채팅방 구조는 아래와 같다.
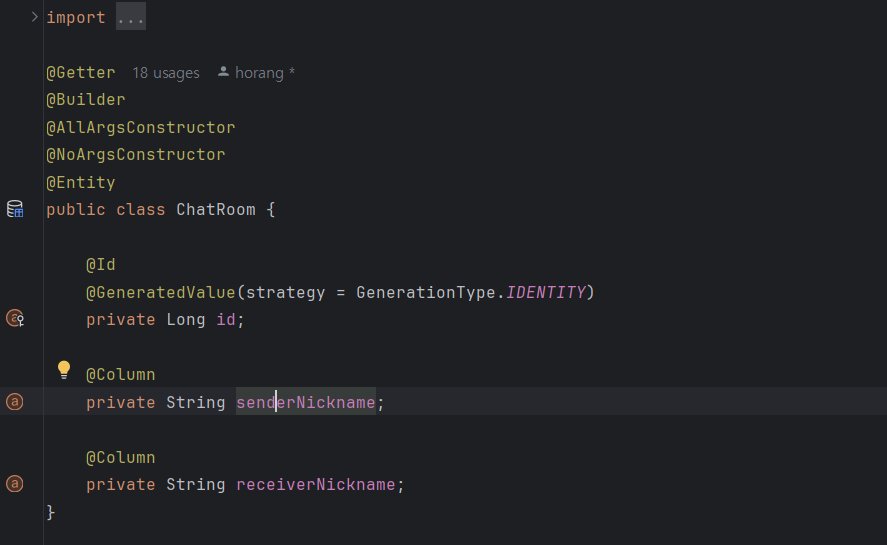
이렇게 채팅방이 있고
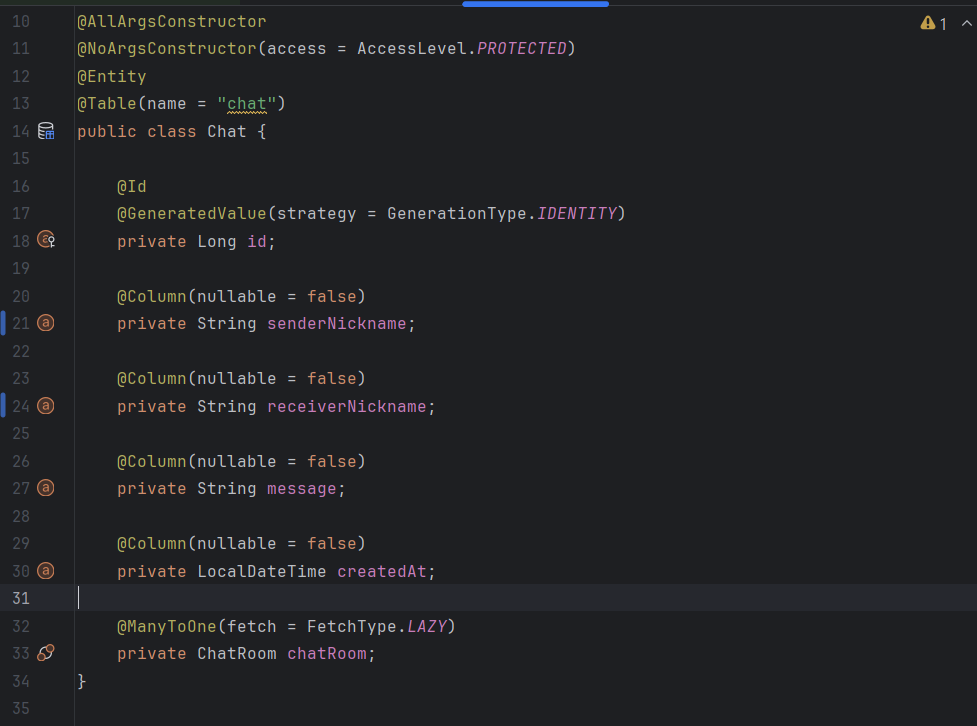
채팅 내역들이 채팅방을 연관관계로 갖고 있다.
채팅방 조회
채팅내역을 조회하기 위해서는 먼저 사용자 두 명이 속한 채팅방을 조회한다(Plaything에서는 일대일 채팅만 지원하고 있다)
db에 목데이터르 넣으려고 스프링 서버를 썼더니 너무 느렸다.
또, 속도를 빠르게 하려고 병렬 스트림을 썻더니 채팅방의 id가 불규칙적으로 만들어진 탓에...
