왜 분산해야할까?
서비스의 크기가 커지고 사용자데이터를 기반으로한 서비스를 제공하면서 DB에
저장하는 데이터의 규모 또한 증가했다. 때문에 기존에 사용하는 DB의 저장공간 한계와 이에 따른 성능 저하가 발생했다. 이러한 데이터를 효과적으로 관리하기 위해서는 다양한 DB 관리기법이 존재하는데 그 중 하나가 분산하여 관리하는 방식이다.
가용성, 안정성 확보
데이터베이스에서 가용성을 확보한다는 것은 더 많은 I/O 작업을 수행할 수 있다는 것을 의미한다
데이터베이스 I/O 작업량에 따라서 처리할 수 있는 요청은 한계가 있다.
메모리가 가득 찰수도 있고, 커넥션 풀이 부족할 수도 있고, 물리적인 디스크 용량이 가득찰 수 있다. 때문에 트래픽을 여러 서버에 분산하여 가용성을 확보할 수 있다.
그리고 서버 안정성을 확보할 수 있다. DB서버가 예상치 못한 오류로인해 종료되었을때 분산시켜놓은 데이터를 통해 복구할 수 있다.
필요성
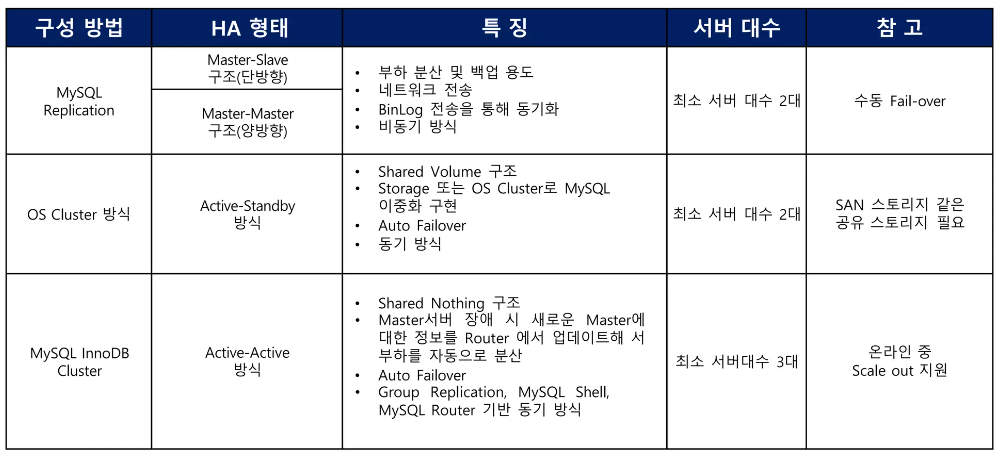
종류
-
DB Replication- 복제 -
DB sharding- 분할 -
DB Clustering- 확장
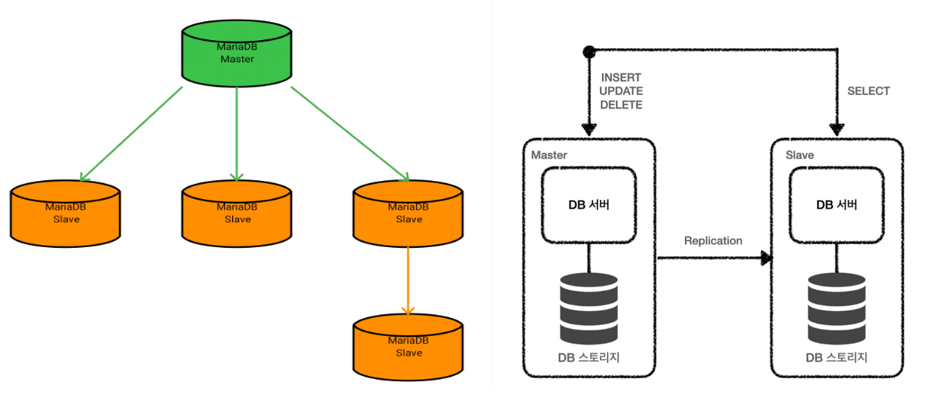
Replication (Master / Slave)
장점
- read, write 작업을 Slave와 Master로 분리하여 부하를 분산시킬 수 있다.
- 특정 노드가 죽더라도 다른 노드의 작업을 계속할 수 있다. (Master가 죽어도 read가능)
단점
- 장애가 발생했을때 자동으로 Fail over가 불가하다.
- Master와 slave의 데이터를 동기화하는 시간 차가 발생한다. (실시간 서비스 ㄴ)
- Master에 장애발생시 binlog가 slave로 복제되지 않을 수 있다.
