개요
기존의 모놀리식 아키텍처 여러 개의 독립된 DB를 가진 서비스로 분해시킨 마이크로 서비스 아키텍처 에서는 데이터를 효율적으로 쿼리하기 위한 고민이 필요하다. 모놀리식 아키텍처 에서는 DB가 하나 뿐이기 때문에 개발자는 데이터를 쿼리하기 위해 적절한 인덱스를 설정하고 SQL문만 작성하면 되었다. 그러나 마이크로 서비스 아키텍처에서는 여러 서비스 여러 DB에 분산된 데이터를 쿼리해야 하기 때문에 쉽게 데이터를 쿼리할 수 없다.
이 문제를 해결하기 위한 두 가지 패턴을 소개하고자 한다.
API 조합 패턴
서비스 클라이언트가 데이터를 가진 여러 서비스를 직접 호출해서 그 결과를 조합하는 패턴이다.
배달 앱 서비스가 있다고 가정하자. 배달 앱 서비스는 주문, 주방, 배달, 회계 서비스로 분리되어 있다. 우리가 주문 정보를 조회하기 위해서 findOrder() 쿼리를 수행한다고 했을 때는 아래 그림과 같이 네 개의 서비스의 데이터가 전부 필요하다.
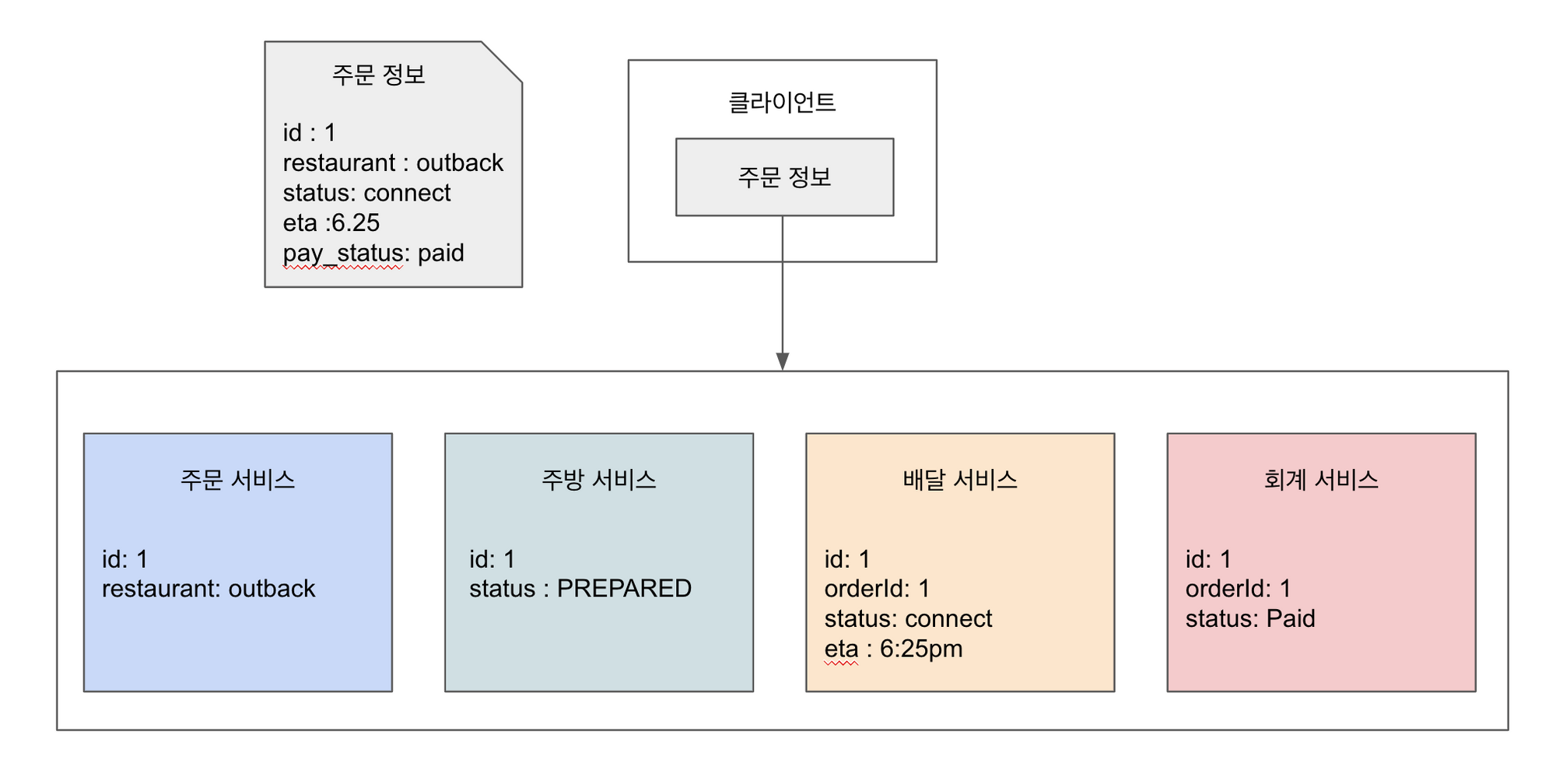
