개요
마이크로 서비스 아키텍처에서는 여러 서비스들이 서로 다른 네트워크 엔드 포인트들을 가지고 있다. 또 각 서비스들은 여러 노드들로 구성되기 때문에 이 모든 서비스들에 대한 네트워크 정보를 저장하고 관리해야 한다.
클라우드 컴퓨팅 환경의 도입에 따라 각 서비스들은 동적으로 scale out 할 수 있게 되었다. 또 K8s와 같은 컨테이너 오케스트레이션 시스템을 도입한 경우 pod의 생명주기는 짧기 때문에 각 애플리케이션의 네트워크 엔드포인트는 유동적이다. 단일 클라이언트 혹은 단일 서비스에서 수십 ~ 수백 개의 서비스들의 네트워크 엔드 포인트를 일일히 관리한다면 개발자 혹은 운영자의 부담이 너무 커질 것이다.
서비스 디스커버리
서비스 디스커버리는 이러한 문제를 해결하기 위한 패턴이다. 서비스 디스커버리는 두 종류가 존재한다.
Client-side Discovery
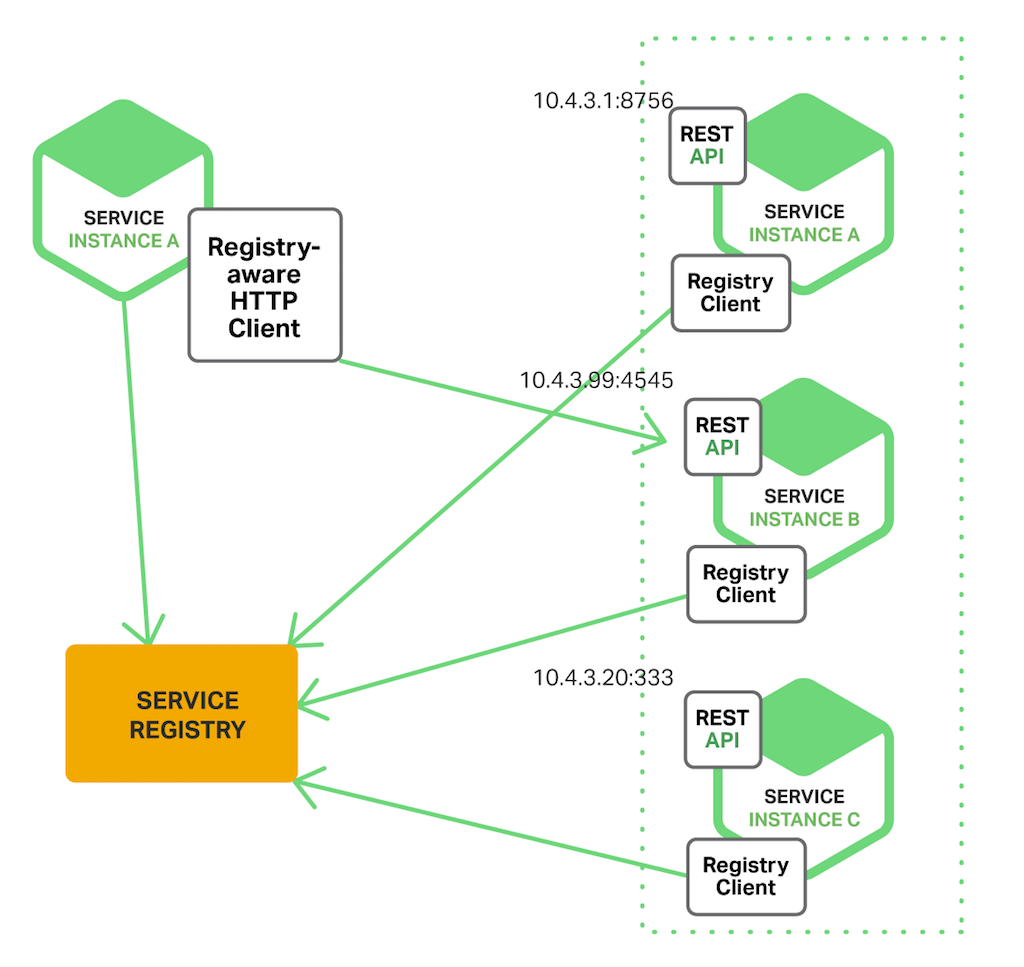
Client-Side Discovery에서는 Service Registry라는 별도의 서버가 존재한다. MSA의 각 서비스들은 Service Registry에 자신의 네트워크 Endpoint를 등록한다.
서비스 클라이언트(여기서 서비스 클라이언트는 MSA의 타 서비스이다. 프론트엔드를 의미하는 것은 아니다. 모바일 혹은 프론트엔드의 경우는 API Gateway를 통해 서비스를 호출하도록 해야 한다.)가 다른 서비스를 호출할 때는 Service Registry로 부터 타 서비스의 네트워크 Endpoint를 조회한 후, 자기가 직접 해당 서비스를 호출한다.
