다중 행 함수(Multi-Row Function)
여러 행의 그룹에 대해 적용되는 함수
다중 행 함수의 종류
-
그룹 함수(Group Function)
- 집계 함수(Aggregate Function): 여러 행에 대해 연산하여 하나의 결과를 반환함
- 종류:
COUNT,SUM,AVG,MAX,MIN등
- 종류:
- 고급 집계 함수: 다차원 분석을 위해 사용되는 집계 함수
- 종류:
ROLLUP,CUBE,GROUPING SETS
- 종류:
- 집계 함수(Aggregate Function): 여러 행에 대해 연산하여 하나의 결과를 반환함
-
윈도우 함수(Window Function)
- 특정 행 집합(윈도우)에 대해 연산을 수행하며, 개별 행에 대한 결과를 반환함
집계 함수
- 여러 행의 그룹에 대한 연산을 통해 하나의 결과를 반환함
SELECT,HAVING,ORDER BY절에 사용 가능GROUP BY절을 통해 그룹핑 기준을 명시하여 사용
이미지 내용을 바탕으로 블로그에 올릴 수 있도록 정리해드리겠습니다.
집계 함수 (Aggregate Functions)
-
NULL을 제외하고 계산
- 예: 전체 학생 100명 중 10명의 성적이 NULL일 때, 전체 평균은 90명의 성적에 대한 평균으로 계산됨
- 모든 값이 NULL일 경우, 결과값은 NULL이 됨
-
(DISTINCT | ALL) 옵션
- 기본값은
ALL - DISTINCT: 같은 값을 갖는 여러 데이터들을 하나로 간주
- 기본값은
집계 함수와 사용 목적
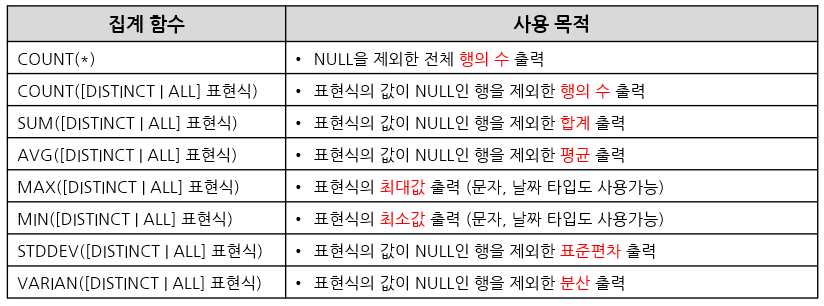
GROUP BY
GROUP BY
- 집계 함수는 일반적으로 GROUP BY 절을 사용하여 그룹별 연산을 수행합니다.
-
소그룹별 집계
GROUP BY 절을 사용해 POSITION별로 COUNT와 AVG를 구할 수 있습니다.SELECT POSITION, COUNT(*) 전체행수, COUNT(HEIGHT) 키값수, ROUND(AVG(HEIGHT), 2) 평균키 FROM PLAYER GROUP BY POSITION;- 결과: POSITION별로 전체 행 수, 키 값 수, 평균 키 출력.
-
전체 테이블을 하나의 그룹으로
테이블 전체가 하나의 그룹이면 GROUP BY 절을 생략할 수 있습니다.SELECT COUNT(*) 전체행수, COUNT(HEIGHT) 키값수, ROUND(AVG(HEIGHT), 2) 평균키 FROM PLAYER;- 결과: 전체 행 수, 키 값 수, 평균 키를 출력.
GROUP BY와 HAVING
-
집계 함수에 조건 부여
예) 포지션별 키의 평균이 180 이상인 경우만 출력SELECT POSITION, ROUND(AVG(HEIGHT), 2) 평균키 FROM PLAYER GROUP BY POSITION HAVING AVG(HEIGHT) >= 180; -
WHERE 절 사용 시 에러 발생
WHERE 절은 GROUP BY 절보다 먼저 수행되므로 집계 결과에 조건을 붙일 때는 HAVING을 사용해야 합니다.SELECT POSITION, ROUND(AVG(HEIGHT), 2) 평균키 FROM PLAYER WHERE AVG(HEIGHT) >= 180; -- 오류 발생 GROUP BY POSITION;- WHERE 절을 HAVING 절로 변경해야 정상 실행됩니다.