모놀리식 아키텍처의 경우 각 도메인 모델의 데이터들을 조인해서 주문 정보를 뽑아오면 되기 때문에 어렵지 않다. 그러나 위 그림과 같이 데이터가 여러 서비스에 분산되어 있는 경우 클라이언트가 단일 주문 정보를 조회하기 위해 여러 서비스에 요청해야 한다.
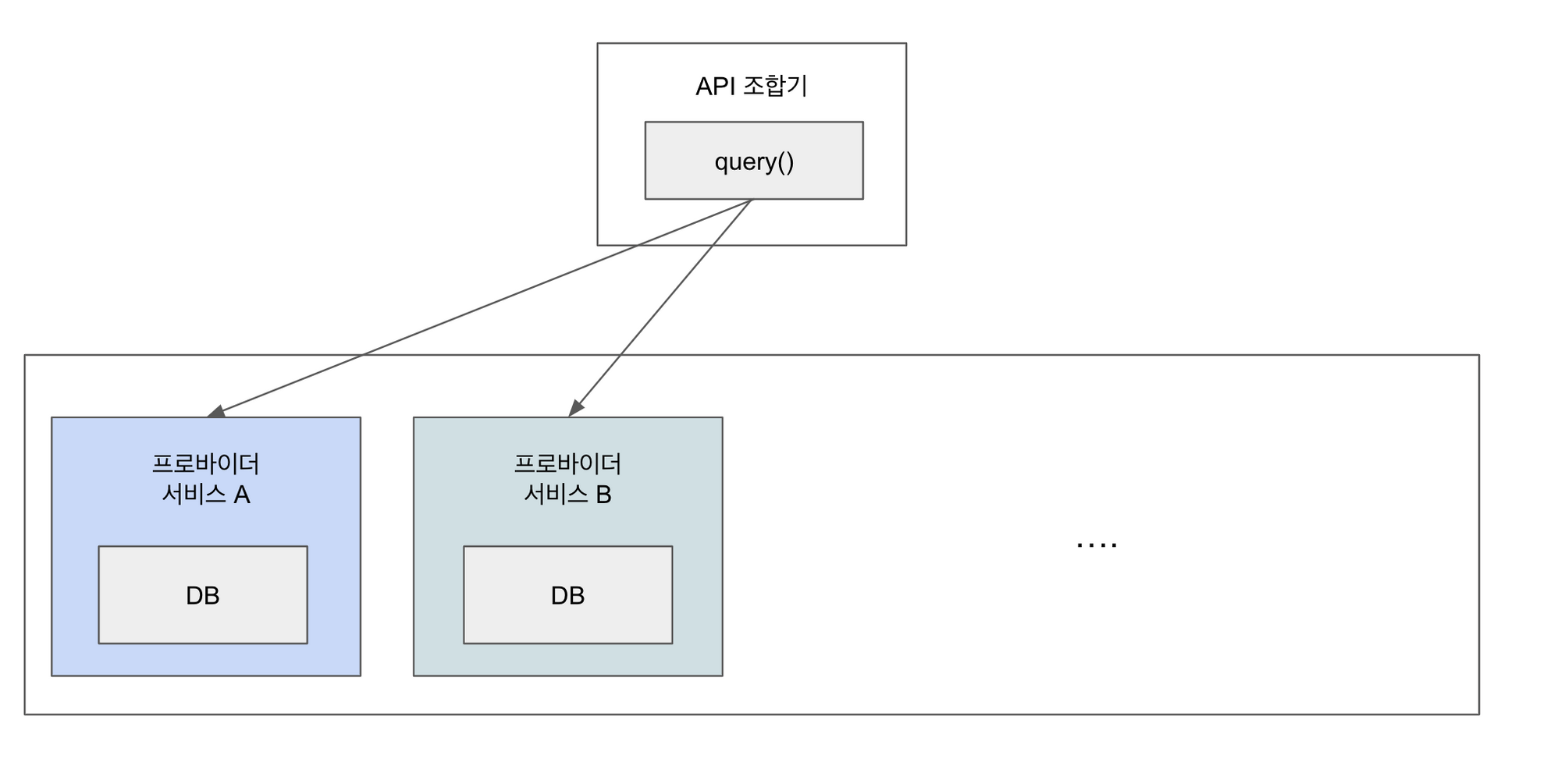
API 조합 패턴은 여러 프로바이더 서비스로 부터 데이터를 받아와서 API 조합기에서 데이터를 조합한 후 결과를 리턴한다. 이 때 주문 서비스 등 데이터를 제공하는 서비스를 프로바이더 서비스라고 부른다.
이때 API 조합기는 어디에서 구현될까? 3가지 선택 옵션이 있다.
- 서비스 클라이언트 (ex 웹 프론트엔드)
웹 프론트엔드와 같은 서비스 클라이언트가 여러 서비스를 호출해서 데이터를 조합할 수 있다. 다만 이 패턴은 네트워크 지연 문제 및 프론트엔드가 백엔드의 내부 서비스 구조를 상세히 알아야 한다는 문제점이 발생한다. (네트워크 엔드포인트는 어떻게 관리할 것이며..)
- API 게이트웨이
API 게이트웨이에 API 조합 로직을 구현하는 방법이다. 모바일 기기와 같이 클러스터 방화벽 외부에서 접근하는 클라이언트가 API 호출 한번으로 여러 서비스의 데이터를 효율적으로 조회할 수 있다.
- Standalone 서비스
