오늘은 사내 서비스 운영 중 재미있는 이슈를 발견해서 포스팅해보려고 한다. 우리 서비스는 사용자가 요청한 머신러닝 모델 학습을 제공하는 웹서비스이다. 머신러닝 모델은 CPU를 100프로 사용하거나 GPU를 사용해야하기 때문에 별도의 머신 (worker)에서 학습을 처리하고, 일반적인 백엔드 요청은 또 다른 머신에서 처리한다. 머신러닝 모델을 학습하는 데 오랜 시간이 걸리기 때문에 이 두 서비스 간의 커뮤니케이션 수단으로 비동기 커뮤니케이션 방법 중 하나인 메시지 큐(우리의 경우 GCP pub/sub)를 사용한다. pub/sub을 통해 사용자의 머신러닝 모델 훈련을 트리거 하는데, Sentry에서 이미 학습이 트리거 된 파이프라인이 또 다시 트리거 되어 에러가 발생하였다는 보고가 들어왔다.
오류의 원인을 파악하기 위해 서버 로그와 로직을 분석하였다. Front-end, Back-end 에서는 중복된 모델 학습 요청에 대해서 DB 안의 파이프라인 데이터를 기준으로 방어할 수 있었다. 그래서 서버 로그를 보니 다음과 같이 짧은 시간 내에 동일한 메시지가 서로 같은 주제를 구독하고 있는 구독자 worker들로 부터 두 번 처리된 로그를 볼 수 있었다.

한번만 처리되어야 하는 파이프라인 request가 두 개의 다른 pod에서 중복 처리 되었다.
예전 마이크로 서비스 아키텍쳐 책에서 메시지 큐를 사용했을 때 중복 메시지 처리에 대한 부분을 다루었었다.
근데 막상 친한 개발자 형한테 물어보거나, 실제로 중복 메시지가 발생하는 경우가 있는지? 를 구글에 쳐봤을 때 그런 경우는 거의 없다~ 라고 많이 답변을 들었던 것 같아서 찜찜했었는데 실제 내가 운영하는 도중 이 이슈를 직접 발견할 수 있어서 찜찜함이 풀렸다.
신나서 이 이슈를 등록하고 다른 동료 개발자에게 설명하자, 이전에 처리했었던 이슈라고 하셨다. ㅠ.ㅠ 코드를 대대적으로 리팩토링하면서 해당 처리에 대한 부분이 없어졌던 것 같다.
ML worker들의 머신러닝 모델의 작업 상태를 관리하기 위한 PipelineTrainingTask라는 모델이 있다. 이전까지는 머신러닝 워커에서 요청 메시지를 읽은 다음(구독) 모델의 진행상황을 업데이트할 때 row lock을 걸어서 해결하고 있었다. 코드는 아래와 같다.
with transaction.atomic():
task = cls.objects.select_for_update(nowait=True).get(
uid=uid, pipeline=pipeline
)곰곰히 생각을 해보았다. 우리 서비스에서 ML worker들이 처리하는 작업의 종류는 여러가지가 있고, 각각의 작업은 조금씩 상이하기 때문에 다른 DB 모델로 관리된다. DB 모델마다 중복메시지를 처리하기 위해 저 로직이 있는 것이 좋은 구조일까? 한발짝 더 나아가서 생각해보면 Infra Layer에 존재하는 문제를 Domain Layer에서 해결하는 것이 맞는걸까? 라는 생각이 들었다. 위와 같이 문제를 해결하면 코드의 유지보수가 어려워질 것이라는 생각이 들었다.
그래서 나는 MSA Book을 참고해서 처리한 메시지를 보관하는 DB 테이블을 만들었다. 그리고 pubsub에서 메시지의 id는 토픽 별로 uniquness가 보장되기 때문에 DB 테이블의 구조는 다음 처럼 설계하였다.