GROUP BY 여러 컬럼 기준
-
그룹핑 기준이 여러 개인 경우, GROUP BY에 여러 컬럼을 지정하여 복합적인 그룹핑을 할 수 있습니다.
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) AS 급여합 FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY DNAME, JOB ORDER BY DNAME, JOB;- 결과: 부서명과 직업별로 직원 수와 급여 합계를 출력합니다.
SELECT 문장 구조 및 실행 순서
-
SELECT 문장 구조
- SELECT 문의 기본 구조는 다음과 같다.
SELECT POSITION, ROUND(AVG(HEIGHT), 2) AS 평균키 FROM PLAYER WHERE HEIGHT IS NOT NULL GROUP BY POSITION HAVING AVG(HEIGHT) > 190 ORDER BY AVG(HEIGHT) DESC; - 이 구조를 통해 원하는 조건을 기준으로 데이터를 필터링하고, 그룹화하여 평균값을 계산한 뒤 특정 조건에 맞는 결과만을 정렬하여 출력한다.
- SELECT 문의 기본 구조는 다음과 같다.
-
실제 실행 순서
- SELECT 문이 작성된 순서와 실제 실행 순서는 다르며, SQL 엔진이 데이터 처리 절차에 맞게 다음과 같은 순서로 실행한다.
- FROM - 조회할 테이블을 지정
- WHERE - 조건을 통해 불필요한 데이터를 제외
- GROUP BY - 데이터를 그룹화
- HAVING - 그룹화된 데이터에 추가 조건을 적용
- SELECT - 필요한 칼럼을 선택하고 계산
- ORDER BY - 결과를 정렬
- SELECT 문이 작성된 순서와 실제 실행 순서는 다르며, SQL 엔진이 데이터 처리 절차에 맞게 다음과 같은 순서로 실행한다.
ROWNUM 활용 시 주의사항
-
ROWNUM은 SELECT 결과에서 각 행에 번호를 부여하지만, WHERE 절보다 먼저 적용되어 주의가 필요하다.
-
예를 들어, 키가 가장 작은 3명의 선수를 조회하고자 할 때는 다음과 같이 잘못된 쿼리와 수정된 쿼리를 구분하여 작성해야 한다.
-- 잘못된 쿼리 SELECT PLAYER_NAME, HEIGHT, ROWNUM FROM PLAYER WHERE ROWNUM < 4 ORDER BY HEIGHT; -- 수정된 쿼리 SELECT PLAYER_NAME, HEIGHT, ORGNO, ROWNUM FROM (SELECT PLAYER_NAME, HEIGHT, ROWNUM AS ORGNO FROM PLAYER ORDER BY HEIGHT) WHERE ROWNUM < 4;
칼럼의 유효 범위
-
WHERE, ORDER BY 절에서의 유효 범위
- WHERE와 ORDER BY 절에서는 SELECT 절에 명시되지 않은 칼럼도 사용할 수 있다.
- 예시:
SELECT PLAYER_NAME, HEIGHT FROM PLAYER WHERE POSITION = 'MF' ORDER BY TEAM_ID;
-
GROUP BY 사용 시 유효 범위
- GROUP BY를 사용하는 경우, SELECT에 명시되지 않은 집계 칼럼을 HAVING, ORDER BY에서 사용할 수 있다.
