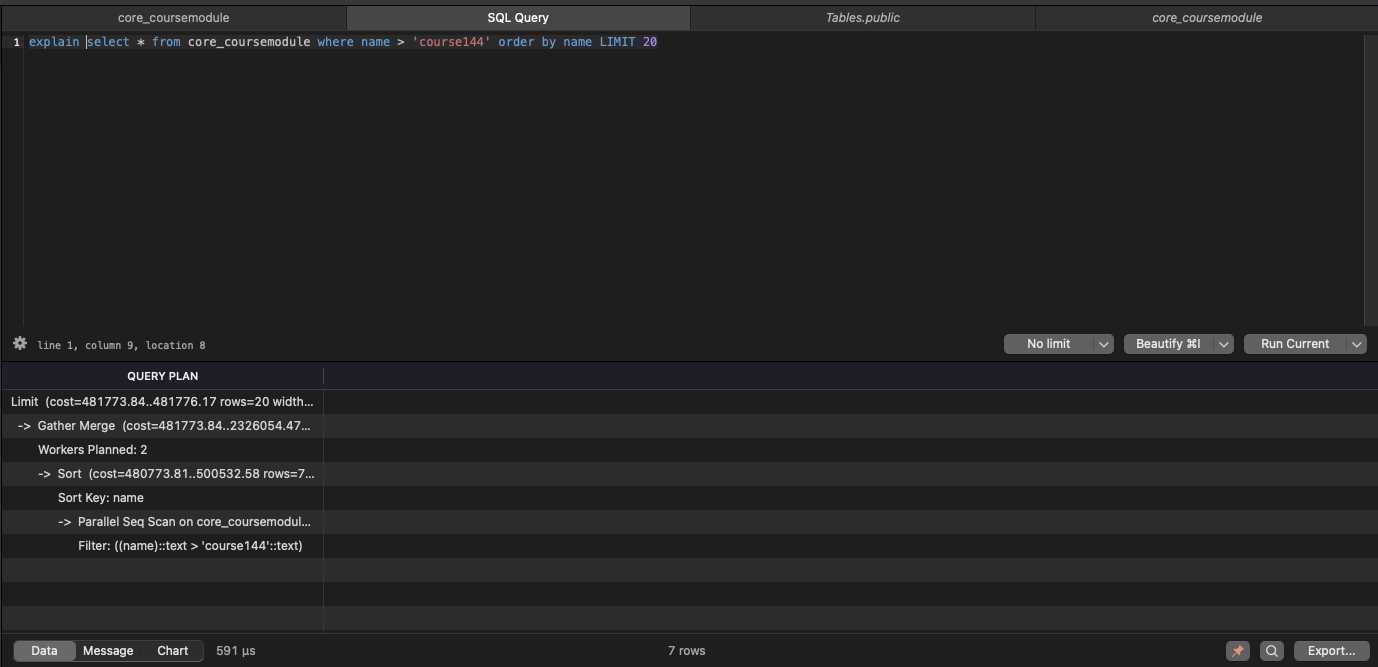
병렬 처리를 위해 Gather Merge 가 사용되며, 인덱스가 적용되지 않았기에 Sort를 먼저 수행하며 pararael seq scan을 통해 쿼리를 실행한다.
즉 where 절이 문제가 아니라, where절과 order by 절에 쓰이는 컬럼의 인덱스 여부가 중요하다.
인덱스를 만들어보자. (데이터 양이 많아서 인덱스 생성하는데 시간이 오래걸렸다)
create index coursemodule_name_index on core_coursemodule(name)인덱스를 만든 후 쿼리를 실행하면..
