
UUID는 B-tree의 인덱스 성능을 저하할 수 있다.
ULID, UUID와 MySQL B-tree index
UUID는 random 성격의 id다. MYSQL에 PK로 넣을 때 성능에 저하를 줄 수 있다.
B-tree index에서 B는 'Balance'를 뜻한다. 이 밸런스를 유지하기 위해서 일정한 알고리즘이 index를 수시로 재정렬한다.
만약, 데이터가 무작위로 들어오면 이 밸런스 작업이 다양한 곳에서 수행되어 성능에 영향을 줄 수 있다고 한다.
보통 id를 auto_increment로 사용하는 편이었는데 이 방식은 위험하다고 들었다.
http://www.domain.com/user/info?userid=1
파라미터로 들어가는 userid의 값만 바꿔도, 다른 사람의 정보를 확인할 수 있는 것을 예측할 수 있습니다.
이처럼 예측가능한 모델이 되면 SQL Injection의 위험성이 존재하기 때문에, PK값을 그대로 넘겨주는 것은 바람직하지 않다고 한다.
고유값을 갖는 특정 값으로 데이터를 식별하기 위해서 UUID를 고려하는 경우가 많다.
한 마디로 UUID는 고유한 값을 갖는 키값으로서 활용할 수 있습니다. 하지만, MySQL에서 UUID를 도입할 때 고려해야 할 점이 있습니다.
다만, 앞서 말했듯 MYSQL은 순차적인 인덱스에 최적화돼있다.
MYSQL의 클러스터드 인덱스는 B- 트리 구조로 되어 있어 항상 정렬된 상태를 유지한다.
시퀀스를 기반으로 순차적으로 값이 올라가는 경우, 데이터를 삽입할 때 구성이 크게 변하지 않늖다.
하지만, 무작위 값을 인덱스로 사용하게 되면 데이터를 추가할 때마다 구조를 재배치해야 하므로 성능에 영향을 미치게 된다.
또한, 인덱스는 하드디스크에 저장이 되는데, 32bytes라는 비교적 큰 값을 사용하게 되면 인덱스 페이지의 크기가 커지는 문제가 있다.
DB에 대해 먼저 공부하자
DB에 대한 기본 지식이 부족하니까 사실 아직 명확하게 감이 안 잡힌다.
[MySQL] B-Tree로 인덱스(Index)에 대해 쉽고 완벽하게 이해하기
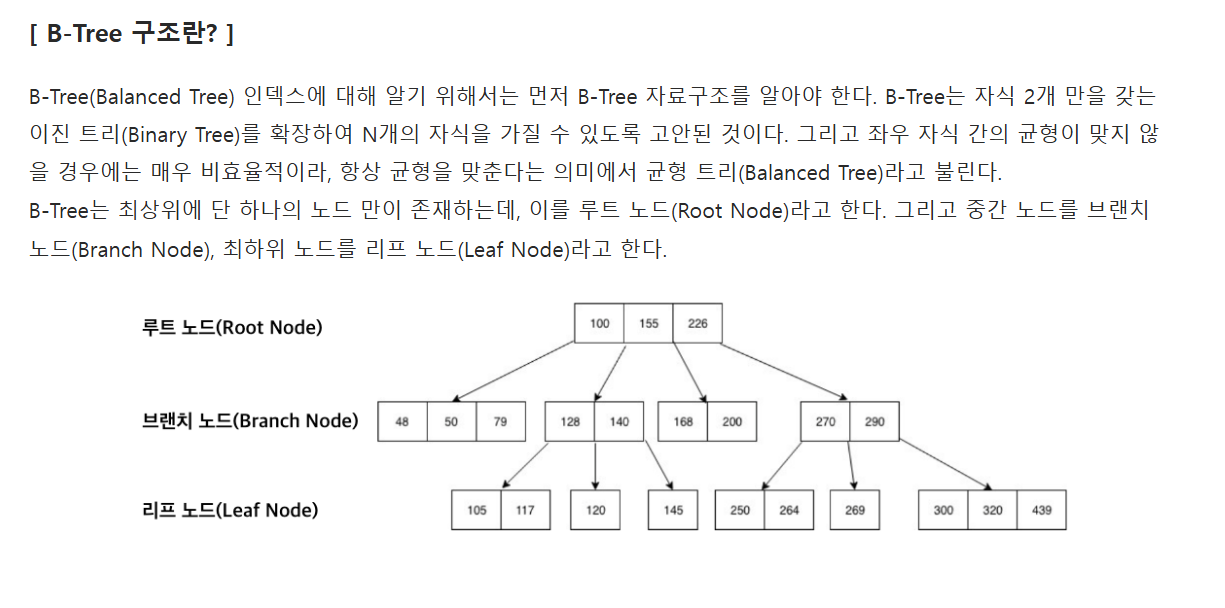
페이징
페이지란 디스크와 메모리에 데이터를 쓰고 읽는 최소 작업 단위다. 인덱스를 포함해 PK(클러스터 인덱스)와 테이블은 모두 페이지 단위로 관리된다. 쿼리로 1개의 레코드를 읽고 싶더라도 결국은 하나의 블록(페이지)를 읽어야 한다.