- 예시:
SELECT TEAM_ID, COUNT(*) AS 인원 FROM PLAYER GROUP BY TEAM_ID HAVING AVG(HEIGHT) > 178 ORDER BY AVG(HEIGHT);
-
인라인 뷰 사용 시 유효 범위
- 인라인 뷰를 사용하면 새로운 테이블 구조가 생성된 것으로 이해해야 하며, 인라인 뷰 SELECT 절에 명시되지 않은 칼럼은 메인 쿼리에서 사용할 수 없다.
- 예시:
-- 올바른 쿼리 SELECT PLAYER_NAME, HEIGHT FROM (SELECT PLAYER_NAME, HEIGHT, POSITION FROM PLAYER WHERE POSITION = 'MF') ORDER BY POSITION;
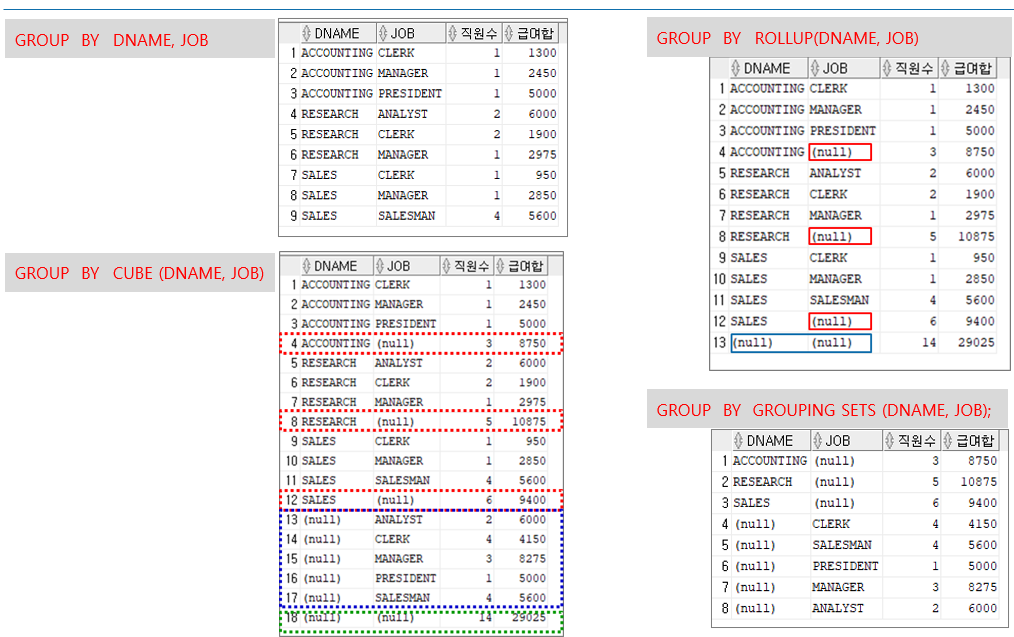
고급 집계 함수 ROLLUP, CUBE, GROUPING SETS
1. ROLLUP
ROLLUP은 계층적으로 집계하여, 한 방향으로 누적되는 집계를 제공한다. 주로 보고서의 총합과 부분합을 계산할 때 유용하다.
- 사용 예시:
GROUP BY ROLLUP (DNAME, JOB); - 집계 방식:
DNAME,JOB순서로 집계 - 결과:
DNAME별로JOB에 대한 세부 집계를 하고,DNAME별 합계를 구한다.- 최종적으로 전체 합계도 제공한다.
- 특징:
- 계층적 집계만 제공되므로, 하나의 방향(하향식)으로만 부분합을 구한다.
- 예를 들어,
ACCOUNTING부서의CLERK,MANAGER등의 역할별 집계와,ACCOUNTING부서 전체의 합계, 마지막에 전체 합계를 보여준다.
2. CUBE
CUBE는 모든 가능한 조합에 대한 집계를 제공한다. ROLLUP과 다르게 다양한 방향으로 집계가 이루어진다.