동작과정
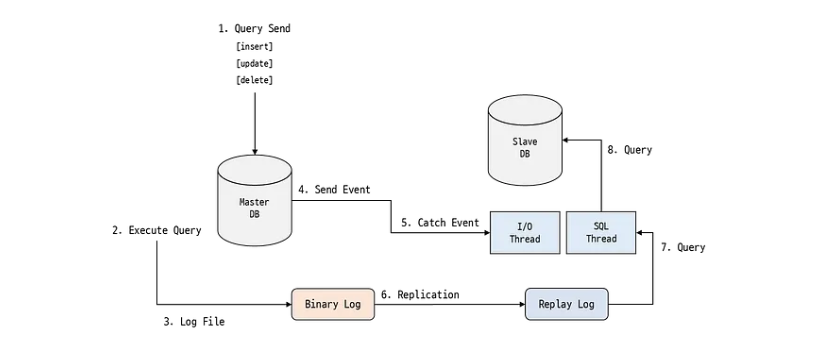
(1) Client가 쓰기 쿼리 작업을 요청합니다. 쓰기 쿼리요청은 Master DB가 받습니다.
(2) Master는 변경사항을 Binary log 파일에 기록합니다. 이후 DB에 반영(commit)합니다.
(3) Slave는 현재까지 기록한 이벤트 정보를 가지고 다음 이벤트 정보를 Master에게 요청합니다.
(4) Master는 Binary log 파일에서 최신 이벤트 정보를 읽어 Slave에게 전송합니다.
(5) Slave는 Master에게 받은 이벤트 정보를 Relay log 파일에 기록합니다.
(6) Slave는 최종 변경사항을 DB에 반영(commit)합니다.
(4) 과정에서는 Master 쓰레드, (3)(5) 과정에서는 Slave I/O 쓰레드, (6) 과정에서는 Slave SQL 쓰레드가 동작합니다.
sharding

서버를 물리적으로 여러 대를 사용하여 수평적인 방식으로 파티셔닝을 하는 방법
샤드키
파티셔닝에서도 각 파티션이 어떤 데이터를 가져갈지 결정할 파티션 키가 있었던 것처럼, 분할된 노드(분리된 데이터베이스 서버)는 각각이 가져갈 데이터를 결정해야 한다. 이 기준을 샤드 키라고 부른다.
장점
- 대용량의 테이블의 탐색속도를 빠르게 향상시킬 수 있다.
- 전체 서비스 중단 방지
- 효율적인 크기 조정
단점
- 데이터를 찾는 과정이 기존보다 복잡하다. (JOIN)
RDB에서의 문제
물리적으로 다른 노드의 데이터베이스와 JOIN 연산을 수행할 수 없는 문제
Auto Increment가 샤드별로 달라지는 문제
하나의 트랜잭션이 두 개 이상의 샤드에 접근할 수 없는 문제
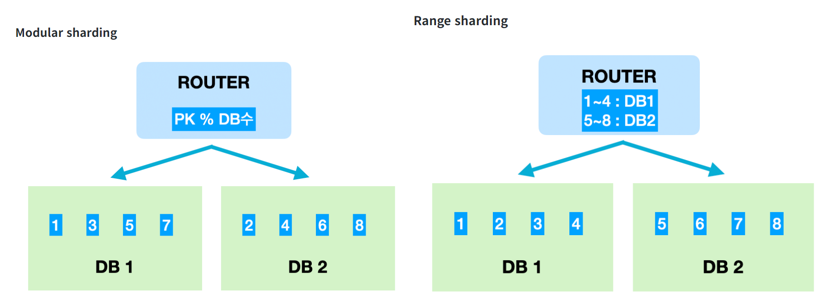
모듈러샤딩
PK를 모듈러 연산한 결과로 DB를 특정하는 방식입니다.
- 장점 : 레인지샤딩에 비해 데이터가 균일하게 분산됩니다.
- 단점 : DB를 추가 증설하는 과정에서 이미 적재된 데이터의 재정렬이 필요합니다.
레인지샤딩
PK의 범위를 기준으로 DB를 특정하는 방식입니다.
- 장점 : 모듈러샤딩에 비해 기본적으로 증설에 재정렬 비용이 들지 않습니다.
- 단점 : 일부 DB에 데이터가 몰릴 수 있습니다.