페이지에 저장되는 개별 데이터의 크기는 최대한 작게 하는 게 좋다. 그래야 많은 데이터를 저장할 수 있어서다. 데이터 크기가 크면 메모리에 캐싱할 수 있는 페이지 순느 줄어든다.
만약, 레코드를 찾는대 여러 페이지가 필요하다고 해보자. 추가 페이지를 읽는 디스크 I/O 때문에 성능이 떨어진다. 개별 데이터의 크기가 커지면 페이지 자체의 크기도 커져서, 메모리에 캐싱할 수 있는 페이지 수도 줄어든다.
인덱스
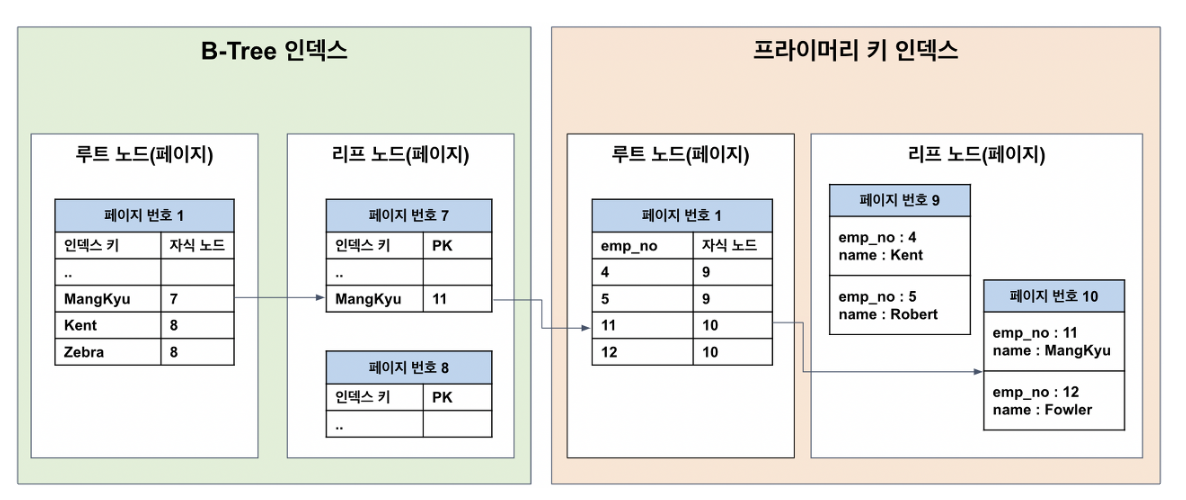
DBMS는 우리가 원하는 레코드가 어디있는지 모른다. 모든 테이블을 뒤져서 레코드를 찾아야 한다. 많은 디스크 읽기 작업이 필요해서 상당히 느리다.
인덱스가 있으면, 인덱스로 PK를 찾고 PK를 통해서 레코드가 저장된 위치를 바로 찾을 수 있다.
인덱스를 타는 것이 항상 효율적인 것은 아니다. 인덱스를 통해 레코드를 읽는 것이 4~5배 정도 비싸다. 읽어야 할 레코드 건수가 전체 테이블 레코드의 20~25%가 넘어서면 인덱스를 이용하지 않는 게 효율적이다. 이런 경우 옵티마이저는 인덱스를 이용하지 않고 테이블 전체를 읽어서 처리한다.
인덱스 사용에 영향을 주는 요소
(1)PK의 크기
인덱스가 PK가 아닌 실제 레코드의 주소를 갖게 할 수도 있다. 하지만, 이렇게 되면 레코드 주소가 변경될 때 모든 인덱스에 저장된 레코드 주소를 변경해야 한다. 이러한 오버헤드를 피하기 위해 인덱스는 레코드의 주소가 아닌 PK를 저장하고 있다.