- 사용 예시:
GROUP BY CUBE (DNAME, JOB); - 집계 방식: 모든 조합의 집계를 포함하여 계산
- 결과:
DNAME과JOB의 모든 조합에 대해 부분합을 계산한다.DNAME별 합계,JOB별 합계, 그리고 전체 합계를 모두 포함한다.
- 특징:
- 모든 조합을 포함하므로,
DNAME별 합계,JOB별 합계, 둘 다 합계에 포함된다. - 예를 들어,
ACCOUNTING부서의 모든 역할별 집계, 각 역할별 총합, 그리고 전체 합계를 포함한다.
- 모든 조합을 포함하므로,
3. GROUPING SETS
GROUPING SETS는 특정 그룹 조합을 지정하여 원하는 부분 집계만 수행할 수 있는 유연성을 제공한다.
- 사용 예시:
GROUP BY GROUPING SETS ((DNAME, JOB), (DNAME), (JOB)); - 집계 방식: 지정된 그룹만 집계
- 결과:
DNAME과JOB의 조합에 대해서만 집계를 수행하며, 필요한 집합만을 대상으로 집계를 수행한다.
- 특징:
- 유연한 조합 집계를 제공하며, 필요하지 않은 집계는 생략할 수 있다.
- 예를 들어,
DNAME과JOB의 조합 및DNAME별 집계,JOB별 집계를 지정할 수 있다.
비교 요약
| 기능 | ROLLUP | CUBE | GROUPING SETS |
|---|---|---|---|
| 집계 방식 | 단방향, 누적 집계 | 모든 조합의 집계 | 특정 조합을 선택적으로 집계 |
| 활용도 | 계층적 보고서, 총합/부분합 계산 | 다양한 조합 집계 | 유연한 집계가 필요한 경우 |
| 예시 결과 | 부서-역할별 합계와 전체 합계 | 모든 부서/역할 조합의 합계 | 원하는 부서/역할 조합의 합계만 계산 |
이와 같이, ROLLUP은 계층적, CUBE는 모든 조합, GROUPING SETS는 선택적 조합에 유용하다.
윈도우 함수(Window Function)
- 윈도우 함수는 SQL에서 행 간의 관계를 정의하여, 여러 행에 걸쳐 연산을 수행할 수 있는 기능이다.
- 기존 관계형 DB에서는 칼럼 간 연산은 쉽지만, 행 간의 연산은 어렵기 때문에 윈도우 함수가 필요하다.
- 예를 들어, 각 직원이 속한 부서 내에서의 급여 순위를 구할 때 윈도우 함수를 사용할 수 있다.
윈도우 함수의 특징
- 중첩(Nested) 사용이 불가하다.
- 서브쿼리에서도 사용 가능하다.
윈도우 함수의 종류
- 순위 함수:
RANK,DENSE_RANK,ROW_NUMBER - 집계 함수:
SUM,MAX,MIN,AVG,COUNT - 행 순서 함수:
FIRST_VALUE,LAST_VALUE,LAG,LEAD - 비율 함수:
RATIO_TO_REPORT,PERCENT_RANK,NTILE - 통계 함수:
CORR,STDEV,VARIANCE등
윈도우 함수 구문
SELECT WINDOW_FUNCTION(ARGUMENTS) OVER(
[PARTITION BY 칼럼]
[ORDER BY 절]
[WINDOWING 절]
)
FROM 테이블 명;- WINDOW_FUNCTION: 기본 함수나 윈도우 함수로 추가된 함수
- ARGUMENTS(인수): 함수에 따라 0~N개의 인수를 지정
- PARTITION BY 절: 집합을 소그룹으로 나누는 기준 설정
- ORDER BY 절: 순서를 지정할 기준
- WINDOWING 절: 함수의 대상이 되는 행 기준 범위를 지정
- ROWS: 행의 수를 기준으로 범위 설정
- RANGE: 값을 기준으로 범위 설정
WINDOWING 절의 사용 예
| 표현식 | 해석 |
|---|---|
