프로젝트를 시작하면서
우리가 필요한 공공 데이터를 DB에 넣어주는 작업을 해야 했다.
이를 위해서 두 가지 단계가 필요했다.
1)CSV 형태인 데이터들을 DB에 넣는다.
2)그전에 데이터를 우리가 원하는 형태로 가공한다.
DB에 데이터 넣기
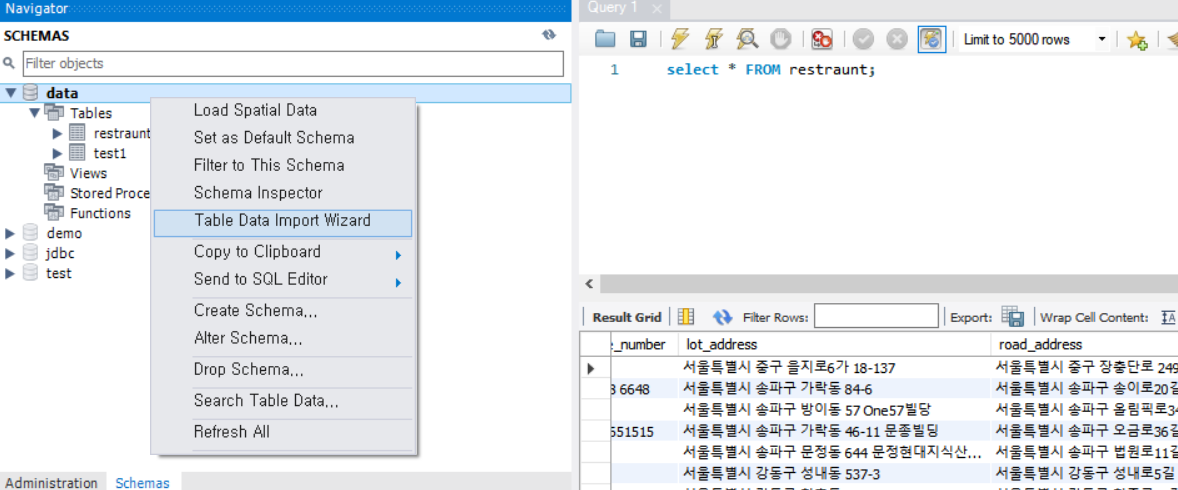
Table Data Import Wizard를 통해서 csv 파일을 넣어줄 수 있다.
이때, 칼럼명이 한글로 돼 있으면 안된다고 해서 영어로 바꿔줬다.
DB에 데이터 넣을 때 1)파이썬 2)스프링 배치를 고민했다.
근데, 파이썬을 애초에 할 줄 모르고 스프링 배치는 너무 어려웠다.
간단하게 워크벤치로 넣을 수 있다고 해서 그 방식을 이용했는데 상당히 편하고 빠르다.
- 참고로 import하면서 데이터를 바로 넣어주니까 index 키를 만들 수가 없었다.
그래서,
CREATE TABLE places (
id INT AUTO_INCREMENT PRIMARY KEY,
management_number TEXT,
phone_number TEXT,
lot_address TEXT,
road_address TEXT,
name TEXT,
category TEXT,
X TEXT,
Y TEXT
);미리 테이블을 만들어놓고 칼럼을 맵핑하는 방식을 썼다.
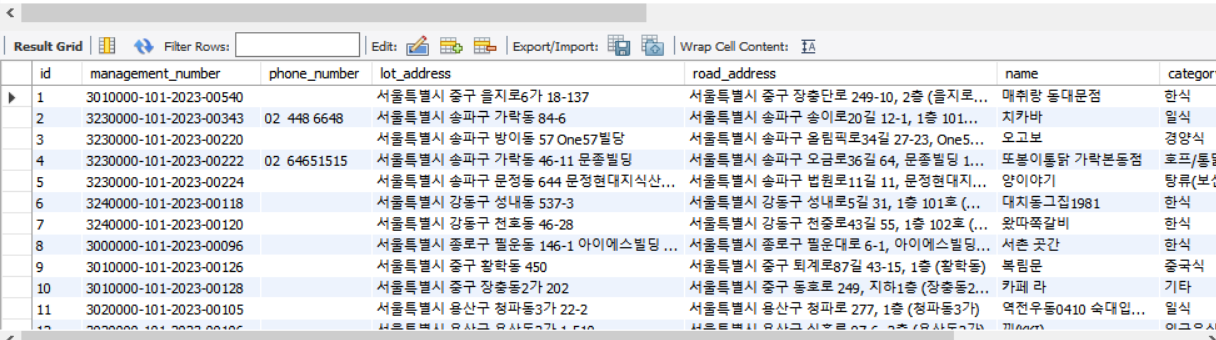
확인해보니 id가 자동증가로 만들어졌다.
csv 파일 가공
공공기관에서 제공하는 데이터를 카카오맵 api에서 제공하는 데이터에 맞춰서 가공을 해야 했다.
가게의 카테고리같은 경우 일관성이 없고, x좌표 y좌표 역시
카카오맵에서 제공하는 것이랑 달랐기 때문이다.
이에 파이썬을 활용해서 csv파일을 먼저 가공하고
DB에 데이터를 넣기로 했다.
import pandas as pd
import requests
import logging
from sqlalchemy import create_engine, text
# 카카오 API 설정
api_key = '6003feb2af025fb8772b8619ad7ce6fe'
headers = {
'Authorization': f'KakaoAK {api_key}'
}
# DB 설정
db_connection_str = 'mysql+pymysql://root:0000@localhost/data'
db_connection = create_engine(db_connection_str)
# 로깅 설정
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger()
def fetch_data_from_api(query):
url = f'https://dapi.kakao.com/v2/local/search/keyword.json?query={query}'
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
else:
logger.error(f"Error fetching data for query: {query}, Status Code: {response.status_code}")
return None
# DB에서 데이터 가져오기
query = "SELECT id, lot_address, phone_number, name FROM places LIMIT 20"
df = pd.read_sql(query, db_connection)
# API 호출 및 DB 업데이트
with db_connection.connect() as conn:
for index, row in df.iterrows():
address = row['lot_address']
name = row['name']
query = f"{address} {name}"
response_data = fetch_data_from_api(query)
if response_data:
logger.info(f"API response data for index {index}: {response_data}")
if response_data and 'documents' in response_data and len(response_data['documents']) > 0:
document = response_data['documents'][0] # 첫 번째 결과 사용
logger.info(f"Updating data for index: {index}, query: {query}")
update_query = text("""
UPDATE places
SET x = :x, y = :y, phone_number = :phone_number, category = :category
WHERE id = :id
""")
conn.execute(update_query, {
'x': document.get('x', row['x']),
'y': document.get('y', row['y'),
'phone_number': document.get('phone', row['phone_number']), # phone 번호가 있다면 업데이트, 없으면 기존 값 사용
'category': document.get('category_name', row[category]),
'id': row['id']
})
conn.commit() # 트랜잭션 커밋 추가
else:
logger.warning(f"No matching data found for index: {index}, query: {query}")위 방식은 db에 넣어놓은 데이터를 업데이트하는데, 이때
카카오맵 api를 호출해서 가게 정보를 받아온 뒤 db에 저장해놓은 레코드의 일부 칼럼을 카카오맵의 레코드로 변경한다.
대신에 스프링을 활용해도 괜찮을 거 같다.

답을 찾기 위해서 노력하는 사람