discountpolicy와 accommodation 테이블을 어떻게 분리할지 고민했다.
처음에는 discountpolicy를 accommodation에 임베디드 하는 방식을 썼다.

어차피 discountpolicy는 accommodation에 종속된다. 새로운 기능을 만들 때마다 테이블을 계속 만드는 것도 좋지 않다고 생각했다.
다만, 문제가 있었다.
호스트가 accommodation에 할인 정책을 설정했다고 하자. 할인기간이 지나면 할인 종료 상태로 변경해야 한다.
매일 자정에 시작일이 오늘이면 isOnSale을 true로, 종료일이 오늘이면 isOnSale을 false로 만드는 것이다.
로직을 구현해보니 모든 accommodation을 매일 순회해야하는 문제가 있었다.
accommodation 레코드의 수가 수 천개로 늘어나면, 매일 수천개의 레코드를 확인하고 변경해야 했다.
이를 피하기 위해서, DiscoutPolicy라는 테이블을 따로 만들기로 했다.
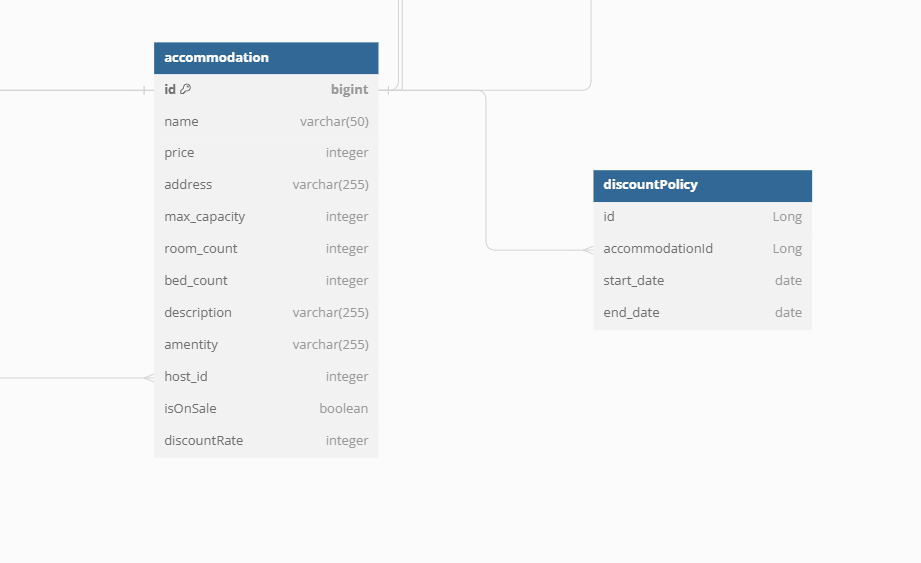
이렇게 두 개의 테이블로 분리했다.
@Scheduled(cron = "0 0 0 * * *")
public void checkAndUpdateDiscounts() {
log.info("Executing checkAndUpdateDiscounts");
List<Long> startDiscountIds = discountPolicyRepository.findByStartDate(today()).stream().map(DiscountPolicy::getAccommodationId).toList();
List<Long> endDiscountIds = discountPolicyRepository.findByEndDate(yesterday()).stream().map(DiscountPolicy::getAccommodationId).toList();
if (!startDiscountIds.isEmpty()) {
batchRepository.startDiscount(startDiscountIds);
}
// 배치 처리로 숙박 시설의 할인 종료
if (!endDiscountIds.isEmpty()) {
batchRepository.endDiscount(endDiscountIds);
discountPolicyRepository.deleteByEndDate(yesterday());
}
}이 api는 discountpolicy 테이블만 확인한다.
할인 기간이 지나면 discountpolicy 테이블에서 그 할인행사 레코드를 지우면 된다. 처음 방식과 비교했을 때, 매일 확인해야할 레코드의 개수가 줄어든다.
인덱스도 활용하면 어떨까?
discountpolicy에서 start_date와 end_date에 인덱스를 걸어놓으면, 더 빠르게 filtering이 가능할 것이라고 생각했다.
이 방법은 아직 유보 중이다.
다만, 인덱스를 걸어두었을 때는, read가 아닌 insert,update,delete 중 무엇이 동작이 자주 일어나면 비효율적일 수 있다고 한다.
인덱스 테이블의 인덱스를 계속 재정렬 해야 하기 때문이다.
read는 매일 테이블 전체에 걸쳐 한번은 일어난다.
insert, update, delete는 상시적으로 일어날 수 있다.
데이터가 그렇게 많지 않을 것이라는 점도 유보 판단에 영향을 주었다. host가 개별적으로 할인 행사를 입력하는 방식이고, 숙박 시설에 대한 할인 자체가 그렇게 자주 발생하는 이벤트가 아니다.
즉, 데이터 자체가 많지 않을 것이라는 판단이 든다. 그리고 인덱스를 걸면 db에서 인덱스를 위한 테이블이 필요해서 저장 공간이 낭비될 수 있다고 한다.
이러한 이유 때문에 discoutpolicy에서는 인덱스를 걸지 않을 생각이다.