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING | 현재 행의 앞 한 행, 현재 행, 뒤 한 행을 범위로 지정 |
RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING | 현재 행의 값 - 50에서 (현재 행의 값 + 150)을 범위로 지정 |
RANGE UNBOUNDED PRECEDING | 현재 파티션의 첫 행부터 현재 행까지 지정 |
순위 윈도우 함수
순위 윈도우 함수
-
RANK 함수
- 동일한 값에는 동일한 순위를 부여
- 동일한 순위를 여러 건으로 취급
- 예를 들어, 1등이 2명인 경우 1등, 1등, 3등으로 순위가 매겨짐
-
DENSE_RANK 함수
- 동일한 값에는 동일한 순위를 부여
- 동일 순위를 한 건으로 취급
- 예를 들어, 1등이 2명인 경우 1등, 1등, 2등으로 순위가 매겨짐
-
ROW_NUMBER 함수
- 동일 값에 다른 순위 부여
- 예를 들어, 1등, 2등, 3등으로 연속적인 순위를 부여함
- 동일 값에 다른 순위 부여
예제
SELECT
JOB,
ENAME,
SAL,
RANK() OVER (ORDER BY SAL DESC) AS RANK,
DENSE_RANK() OVER (ORDER BY SAL DESC) AS DENSE_RANK,
ROW_NUMBER() OVER (ORDER BY SAL DESC) AS ROW_NUMBER
FROM EMP;예제 결과 설명
RANK: 동일한 급여 값이 있는 경우 같은 순위가 부여되고, 그 다음 순위는 건너뛰게 됩니다.DENSE_RANK: 동일한 급여 값에 같은 순위가 부여되지만, 다음 순위는 연속적으로 이어집니다.ROW_NUMBER: 동일한 급여 값이어도 각 행에 대해 고유한 순위를 부여합니다.
집계 윈도우 함수
집계 윈도우 함수 설명
윈도우 함수는 데이터베이스에서 여러 행에 걸쳐 계산을 수행할 때 사용되며, 특정 집계 값을 계산하면서도 원본 데이터의 각 행을 그대로 출력할 수 있는 강력한 기능입니다.
1. MAX / MIN
- 예시: 각 직업 내에서 급여의 최대값을 함께 출력.
- 쿼리 설명:
MAX(SAL) OVER (PARTITION BY JOB) AS JOB_MAX구문을 사용하여 직업(JOB)별로 최대 급여를 계산하고, 이를 각 행에 표시. - 결과: 직업별 최대 급여가 모든 직원의 행에 함께 출력되어, 각 직업의 최고 연봉을 쉽게 비교할 수 있음.
2. SUM / AVG
- 예시: 각 직업 내에서 본인보다 높은 급여를 받는 직원들의 급여 합계(본인 포함)를 계산.
- 쿼리 설명:
SUM(SAL) OVER (PARTITION BY JOB ORDER BY SAL DESC RANGE UNBOUNDED PRECEDING)구문을 통해 급여 내림차순으로 정렬된 상태에서, 본인 급여를 포함하여 높은 급여를 받는 직원들의 합계를 계산. - 결과: 같은 급여를 받는 직원들은 동시에 합계에 반영되어 출력됨.
3. SUM / AVG (변형)
- 예시: 본인의 위, 아래 직원의 급여를 포함한 합계 출력.
- 쿼리 설명:
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING를 사용해 본인의 위아래 한 행을 포함한 범위에서 합계를 계산. - 결과: 본인과 위아래 행의 급여를 합산하여 중간 값으로 나타내며, 특정 범위 내 급여의 합계를 쉽게 파악할 수 있음.
4. COUNT
- 예시: 본인보다 급여가 100 낮은 직원부터 200 높은 직원까지의 총 직원 수 계산.