또한,PK가 클수록 한 페이지에 담을 수 있는 인덱스 정보도 줄어들고, 메모리도 비효율적으로 사용된다.
(2) 카디날리티
특정 칼럼에 존재하는 데이터의 고유성을 의미한다. 카디날리티가 높을수록 중복도가 낮아지고, 유니크한 값이 많다는 뜻이다.
레코드 추가, 삭제, 수정
레코드 추가
레코드가 추가되면 인덱스도 같이 추가된다. 인덱스는 항상 정렬된 상태를 유지해야 하기 때문에, 새로운 인덱스가 어디에 들어가야 할지 위치 탐색이 이루어진다.
레코드 추가 비용이 1이라면 인덱스 추가 비용은 1.5 정도로 가정한다. 인덱스가 없다면 작업 비용이 1이고, B-Tree 인덱스가 3개 있다면 작업 비용을 5.5 정도(1+ 1.5*3)로 예측한다.
인덱스 추가 작업을 즉시 처리하지 않고, 메모리에 모아서 한 번에 쓰도록 지연시킬 수도 있다. 디스크 쓰기 횟수를 줄일 수도 있고, 요청 시에 메모리에서 바로 결과를 반환하는 등의 장점이 있다.
유니크 인덱스처럼 중복 체크 등의 무결성이 필요하다면 즉각 반영되기도 한다. 유니크 인덱스라면 중복 값의 유/무를 검사한 후에 저장해야 한다. 이때 중복된 값을 체크하기 위해서는 읽기 잠금을 쓰기를 할 때는 쓰기 잠검을 사용하는데, 이 과정에서 데드락이 아주 빈번히 발생한다.
유니크 인덱스는 반드시 유일성이 보장되어야 하는 경우에 사용하는 것이 좋다.
레코드 삭제
레코드를 삭제하면 인덱스도 삭제해야 한다. 인덱스의 리프 노드에 삭제 마킹만 하면 된다. 삭제 마킹 역시 디스크 쓰기 작업이므로 이 작업도 지연 처리될 수 있다.
레코드 수정
PK가 수정되면 최소 2번(DELETE, INSERT)의 쓰기 작업이 필요하다. 그리고 해당 테이블에 인덱스가 있다면 인덱스에도 추가 작업이 필요하므로 상당히 비용이 많이 든다.
인덱스가 수정되는 경우에는 테이블 뿐만 아니라 인덱스에 추가 작업이 반드시 필요하므로, 해당 작업도 비용이 많이든다. 인덱스와 PK는 최대한 변경을 피해야 한다.
적용해보기...
1) UUID 버전을 선택
UUID는 보통 V1, V4 중에 선택해야 한다고 한다.
이 중에서도 무작위 값인 V4를 많이 사용한다.
하지만, 무작위 값이 생성되면 순차적으로 만드는 것이 불가능하므로, 일부 규칙에 의거하는 V1을 선택할 수 있다.

2) 의존성 추가하기
implementation "com.fasterxml.uuid:java-uuid-generator:4.0.1" public static void main(String[] args) {
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
System.out.println(Generators.timeBasedGenerator().generate());
}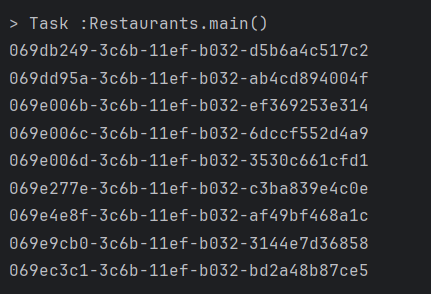
값이 앞에서부터 1씩 증가한다.(16진수)

uuid는 위 구성으로 만들어지는데
1, ,2, 3필드를 활용해서 순차적인 값을 만들 수 있다고 한다.