select * from core_coursemodule where name > 'course144' order by name LIMIT 20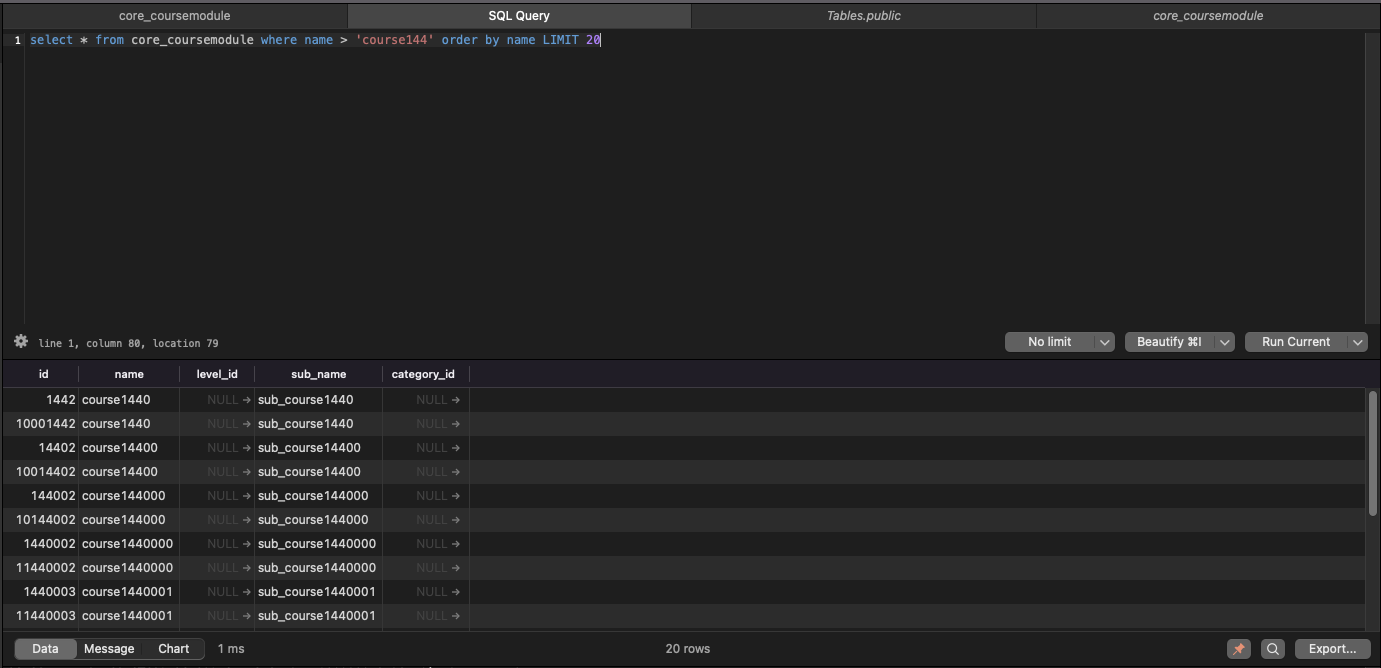
1ms 밖에 소요되지 않았다. 엄청 빨라졌다.
실행 계획을 보면
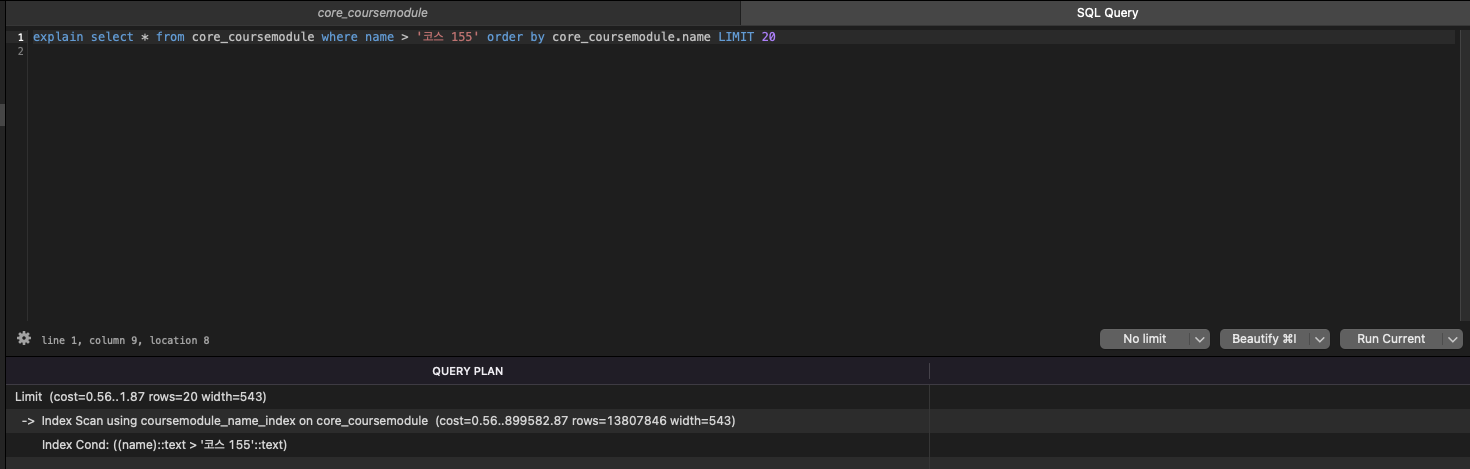
인덱스 스캔을 하기 때문에 훨씬 빨라졌음을 알 수 있다.
커버링 인덱스
처음 소개한 방법은 커서 기반으로 OFFSET이 중요하지 않을 때 사용할 수 있다. 그러나 서비스 기획단에서 OFFSET 값이 필요한 경우도 있다.
이럴 경우 도입해볼 수 있는 방법이 커버링 인덱스이다.