(이러면 벌크 인서트를 하기가 어렵다)
그냥 JDBC template로 벌크 인서트하기로 했다.
public void setUp(List<Integer> list) {
String sql = "INSERT INTO chat (receiver_nickname, sender_nickname, message, created_at, chat_room_id) value(?,?,?,?,?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, String.valueOf(list.get(i)));
ps.setString(2, String.valueOf(list.get(i) + 1));
ps.setString(3, "hi");
ps.setTimestamp(4, Timestamp.valueOf(LocalDateTime.now()));
ps.setLong(5, list.get(i) + 1);
}
List<Object[]> batchArgs = list.stream()
.map(i -> new Object[]{String.valueOf(i), String.valueOf(i)})
.collect(Collectors.toList());
@Override
public int getBatchSize() {
return list.size();
}
});
}이걸 5000번 해주는 조금 무식(?)한 방법이다.
spring.jpa.properties.hibernate.default_batch_fetch_size=1000
spring.jpa.properties.hibernate.jdbc.batch_size=1000배치로 대량 작업을 할 땐 이 설정들을 추가해줘야 한다.
우선, 이용자 6천명이 각각 1개의 채팅방을 갖게 하고
오늘치의 채팅데이터를 1천 400만개 넣었다. 그리고 8일전과 12일전의 채팅 데이터를 총 3천만개 추가로 넣어주었다(Plaything에서는 일주일전까지의 채팅 데이터만 확인 가능하다)
이용자 3천명이 하루 300개씩의 채팅을 하면, 200일에만 약 1억 8천만개의 데이터가 생긴다...
지금 상황에서 이걸 테스트해보는 건 좀... 오버엔지니어링이고
채팅 데이터 4천만건을 넣어놓고 조회속도를 개선해볼 계획이다.
그렇다면, 이용자 1000명 정도가 하루 200개의 채팅을 200일동안 했다고 계산할 수 있다.
Plaything에서는 6개월 지난 후의 채팅 데이터는 삭제하고 있어서 이렇게 계산을 적용할 수 있다.
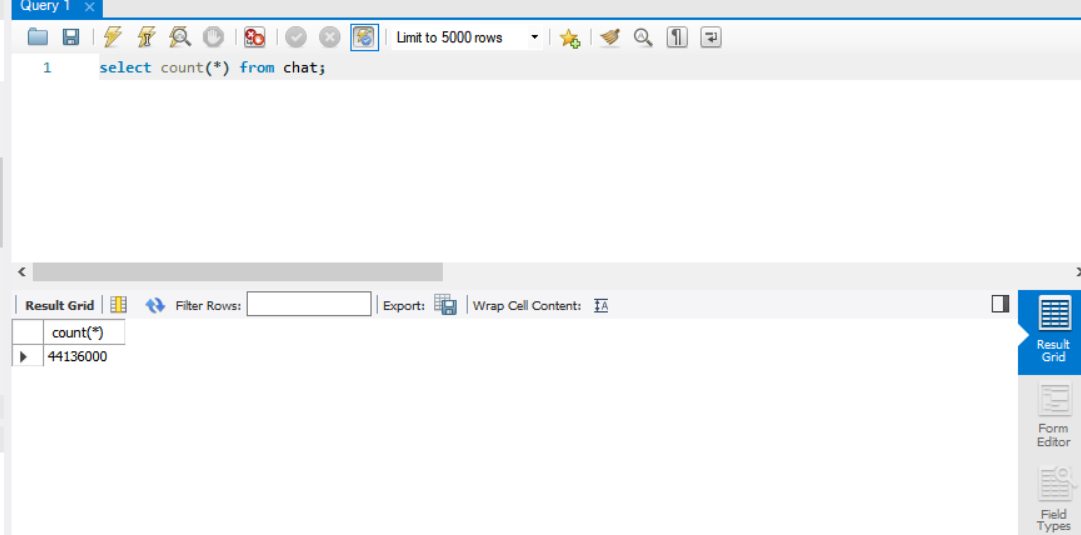
현재 4400만개의 데이터가 있다.
조회 속도가 어느정도로 나올까?