- 쿼리 설명:
COUNT(*) OVER (ORDER BY SAL RANGE BETWEEN 100 PRECEDING AND 200 FOLLOWING)구문을 통해 본인 급여를 기준으로, 범위 내의 직원 수를 계산. - 결과: 본인 급여를 기준으로 주변 급여에 위치한 직원 수를 계산하며, 특정 범위 내 직원 수를 쉽게 파악 가능.
행 순서 윈도우 함수
FIRST_VALUE (or LAST_VALUE) 함수
- 기능: 각 파티션에서 가장 먼저(또는 나중)에 나온 값을 반환합니다.
예제 설명
SELECT DEPTNO, ENAME, SAL,
FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC, ENAME ASC) AS RICH_EMP
FROM EMP;- 이 쿼리는 각 부서(DEPTNO)별로 가장 높은 급여를 받는 직원의 이름을
RICH_EMP컬럼에 출력합니다. PARTITION BY DEPTNO는 부서별로 파티션을 나누는 역할을 하며,ORDER BY SAL DESC로 급여 순서에 따라 정렬됩니다.
LAG (or LEAD) 함수
- 기능: 각 파티션에서 현재 행의 기준으로 이전(또는 이후) 행의 값을 가져옵니다.
예제 설명 1
SELECT ENAME, SAL,
LAG(SAL, 1) OVER (ORDER BY SAL DESC) AS HIGHER_SAL,
LEAD(SAL, 1) OVER (ORDER BY SAL DESC) AS LOWER_SAL
FROM EMP
WHERE JOB = 'SALESMAN';LAG(SAL, 1)은 바로 이전 사람의 급여를 가져오고,LEAD(SAL, 1)은 바로 다음 사람의 급여를 가져옵니다.JOB이 'SALESMAN'인 직원들에 대해 급여 순서에 따라 본인의 윗 사람과 아랫 사람의 급여를 함께 출력합니다.
예제 설명 2
SELECT ENAME, SAL,
LAG(SAL, 2, 0) OVER (ORDER BY SAL DESC) AS HIGHER_SAL
FROM EMP;LAG(SAL, 2, 0)은 두 번째 이전 사람의 급여를 가져오며, 값이 없을 경우0으로 채웁니다.
비율 윈도우 함수
FIRST_VALUE (or LAST_VALUE) 함수
- 기능: 각 파티션에서 가장 먼저(또는 나중)에 나온 값을 반환합니다.
예제 설명:
SELECT DEPTNO, ENAME, SAL,
FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC, ENAME ASC) AS RICH_EMP
FROM EMP;이 쿼리는 각 부서(DEPTNO)별로 가장 높은 급여를 받는 직원의 이름을 RICH_EMP 컬럼에 출력합니다.
PARTITION BY DEPTNO는 부서별로 파티션을 나누며, ORDER BY SAL DESC는 급여 순서대로 정렬합니다.
LAG (or LEAD) 함수
- 기능: 각 파티션에서 현재 행을 기준으로 이전(또는 이후) 행의 값을 가져옵니다.
예제 설명 1:
SELECT ENAME, SAL,
LAG(SAL, 1) OVER (ORDER BY SAL DESC) AS HIGHER_SAL,
LEAD(SAL, 1) OVER (ORDER BY SAL DESC) AS LOWER_SAL
FROM EMP
WHERE JOB = 'SALESMAN';LAG(SAL, 1)은 바로 이전 사람의 급여를 가져오고, LEAD(SAL, 1)은 바로 다음 사람의 급여를 가져옵니다.
JOB이 'SALESMAN'인 직원들에 대해 급여 순서에 따라 본인의 윗 사람과 아랫 사람의 급여를 함께 출력합니다.
예제 설명 2:
SELECT ENAME, SAL,
LAG(SAL, 2, 0) OVER (ORDER BY SAL DESC) AS HIGHER_SAL
FROM EMP;LAG(SAL, 2, 0)은 두 번째 이전 사람의 급여를 가져오며, 값이 없을 경우 0으로 채웁니다.