인덱스를 이용해 조회되는 쿼리에 성능 저하를 일으키는 부분은 조회한 row에서 인덱스로 조회하는 컬럼 이외의 나머지 컬럼 값을 데이터 블록에서 읽을 때이다. 따라서 LIMIT, OFFSET 을 쓰는 select 문에 인덱스가 걸린 컬럼만 사용하는 커버링 인덱스를 활용할 수 있다. (다시 말해, OFFSET 값이 많아도 조건에 부합하는 모든 row의 데이터 블록을 읽는 것이 아니라 인덱스 필드만 읽고 난 후 조건에 맞는 row에 한해서만 데이터 블록을 읽기 때문에 커버링 인덱스를 쓰면 효율적이다. )
커버링 인덱스를 쓰는 예시는 다음과 같다.
select * from 테이블 join (select 인덱스 컬럼 from 테이블 order by 인덱스 컬럼 offset x limit y) as c on 테이블.id = c.id;select * from core_coursemodule join (select id from core_coursemodule order by id offset 8000000 limit 10) as c on core_coursemodule.id = c.id;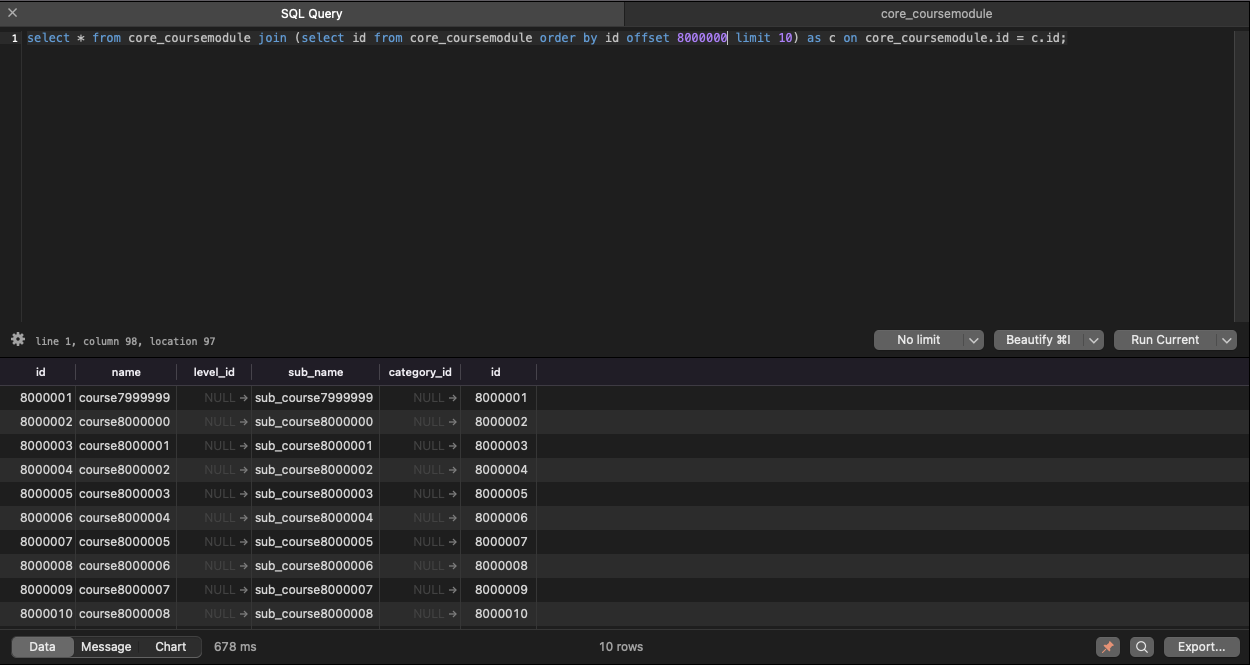
와우 678ms 밖에 걸리지 않았다. 원래 기존 쿼리인 select * from core_coursemodule order by id offset 8000000 limit 10 은 2.7~2.8 초 정도 걸렸는데, 커버링 인덱스를 활용하면 훨씬 더 빨라졌다.
결론
페이지네이션을 적용하다가 호기심에 대용량 데이터 상황을 가정하여 효율적인 페이지네이션을 위한 여러가지 방법을 알아보고 적용해보았다. 자신이 개발하고 있는 애플리케이션 상황에 맞게 적용하면 될 것 같다.
대규모 데이터 조회인데, OFFSET 이 필요 없다 → No OFFSET 방법이 가장 빠르고 효율적이다.
대규모 데이터 조회인데, OFFSET 이 필요 하다. → 커버링 인덱스
소규모 데이터 조회이다. → LIMIT, OFFSET (개발이 가장 빨라요)
대규모 데이터를 조회함에 있어서 인덱스는 필수라는 생각이 들었다. 인덱스에 대해 더 공부해봐야지..