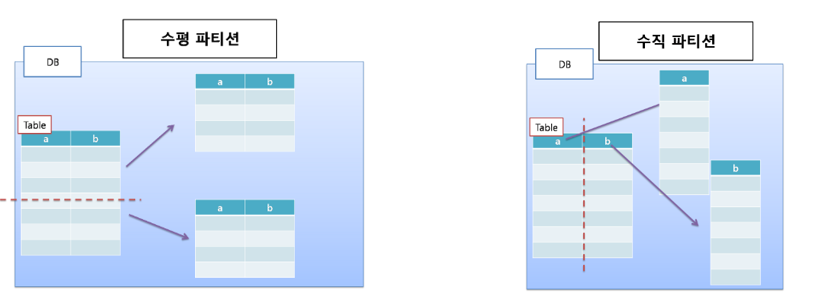
수평분할, sharding 차이점
수평분할은 스키마가 같은 데이터를 두개 이상의 테이블에 나누어 저장하는 것
즉, 같은 DB안에 같은 스키마의 테이블을 종류에 따라 나누는 것이다 예를 들면 남자테이블, 여자테이블, 혹은 노트북테이블모델, 데스크탑테이블모델 등으로 나누는 것이다.
샤딩은 물리적으로 아에 다른 데이터 베이스에 데이터를 분산하는 방식이다. 즉, 둘의 차이점은 같은 DB에 저장되느냐 아니냐의 차이라고 할 수 있다.
Clustering
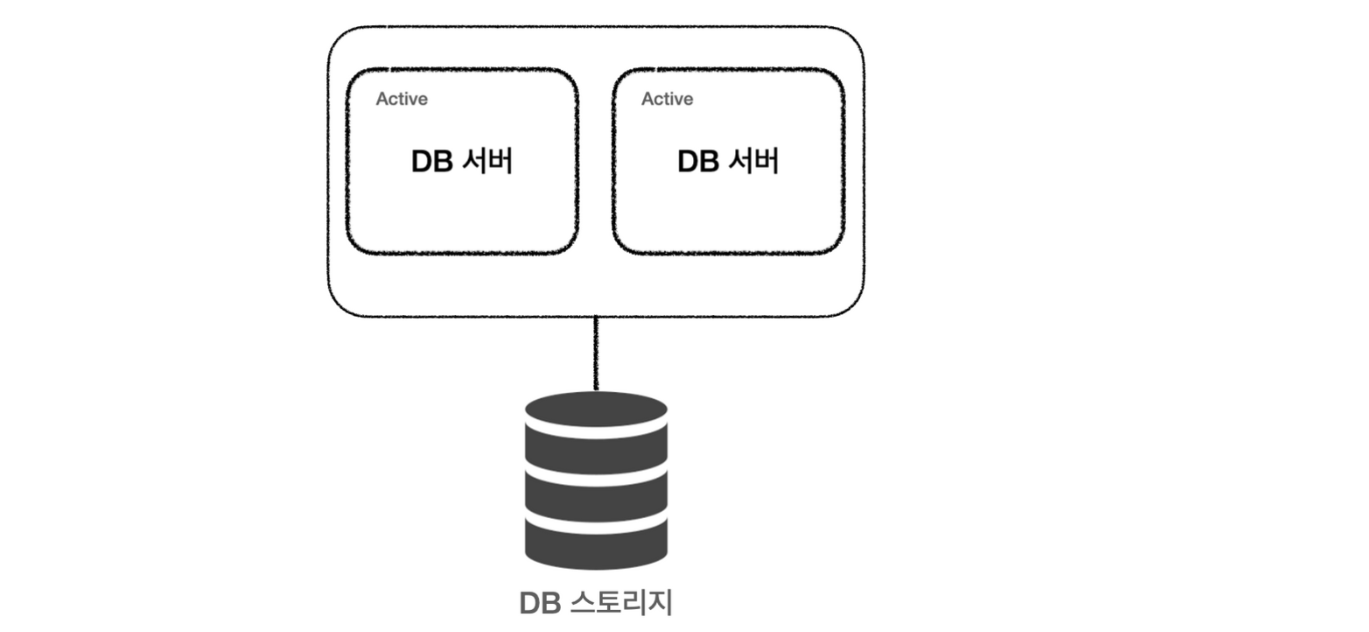
- 장점 : 데이터베이스 서버에 가해지던 부하가 여러 개로 나눠져 CPU와 Memory의 부하가 줄어든다.
- 단점
여러 개의 서버가 하나의 스토리지를 공유함으로써 병목현상이 발생할 수 있다.
스토리지에서 문제가 발생한다면..?
만약 Master가 죽는다면?
https://techblog.woowahan.com/2687/
https://jhdatabase.tistory.com/entry/Mysql-Haproxy-%EA%B5%AC%EC%84%B1
https://www.happykoo.net/@happykoo/posts/54