- Processed Message
| Topic | Message Id |
|---|---|
| light-task | 1 |
| heavy-task | 2 |
그리고 topic, message id에 unique constraint를 걸었다.
subscriber의 콜백 핸들러를 아래와 같이 작성하였다.
def _callback_handler(self, message: Message):
try:
# Message has unique id with in the same topic.
# Ref: https://cloud.google.com/pubsub/docs/reference/rest/v1/PubsubMessage
# In this project, we use the same key for topic and subscription.
ProcessedMessage.objects.create(
topic=self._subscription, message_id=message.message_id
)
# load paload
data = json.loads(message.data.decode("utf-8"))
message.ack()
# run task
task = TaskRunner.get_task(name=data.get("name"), data=data, logger=logger)
task.run()
# Pubsub duplication error
except IntegrityError as e:
logger.exception(e)TaskRunner는 메시지의 json payload에 따라 task를 처리하는 클래스이다. 이 안에서 task_name에 따라서 데이터 모델의 처리를 위임한다. 이 안에서의 로직은 도메인 모델이 담당하는 영역이다. 위에 ProcessedMessage를 생성할 때 unique constraint를 지정하였기 때문에 중복 메시지가 발생한다면 IntegrityError가 발생하게 되어 중복된 요청에 대한 중복된 처리를 방지할 수 있다. (중복 메시지 처리에 대해서, 이 방법 말고 멱등성 있는 핸들러를 작성하는 방법도 있지만 대부분의 애플리케이션의 경우 멱등성 있는 메시지 핸들러를 작성하긴 쉽지 않다. 우리 애플리케이션은 더욱 그렇다.)
위와 같이 코드를 작성하면 다른 개발자가 pub/sub “중복 메시지” 이슈에 대해 인지하기 쉽고, 그 문제를 AOP 처럼 분리하였기 때문에 유지보수가 쉬워진다는 장점이 있다고 생각하였다. (피어 리뷰 한번에 Approval 받았다 ㅎㅎ)
Google Pub/sub 환경에서 메시지 id가 어떻게 저장되는지 보려고 dev환경에 올려보았다.
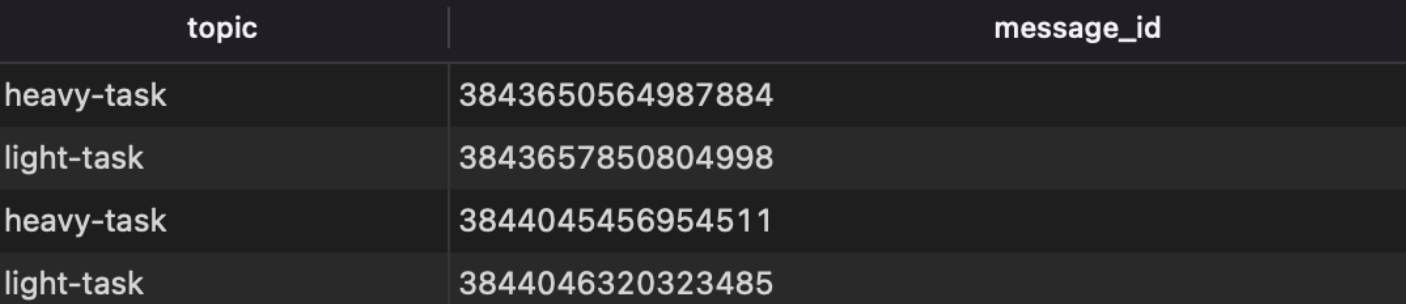
오 12자리의 string형태로 message id가 생성되어 저장된 것을 볼 수 있었다.
GCP Pub/sub 공식 문서에 따르면 다음과 같이 써있다.

이미 문서에 메시지가 중복 전달 될 수 있다고 경고해 두었다... 나는 구독자에게 멱등성을 부여하기 보다는 DB에서 제공하는 unique constraint를 사용하여 중복 메시지 문제를 해결하였다.
다른 메시지 큐 구현체는 제대로는 써보지 않아서 중복 메시지 이슈가 있는지는 모르겠다. (아마 있을 것 같다.) 구현체를 쓰기전에 꼭 문서를 읽어보고 중복 메시지 이슈를 핸들링 할 수 있는 방안을 모색해야겠다.