3) uuid 생성기 만들기
public static void main(String[] args) {
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
}
private static String getUUid() {
UUID newUuid = Generators.timeBasedGenerator().generate();
String[] uuidArr = newUuid.toString().split("-");
return uuidArr[2]+"-"+uuidArr[1]+"-"+uuidArr[0]+"-"+uuidArr[3]+"-"+uuidArr[4];
}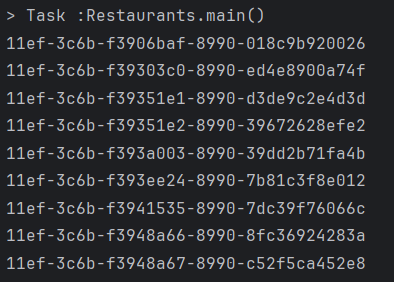
필드를 구분하는 '-'는 무의미해서 없애면 32개의 문자열이 된다. db에 저장하면 char(32)필드를 pk로 되는데,일반적으로 사용하는 BIGINT(8바이트)보다 4배 크다.
이를 개선하기 위해, CAHR(32)가 아닌 Binary형태로 변환해 BINARY(16)으로 저장하면 크기를 절반으로 줄일 수 있다고 한다.
물론, DB에 Binary 타입으로 저장하게 되면, 앞으로 UUID를 조회할 땐 사람이 식별할 수 있는 값으로 변환하는 과정이 필요하다.
binary 타입으로 변경
private static final char[] HEX_ARRAY = "0123456789ABCDEF".toCharArray();
public static void main(String[] args) {
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
System.out.println(getUUid());
}
private static byte[] getUUid() {
UUID uuidV1 = Generators.timeBasedGenerator().generate();
String[] uuidV1Parts = uuidV1.toString().split("-");
String sequentialUUID = uuidV1Parts[2]+uuidV1Parts[1]+uuidV1Parts[0]+uuidV1Parts[3]+uuidV1Parts[4];
String sequentialUuidV1 = String.join("", sequentialUUID);
ByteBuffer bb = ByteBuffer.wrap(new byte[16]);
bb.putLong(Long.parseUnsignedLong(sequentialUuidV1.substring(0, 16), 16));
bb.putLong(Long.parseUnsignedLong(sequentialUuidV1.substring(16), 16));
return bb.array();
}
public static String bytesToHex(byte[] bytes) {
char[] hexChars = new char[bytes.length * 2];
for (int i = 0; i < bytes.length; i++) {
int v = bytes[i] & 0xFF;
hexChars[i * 2] = HEX_ARRAY[v >>> 4];
hexChars[i * 2 + 1] = HEX_ARRAY[v & 0x0F];
}
return new String(hexChars).toLowerCase();
}
}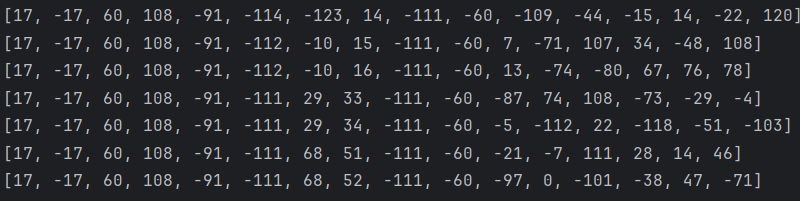
이렇게 결과가 나온다.
다른 사람이 테스트한 걸 보니까 그렇게 성능적으로 좋은 편은 아닌 거 같다.(나중에 프로젝트를 하면서 직접 테스트를 해보자)
그리고 16바이트인데... 8바이트 방식의 uuid 생성이 있다고 하니 고민이 된다.
UUID vs Auto Increment 중 PK 선택하기

increment PK가 노출이 취약하다는 특징으로만 봤을 때 만약 그 시스템이 고객 시스템이 아닌 사내 프로그램, 관리자 프로그램 같은 경우에는 악의적인 사용자가 있을리 없다는 가정을 할 수 있다.
익명 자유 게시판과 같이 누구나 쓸 수 있고 지울 수 있는 게시판이라면 UUID가 아니라 각각의 게시글, 댓글마다 비밀번호로 관리하게 해야한다.
글의 앞단에서도 설명했듯 95%의 상황에서는 Increment PK를 사용해야하고 보조키로 UUID를 사용하는게 대안이라고 한다.
결론적으로는 가장 이상적인 솔루션은 PK를 UUID로 사용하고 절대 외부로 노출 시키지 않는 것이라고 한다. 하지만 말 그대로 이상적이기 때문에 그렇게 하면 제대로 개발을 할 수 없다. PK 자체를 외부로 꺼내지 않으면 API 요청을 할 수 없기 때문이다.
그렇기에 실무에서는 Increment와 UUID를 같이 쓰거나 Increment만을 쓰는 것을 고려하는 것이 좋다.
