최근 여러 프로젝트를 찾아보며 구경하다보니 redis의 존재에 대해 알게됐습니다. 검색을 해보니 캐시와 비슷한 것??? 이라고하는데 솔직히 잘 모르겠어서 이 redis를 캐시대신 사용하는 이유가 무엇일지, 또 어떠한 장점이 있는지 공부하며 해당 내용을 정리해보려합니다.
https://www.youtube.com/watch?v=mPB2CZiAkKM
참고 강의
1. Redis란 무엇인가..?
Redis의 풀네임에서 알 수 있듯이 dictionary 구조 한마디로 key-value형태로 데이터를 저장하고 관리하는 서버를 말합니다.
https://redis.io/ 공식 홈페이지에서는 Redis의 핵심기능을 다음과 같이 말하고 있습니다.
Redis는 데이터베이스,캐시, 메시지 브로커 및 스트리밍 엔진으로 사용되는 오픈 소스(BSD 라이선스), 인메모리 데이터 구조 저장소 입니다.
Redis는 문자열 , 해시 , 목록 , 집합 , 범위 쿼리가 있는 정렬된 집합 , 비트맵 , 하이퍼로그 로그 , 지리 공간 인덱스 및 스트림 과 같은 컬렉션을 제공합니다 .
Redis에는 복제 , Lua 스크립팅 , LRU 축출 , 트랜잭션 및 다양한 수준의 디스크 지속성 이 내장되어 있으며 다음을 통해 고가용성을 제공합니다.
Redis Sentinel 및 Redis 클러스터를 통한 자동 파티셔닝을 제공합니다.
캐시(Cache)
Cache는 DP알고리즘과 비슷하게 나중에 요청올 결과를 미리 저장해두었다가 빠르게 서비스 해주는 것을 의미합니다. 즉, 미리 결과를 저장하고 나중에 요청이 오면 해당 요청에 대해서 DB 또는 API를 참조하지 않고 Cache에 접근하여 요청을 처리하게 됩니다. 이러한 cache가 동작 할 수 있는 철학에는 80퍼센트의 결과는 20퍼센트의 원인으로 인해 발생한다는 파레토 법칙에 있습니다.
즉, 이것은 Cache가 효율적일 수 있는 이유가 될 수 있습니다. 모든 결과를 캐싱할 필요는 없으며, 우리는 서비스를 할 때 많이 사용되는 20%를 캐싱한다면 전체적으로 영향을 주어 효율을 극대화 할 수 있다는 말입니다.
Cache 사용 구조
-look aside cache
look aside cache은 cache에 접근하여 데이터가 존재하는지 판단하고 cache에 존재하지 않는다면 db,api를 호출합니다. 대부분 cache를 사용한 개발이 이 프로세스를 따르고있습니다.
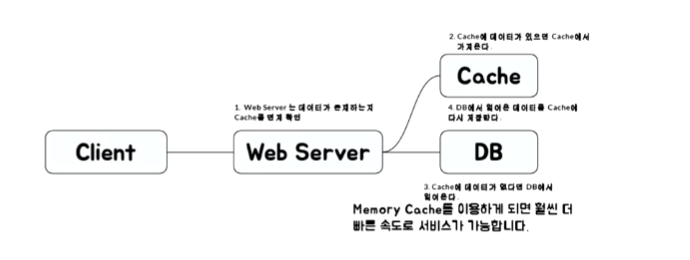
- web서버는 데이터가 존재하는지 cache를 먼저 확인
- cache에 데이터가 존재하면 cache에서 데이터를 가져옴
- 만일 cache에 데이터가 없다면 db에서 읽어온다.
- db에서 읽어온 데이터를 cache에 다시 저장한다.
-write back
만약 디스크 기반 db존재하고 데이터를 쓰는 동작이 일어난다면 동작을 요청할 때마다 db에 접근하게됩니다. 이렇게 요청이 올때마다 db에 접근하게 되된다면 애플리케이션의 속도 저하가 나타날 수 있습니다.
write back은 데이터를 cache에 먼저 저장했다가 특정 시점마다 db에 전송하는 것입니다. 이렇게 된다면 매 요청마다 db에 접근할 필요없이 특정 시점이 왔을때만 db에 접근해 속도 저하를 방지할 수 있습니다.
하지만 처음에 cache(메모리)에 먼저 저장하기 때문에 데이터가 날아갈 위험이 있습니다.
인메모리 란?