여러 서비스의 데이터를 쿼리하는 책임을 가진 독립적인 서비스를 하나 구축하는 것이다. 내부적으로 여러 서비스가 사용하는 쿼리 작업이라면 이 방법이 좋을 수 있다. API 게이트웨이에 붙이기에 조합 로직이 너무 복잡해진다면 고려해볼 수 있다.
API 조합기 구현 시 주의점
API 조합기는 여러 서비스를 네트워크를 통해 호출하기 때문에 반응 속도가 지연되는 문제가 필연적으로 생긴다. 이 지연을 최대한 줄이기 위해서는 가능한 API 조합기는 각 서비스들을 병렬 호출해야 한다. 그러나 도메인의 특성에 따라서 순차 호출이 되어야 하는 경우도 있는데, 이렇게 될 경우 순차/병렬 호출 로직이 뒤섞이기 때문에 관리가 어려워진다. 관리가 용이하고 성능/확장성을 우수하게 가져가려면 리액티브 프로그래밍 모델을 활용할 수 있다. (ex. Rxjava)
단점
- 오버헤드 증가
여러 서비스를 호출하고 여러 DB를 쿼리해야하는 오버헤드는 불가피하다. 컴퓨팅/네트워크 리소스가 더 많이 소모된다.
- 가용성 저하 우려
하나의 쿼리 서비스를 제공하기 위해 3 개의 서비스를 호출해야 한다면 일반 모놀리식 서비스에 비해 가용성이 떨어질 수 밖에 없다.