- Pros
- 서비스 클라이언트가 사용 가능한 서비스를 알고 있기 때문에 각 서비스별 로드 밸런싱 방법을 선택할 수 있다.
- 네트워크 Hop이 Server-side Discovery에 비해 적다.
- Cons
- 서비스 클라이언트에서 사용하는 서비스 검색 로직을 언어 및 프레임워크마다 구현해야 한다.
Sprint Cloud Eureka는 대표적인 Client-side service discovery이다. 다만 Spring Cloud Eureka를 도입하게 되면 전체 서비스들이 Spring 기반의 애플리케이션으로 구현되어야 한다는 문제점을 가지게 된다. 즉 Spring Cloud Eureka라는 핵심 비즈니스 로직과 관련 없는 라이브러리에 종속되게 된다.
Server-side Discovery
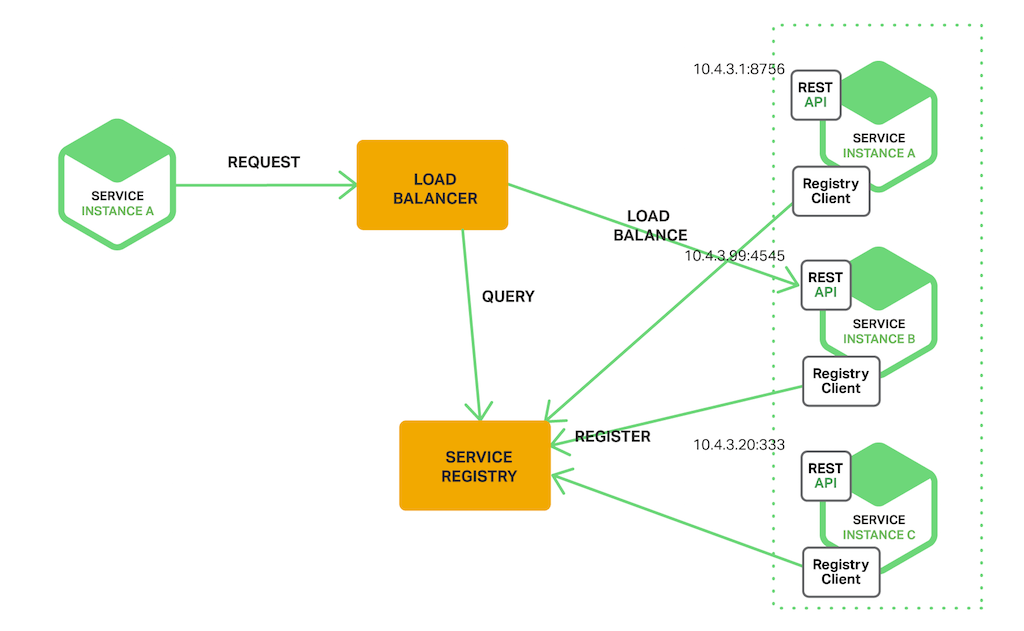
호출되는 서비스들 앞에 로드 밸런서를 둔다. 서비스 클라이언트는 Service Registry를 직접 호출하는 것이 아니라, 로드 밸런서를 통해 호출하고, 로드 밸런서는 등록된 Service Registry로부터 정보를 조회해서 라우팅하고 결과를 반환한다.
- Pros
- 서비스 디스커버리 구현의 세부 사항이 클라이언트로부터 캡슐화되어 있다.
- 클라이언트 입장에서 Client-side Discovery와 달리 서비스 검색 로직을 구현하지 않아도 된다.
- Cons
- 로드밸런서가 제공되어야 한다.
- Client side에 비해 네트워크 hop이 증가한다.
대표적으로 쿠버네티스에서 Server-side discovery 를 제공한다. 쿠버네티스는 서비스 라는 개념을 제공하여, 각 서비스 간 네트워크 엔드포인트를 추상화하여 제공한다. (참조 : 쿠버네티스 문서) Pod 혹은 Deployment 에 서비스를 등록하면 해당 오브젝트들에 고유한 IP 주소들과 단일 DNS 명을 부여해준다. 타 서비스 클라이언트에서는 정의된 서비스의 이름으로 생성된 DNS 명을 호출하면 서비스가 인스턴스의 개수와 상관 없이 알아서 로드밸런싱을 해주게 된다.
어떤 것을 써야할까?
당연한 말이지만 정답은 없다. 전체 시스템 자체가 Polyglot 프로그래밍 형태로 구성되어 있다면 Client-side Discovery는 각 서비스 클라이언트가 사용하는 언어 및 프레임워크마다 요청 로직을 구현해야하기 때문에 이런 경우에는 Server-side Discovery 방식을 도입하는게 더 좋을 것 같다.
그러나 MSA 서비스 전체가 Spring Cloud 기반으로 개발되어 있다면, 네트워크 hop을 줄일 수 있는 Client-side Discovery를 사용하는 것을 고려해볼 수 있을 것 같다.
상황에 따라 유연하게 어떤 방법을 쓸지 고민해보면 좋을 것 같다.