- 장점
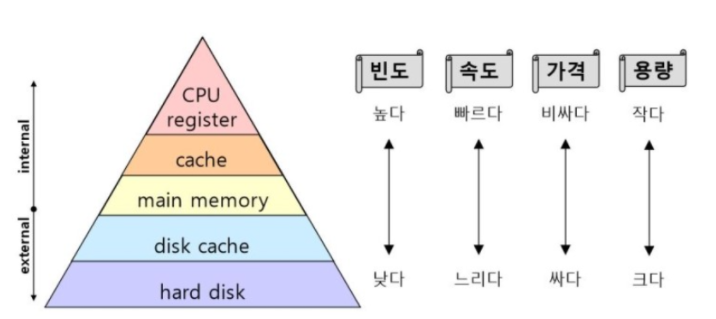
인메모리란 컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용하는 방법을 말합니다. RAM에 데이터를 저장하게 된다면 메모리 내부에서 처리가 되므로 데이터를 저장하고 조회할때 하드디스크를 오고 가는 과정을 거치지 않아도 됩니다. 때문에 SSD,HDD 같은 저장공간에서 데이터를 가져오는 것보다 RAM에서 데이터를 가져오는 속도가 많게는 수백배 이상 빠릅니다. 때문에 Redis는 속도가 빠르다는 장점을 가지고 있습니다.
- 단점
Redis의 인메모리 저장방식은 빠른 속도를 자랑하는 대신 치명적인 단점이 존재합니다. 바로 용량으로 인해 데이터 유실이 발생할수 있다는 점입니다.
참고로 2019년에 쿠팡에서 레디스DB를 불러오는 과정에서 버그가 발생한적이 있습니다.
Redis는 인메모리방식이므로 서버의 메모리 용량을 초과하는 데이터를 redis에서 처리할 경우, 서버 자체에도 문제가 생기며, ram의 특성인 휘발성(전원이 꺼지면 가지고 있던 데이터가 사라진다.)에 따라 ram에 저장되었던 레디스의 데이터들은 유실될 수 있습니다. 때문에 메인 데이터베이스로 사용하기에는 무리가 있습니다.
레디스에서도 데이터를 영속적으로 저장하는 방법을 제공하고 있습니다. 하지만 빠르고 간편하게 사용하는 것을 목표로 하는 레디스의 인메모리 방식에는 적합하지 않은 방식이 될 수 있습니다.
2. Redis 특징
위의 내용은 cache랑 별반 다를게 없어 보입니다. 하지만 redis는 cache와 달리 다음과 같은 특징을 가지고있습니다.
- List, Set, Sorted Set, Hash 등과 같은 Collection을 지원합니다.
- Race condition에 빠질 수 있는 것을 방지합니다.
- Redis는 Single Thread
- 따라서 Atomic 보장 (가끔 발생하기는 한다고합니다...)
Race condition예시

- persistence를 지원하여 서버가 꺼지더라도 다시 데이터를 불러들일 수 있습니다.
redis의 트랜잭션
redis는 트랜잭션을 지원합니다. redis의 트랜잭션을 사용할 경우 명령들을 queue에 모아두고 한번에 처리합니다.
하지만 redis의 트랜잭션은 RDB의 트랜젝션과 다른 점이 존재합니다. 일반적인 트랜잭션은 작업이 완전히 실행되거나 rollback되는 원자성을 가지고 있습니다. 하지만 redis의 트랜잭션은 rollback을 지원하지 않습니다. 중간에 실패하더라도 실패한 명령을 제외하고 나머지 명령들은 모두 실행됩니다.
해당내용을 보고 redis는 원자성을 보장한다고 했는데 redis의 트랜잭션은 원자성 보장하지 않는다니... 무슨말이지? 라는 의문이 들었습니다.
redis는 대부분의 동작이 싱글스레드로 동작합니다. 때문에 여러 요청이 동시에 돌아가지는 않지만 빠르게 처리해 동시성을 보장하려고 노력하고 경쟁상태를 방지합니다.
때문에 제가 생각하는 redis와, rdb의 원자성의 의미는 이렇습니다.
rdb의 원자성 --> 오류발생시 트랜잭션이 롤백
redis의 원자성 --> 하나의 스레드로 동작하며 중간에 다른 요청이 들어오지 않음
- 장점 : 롤백이 없기 때문에 속도가 빠르다.
- 단점 : 오류가 그냥 발생해서 문제....
3. Redis의 사용처
인메모리의 장단점을 고려했을 때 Redis 가장 적합한 역할은 캐시 데이터베이스 서버로 사용하는 것입니다. 인메모리의 단점에서 말했듯 레디스를 활용할 때 중요한 것은, 휘발성이 강한 레디스의 특성을 고려하여 유실되어도 비교적 무방한 데이터들을 저장하여 사용하도록 합니다.
- 여러 서버에서 같은 데이터를 공유하고 싶을때 사용합니다.
- 한대에서만 필요하면 전역변수 쓰면 되지 않나..?❌❌❌
- Redis 자체가 Atomic하기때문에 Thread safe 하고 Single Thread 이기 때문에 Race Condition 발생 가능성이 낮습니다.
- 주로 많이 쓰는 곳
- 인증 토큰등을 저장 (Strings or hash)
- Ranking 보드로 사용 ( Sorted Set )
- 유저 API Limit
- Job QUeue