가용성을 높이기 위해서는 특정 프로바이더 서비스가 불능일 때 이전에 캐시된 데이터를 반환하게 하거나, 아니면 미완성된 데이터를 리턴하도록 할 수 있다.
CQRS(Command and Query Responsibility Segregation) 패턴
쿼리 만을 지원하는 하나 이상의 뷰 전용 DB 및 서비스(모듈)를 유지하는 패턴이다. CQRS는 다음의 경우에 유용하다.
- API 조합 패턴으로는 효율적으로 구현할 수 없는 복잡도 높은 쿼리가 많다. (ex. 여러 서비스에 흩어진 데이터를 조회하기 위한 다량의 비효율적인 인-메모리 조인 발생)
- 데이터를 가진 서비스가 필요한 쿼리를 효율적으로 지원하지 않는 DB를 가지고 있다. (Ex. 지리정보 조회)
- 관심사 분리의 필요성 → 데이터를 가진 서비스가 쿼리 작업을 구현할 장소로 적합하지 않음.
CQRS는 데이터 모델과 그 것을 사용하는 모듈 자체를 커맨드와 쿼리 두 파트로 나눈다. 조회(Read) 기능은 쿼리 쪽 모듈 및 데이터 모듈에 구현하고, 생성/수정/삭제 기능은 커멘드 쪽 모듈 및 데이터 모델에 구현하는 것이다. 양 쪽 모듈이 분리되어 있기 때문에 데이터 모델의 동기화가 필요한데, 커멘드 쪽에서 발생한 이벤트를 쿼리쪽에서 구독해서 DB에 반영하는 식으로 이루어진다. 아래 그림을 보자
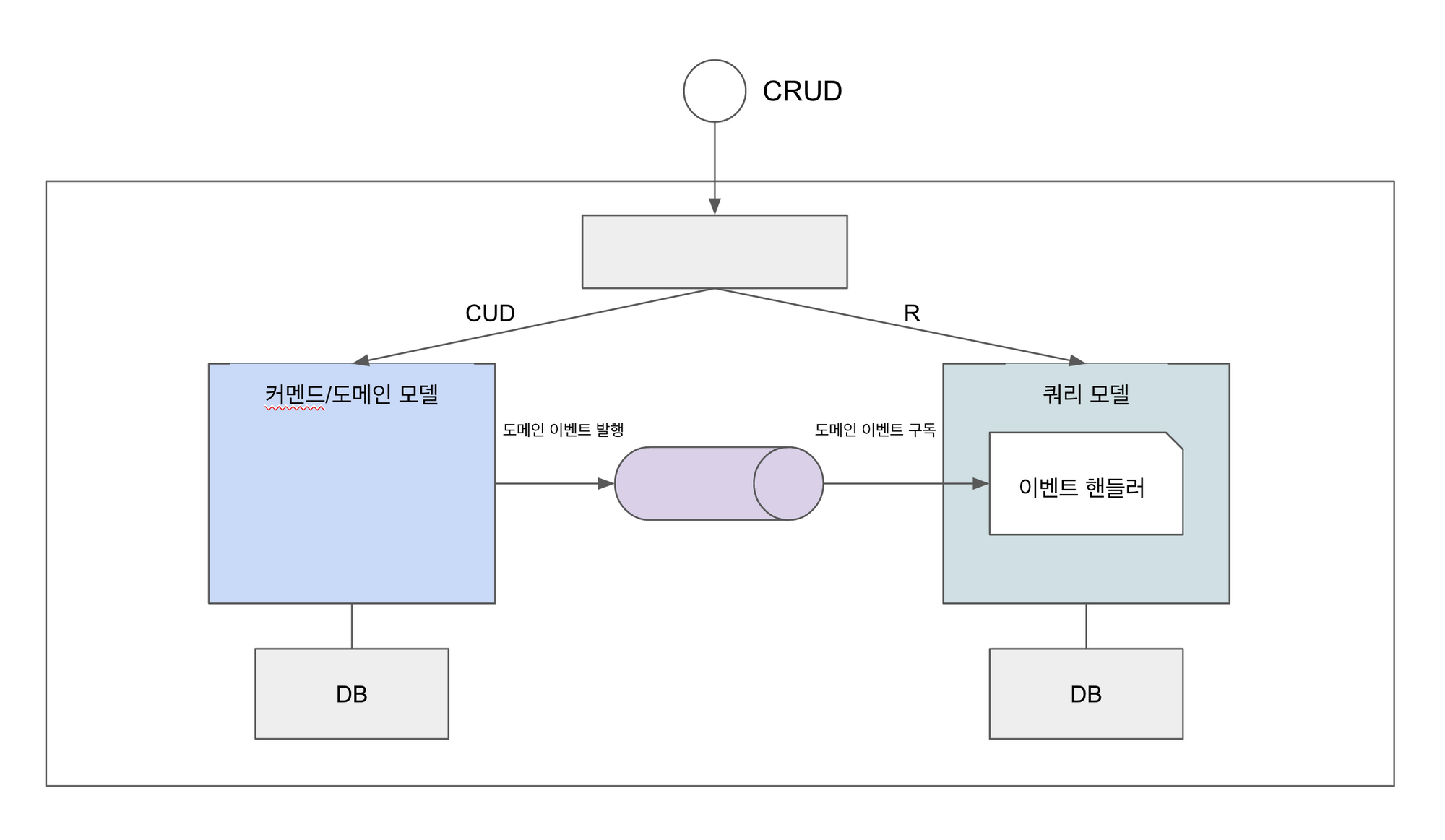
커멘드 쪽에서는 데이터가 변경될 때마다 도메인 이벤트를 발행하고, 쿼리 모델에서는 해당 도메인 이벤트에 대한 이벤트 핸들러를 적절하게 구현하여 자신이 소유하고 있는 DB에 반영한다.
장점
-
마이크로 서비스 아키텍처에서 효율적인 쿼리
