점점 복잡한 쿼리를 짜다보니 SQL 최적화에 관심이 많아졌다. 인덱스든 뭐든 DB부하를 최적화하려면 기반 원리를 알아야겠다는 생각해 공부한 내용을 정리하려고 한다.
SQL이 느린 이유?
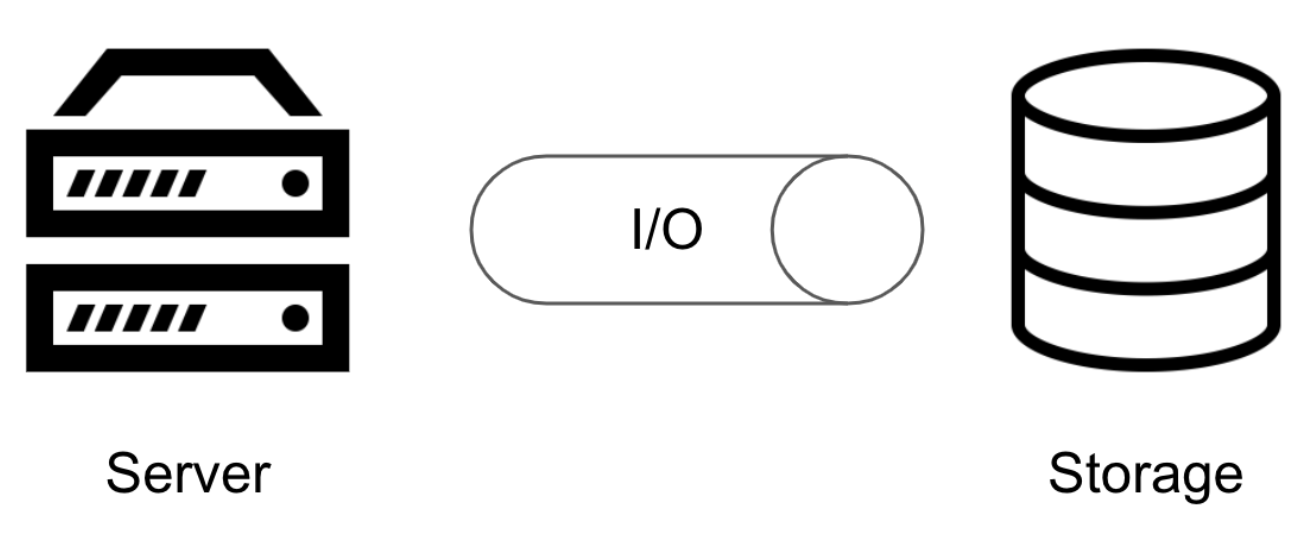
일단 SQL이 느린 이유는 무엇일까? 컴퓨터 구조 과목을 배우던 때를 기억해보자. 디스크 I/O는 느리기 때문에 컴퓨터는 메모리 혹은 레지스터를 활용하였다. DB역시 마찬가지이다. DBMS는 DB서버와 스토리지로 나뉘는데 스토리지에서 데이터를 읽어올 때 디스크 I/O 가 발생한다. I/O가 발생하면 프로세스는 대기 큐에서 sleep하고 있기 때문에 I/O가 많아지면 성능이 느려질 수 밖에 없다. 결국 본질적으로 SQL을 최적화 한다는 것은 DISK I/O를 줄이는 것을 의미한다.
