문제 설명
개발팀 내에서 이벤트 개발을 담당하고 있는 "무지"는 최근 진행된 카카오이모티콘 이벤트에 비정상적인 방법으로 당첨을 시도한 응모자들을 발견하였습니다. 이런 응모자들을 따로 모아 불량 사용자라는 이름으로 목록을 만들어서 당첨 처리 시 제외하도록 이벤트 당첨자 담당자인 "프로도" 에게 전달하려고 합니다. 이 때 개인정보 보호을 위해 사용자 아이디 중 일부 문자를 '' 문자로 가려서 전달했습니다. 가리고자 하는 문자 하나에 '' 문자 하나를 사용하였고 아이디 당 최소 하나 이상의 '*' 문자를 사용하였습니다.
"무지"와 "프로도"는 불량 사용자 목록에 매핑된 응모자 아이디를 제재 아이디 라고 부르기로 하였습니다.
예를 들어, 이벤트에 응모한 전체 사용자 아이디 목록이 다음과 같다면
응모자 아이디
frodo
fradi
crodo
abc123
frodoc
다음과 같이 불량 사용자 아이디 목록이 전달된 경우,
불량 사용자
frd
abc1**
불량 사용자에 매핑되어 당첨에서 제외되어야 야 할 제재 아이디 목록은 다음과 같이 두 가지 경우가 있을 수 있습니다.
제재 아이디
frodo
abc123
제재 아이디
fradi
abc123
이벤트 응모자 아이디 목록이 담긴 배열 user_id와 불량 사용자 아이디 목록이 담긴 배열 banned_id가 매개변수로 주어질 때, 당첨에서 제외되어야 할 제재 아이디 목록은 몇가지 경우의 수가 가능한 지 return 하도록 solution 함수를 완성해주세요.
[제한사항]
user_id 배열의 크기는 1 이상 8 이하입니다.
user_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
응모한 사용자 아이디들은 서로 중복되지 않습니다.
응모한 사용자 아이디는 알파벳 소문자와 숫자로만으로 구성되어 있습니다.
banned_id 배열의 크기는 1 이상 user_id 배열의 크기 이하입니다.
banned_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
불량 사용자 아이디는 알파벳 소문자와 숫자, 가리기 위한 문자 '' 로만 이루어져 있습니다.
불량 사용자 아이디는 '' 문자를 하나 이상 포함하고 있습니다.
불량 사용자 아이디 하나는 응모자 아이디 중 하나에 해당하고 같은 응모자 아이디가 중복해서 제재 아이디 목록에 들어가는 경우는 없습니다.
제재 아이디 목록들을 구했을 때 아이디들이 나열된 순서와 관계없이 아이디 목록의 내용이 동일하다면 같은 것으로 처리하여 하나로 세면 됩니다.
[입출력 예]
| user_id | banned_id | result |
|---|---|---|
| ["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["frd", "abc1**"] | 2 |
| ["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["rodo", "rodo", "**"] | 2 |
| ["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["frd", "*rodo", "**", "**"] | 3 |
풀이
불량 사용자의 경우의 수 구하는 문제입니다.
문제를 보며 경우의 수를 구하라 했으니 dfs를 이용하여 경우의 수를 구하는 것은 맞는거 같은데 문자열을 어떻게 처리해야하는지 고민이 많았습니다.
더 나은 방법이 많을 것 같지만 저는 문자열을 이렇게 처리했습니다.
문자열 처리
1. 문자를 리스트로 변경
먼저 해당 문제의 입력값은
user_id=["12345", "12453", "aaaaa"]
banned_id=["*****", "*****" ]
이렇게 주어집니다. 저는 문자를 *인 문자를 현재 비교하는 값의 위치의 문자와 변경하며 비교할 것이기 때문에 파이썬에서 문자를 리스트로 변경해 주었습니다.
for u in range(len(user_id)):
user_id[u]=list(user_id[u])
for b in range(len(banned_id)):
banned_id[b]=list(banned_id[b])2. 문자에서 *부분의 인덱스 추출
저는 효율성을 위해 문자에서*로 나타나는 위치를 따로 리스트에 담았습니다. 추후에 탐색을 진행할때 해당 부분만 탐색을 하기위해 이렇게 해줬습니다.