API 조합 패턴과 비교해 보았을 때 여러 서비스를 호출하여 데이터를 가져오지 않고 하나의 서비스만을 호출해서 데이터를 가져올 수 있기 때문에 더욱 효율적이다.
-
다양한 쿼리를 효율적으로 구현
별도의 서비스를 분리하고 데이터 조회에 최적화된 DB 반영 및 최적화된 모델 설계가 가능하기 때문에 효율적인 쿼리가 가능하다.
단점
- 아키텍처의 복잡성 증가
개발자가 뷰를 조회/수정하는 쿼리 서비스를 작성해야 하며, 또 별도의 DB를 관리해야하기 때문에 관리 포인트가 늘어난다.
- 복제 시차
커멘드/쿼리 양쪽 뷰 사이의 시차를 처리해야 한다. 커멘드 쪽이 이벤트를 발행하는 시점과 쿼리 쪽이 이벤트를 받아서 뷰를 업데이트하는 시점 사이에 지연이 발생할 것이다.
복제 시차를 처리하기 위해서 커멘드/ 쿼리 양 쪽 API 가 클라이언트에 버전 정보를 전달해서 stale된 데이터를 분간할 수 있게 할 수 있다. (이후 클라이언트 side에서 데이터 폴링)
또 FE에서는 커멘드 호출이 성공했을 때 업데이트 된 데이터를 재호출하는 것이 아니라, 커멘드 결과 값을 가지고 뷰를 렌더링하게 할 수도 있다.
정리
마이크로 서비스 아키텍처에서는 데이터들이 분산되어 있기 때문에 효율적인 데이터 조회 패턴을 설계하는 것이 중요하다. API 조합 패턴, CQRS 패턴 두 가지 패턴으로 문제를 해결할 수 있는데, 쿼리 데이터 모델의 데이터 구조가 복잡하지 않고, 서비스 복잡도가 높지 않다면 API 조합 패턴을 선택할 수 있다. 그러나 쿼리 데이터 모델의 구조가 복잡하고, 커멘드 데이터 모델의 최적화된 쿼리를 위해서 별도의 데이터 스토리지가 필요하다면 CQRS 패턴 도입을 고려해볼 수 있다.
내용 출처 : 마이크로 서비스 패턴 책