데이터 베이스의 데이터 저장 구조
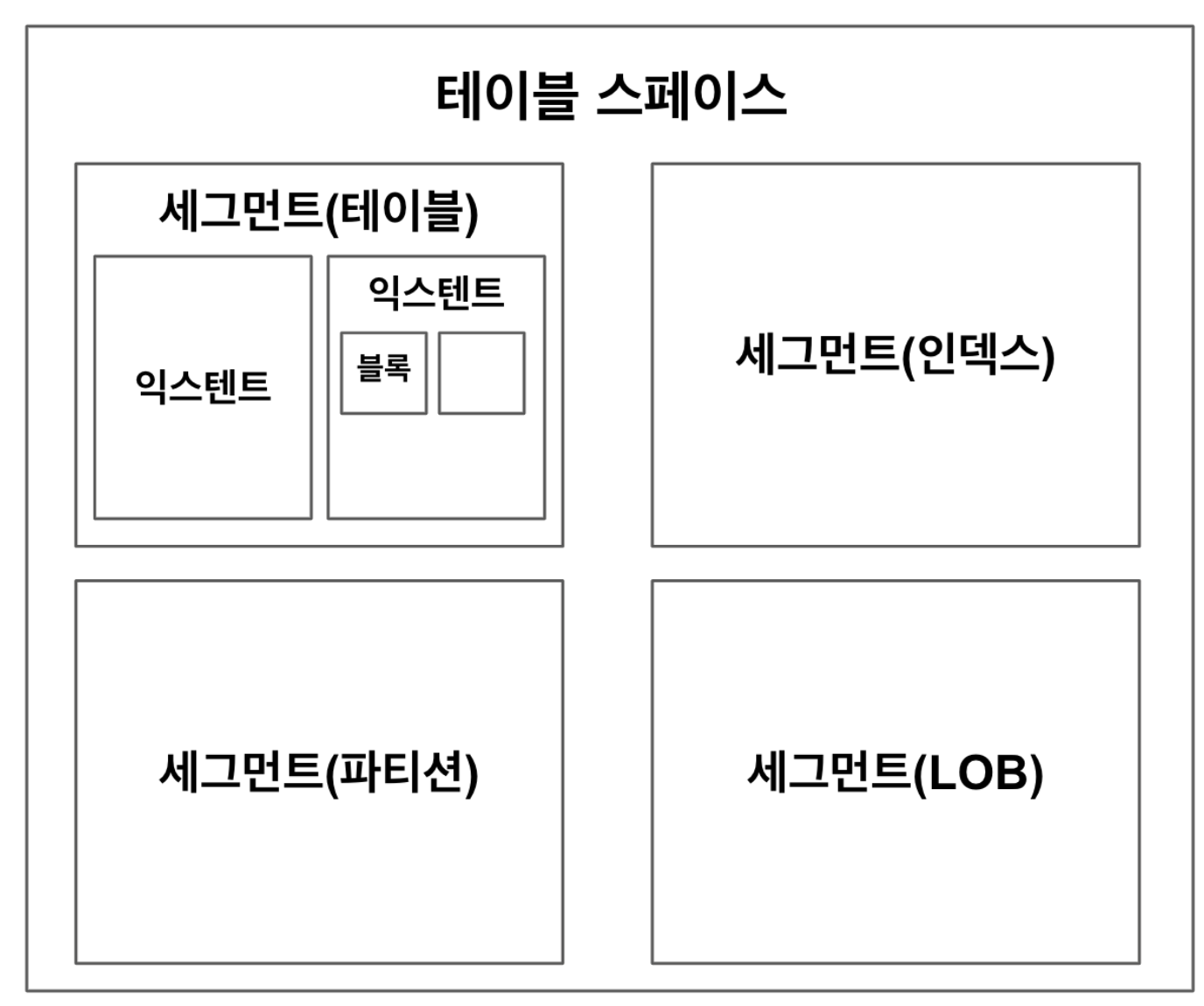
데이터베이스는 다음과 같은 구조로 데이터를 저장한다.
- 테이블 스페이스 : 데이터를 저장하는 공간이다. 여러 개의 세그먼트를 담는다.
- 세그먼트 : 테이블, 인덱스, 파티션 등 데이터 저장공간이 필요한 오브젝트이다.
- 익스텐트 : 연속된 블록들의 집합이다.