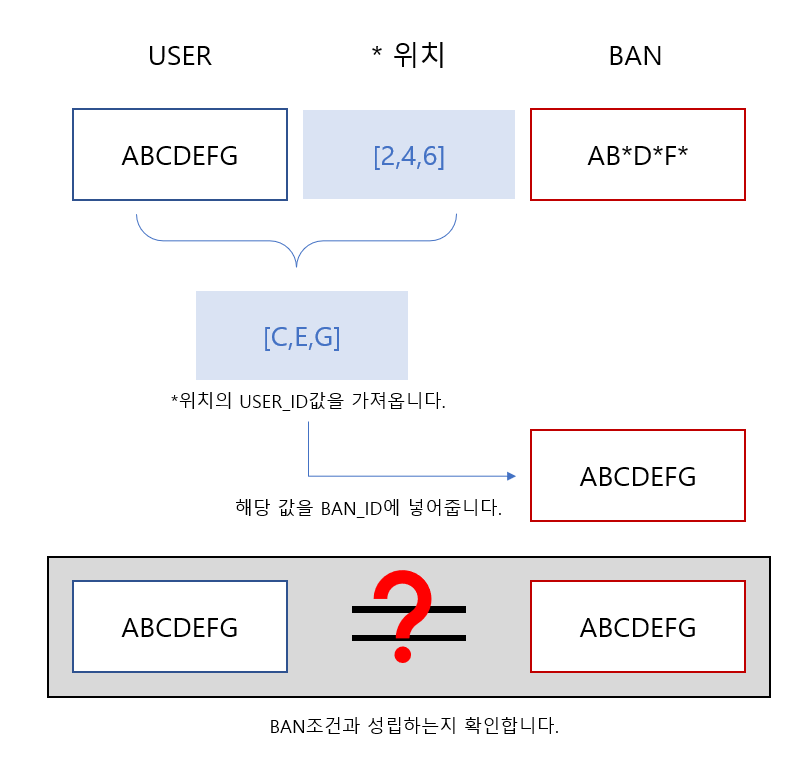
3. BAN조건에 성립하는지 확인
4. DFS
def dfs(case,count):
if count==len(banned_id): # 5
cases.append(case)
return
for u in range(len(user_id)):
if len(user_id[u])==len(banned_id[count]): # 1
change_ban_id=banned_id[count][:]
for loc in star_idx[count]: # 2
change_ban_id[loc]=user_id[u][loc]
if visited[u]==0 and user_id[u]==change_ban_id: # 3
visited[u]=1
dfs(case+["".join(user_id[u])],count+1) # 4
visited[u]=0-
각 user_id가 banned_id의 개수와 같은지 비교합니다.
- 비교하는 이유: BAN조건에 성립하는지 확인할때
*위치가 현재 리스트의 범위에 넘어가게 된다면 에러가 생기니까
- 비교하는 이유: BAN조건에 성립하는지 확인할때
-
BAN조건에 성립하는지 확인
-
조건이 성립한다면 현재아이디가 경우의수에 포함됬다는 의미이므로 다시 탐색하지 않도록 방문처리를 해줍니다.
-
BAN조건에 맞는 아이디를 찾았다면 ID를 CASE에 넣고 다음 BAN_ID를 검사해야하니 COUNT를 증가시키고 다음 BAN_ID를 검사합니다.
-
만약 모든 BAN_ID의 조건에 만족한 아이디를 찾았다면 현재까지 찾은 ID를 CASES 리스트에 넣어줍니다.
5. 중복제거
answer=set()
for case in cases:
answer.add(tuple(set(sorted(case))))전체 코드
def solution(user_id, banned_id):
visited=[0]*len(user_id)
answer=[]
star_idx=[ [] for _ in range(len(banned_id)) ]
for u in range(len(user_id)):
user_id[u]=list(user_id[u])
for b in range(len(banned_id)):
banned_id[b]=list(banned_id[b])
for i in range(len(banned_id[b])):
if banned_id[b][i]=="*":
star_idx[b].append(i)
def dfs(case,count):
if count==len(banned_id):
cases.append(case)
case=[]
return
for u in range(len(user_id)):
if len(user_id[u])==len(banned_id[count]):
change_ban_id=banned_id[count][:]
for loc in star_idx[count]:
change_ban_id[loc]=user_id[u][loc]
if visited[u]==0 and user_id[u]==change_ban_id:
visited[u]=1
dfs(case+["".join(user_id[u])],count+1)
visited[u]=0
cases=[]
dfs([],0)
answer=set()
for case in cases:
answer.add(tuple(set(sorted(case))))
return len(answer)