- 블록 : 사용자가 입력한 레코드가 실제로 저장되는 공간이다. 데이터베이스에서 데이터를 읽고 쓰는 기본 단위 이다. 아무리 소수의 데이터를 읽고 싶어도 데이터를 읽는 단위는 블록이기 때문에 원하는 데이터가 있는 블록을 통째로 읽어야 한다.
데이터 액세스 방법
테이블 또는 인덱스 블록을 읽는 방식으로는 시퀸셜 액세스와 랜덤 액세스가 존재한다.
- 시퀸셜 액세스 : 논리적 혹은 물리적으로 블록들이 연결된 순서에 따라 차례대로 블록을 읽는 방식이다.
- 랜덤 액세스 : 레코드 하나를 읽기 위해 한 블록씩 접근하는 방식이다. 인덱스를 통해 데이터를 읽을 때 사용되는 방식이다.
이와 관련되어 데이터를 스캔하는 방식은 다음과 같다.
- Table Full Scan : 테이블에 속한 블록 전체를 읽어서 사용자가 원하는 데이터를 찾는 방식이다. 시퀸셜 액세스를 통해 읽는다.
- Index Range Scan : 인덱스에스 일정량을 스캔하면서 얻은 ROWID로 테이블 레코드를 찾아가는 방식이다. 랜덤 액세스를 통해 읽는다.
논리적 I/O 와 물리적 I / O
디스크 I/O가 SQL의 성능을 결정한다. SQL을 최적화하기 위해 DISK I/O를 줄여야 한다. DBMS에는 DB 버퍼 캐시가 있으며, 디스크에서 읽은 데이터블록을 캐싱해두어서 I/O콜을 줄일 수 있다. I/O 기준을 잡을 때 두 가지 개념이 존재한다.
- 논리적 I/O
SQL을 수행하면서 읽은 총 블록 I/O이다.
- 물리적 I/O
SQL을 수행하면서 디스크에서 발생한 총 블록 I/O를 말한다.
Single Block I/O와 Multi Block I/O
- Single block I/O
한 번에 한 블록 씩 요청해서 메모리에 적재하는 방식을 Single Block I/O라고 한다. 인덱스를 통한 소규모 데이터를 읽을 때 사용된다.
- Multi Block I/O
한번에 여러 블록 씩 요청해서 메모리에 적재하는 방식을 Multi Block I/O라고 한다. 대량으로 데이터를 읽을 때 유용하다.
인덱스는 항상 빠르지 않다.
일반적으로 우리는 인덱스를 쓰면 조회할 때 성능이 올라가는 것으로 알고 있다. 그 이유는 인덱스는 특정 조건에 맞는 데이터를 B+트리와 같은 자료구조를 통해 단 시간에 빠르게 찾을 수 있기 때문이다.
그러나 인덱스 컬럼의 조건에 맞는 데이터 양이 전체 데이터 양에 꽤 많은 portion을 차지하고 있다면 인덱스를 통한 Index Range Scan(랜덤 액세스)가 인덱스를 사용하지 않고 전체 테이블 블록을 읽어오는 Full Scan보다 느릴 수 있다.
Table Full Scan은 Multi Block I/O 방식으로 디스크 블록을 읽는다. 한 블록에 속한 모든 레코드를 한번에 읽어들이고, 캐시에서 못 찾으면 한 번의 IO를 통해 인접한 수십 수백개의 블록을 한번에 I/O하는 메커니즘이다.
Index Range Scan을 통한 테이블 액세스는 랜덤 액세스와 SIngle Block I/O 방식으로 디스크 블록을 읽는다. 캐시에서 블록을 못찾으면, 레코드 하나를 일기 위해 매번 잠을 자는 I/O 메커니즘이다. 즉 많은 데이터를 읽을 때 Table Full Scan 보다 불리하다. 또 읽었던 블록을 반복해서 읽기 때문에 비 효율적이다.
참고자료 : 친절한 SQL 튜닝