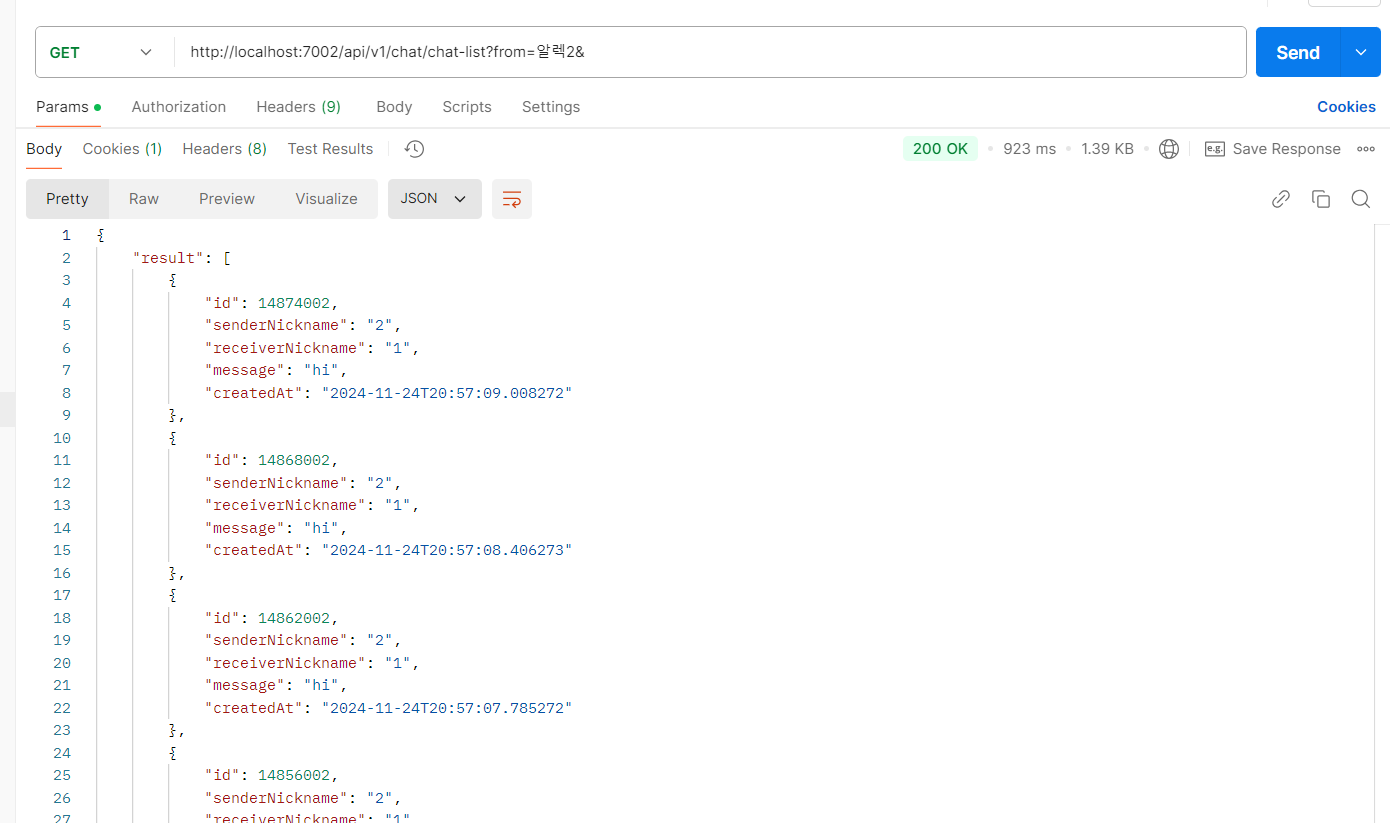
생각보다 속도가 준수하게 나왔다...!
내 생각에는 ChatRoom을 먼저 조회하고, 이걸 기반으로 인덱스를 타서 메시지를 조회하기 때문인 것으로 보인다.
메시지가 Chat_room과 연관관계를 갖기 때문. 워크 벤치에서 쿼리를 분석해보자.
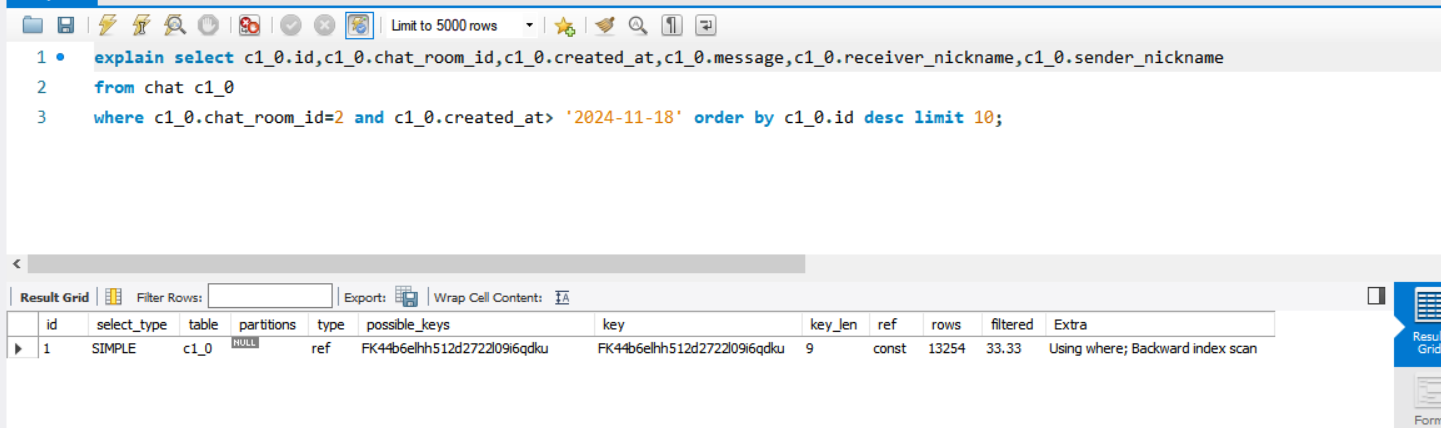
'FK44b6elhh512d2722l09i6qdku'는 Chat_room_id에 걸려 있는 외래키 인덱스키다.
현재 페이지네이션도 노오프셋 방식을 써서 성능에 영향을 많이 주진 않을 것이다.
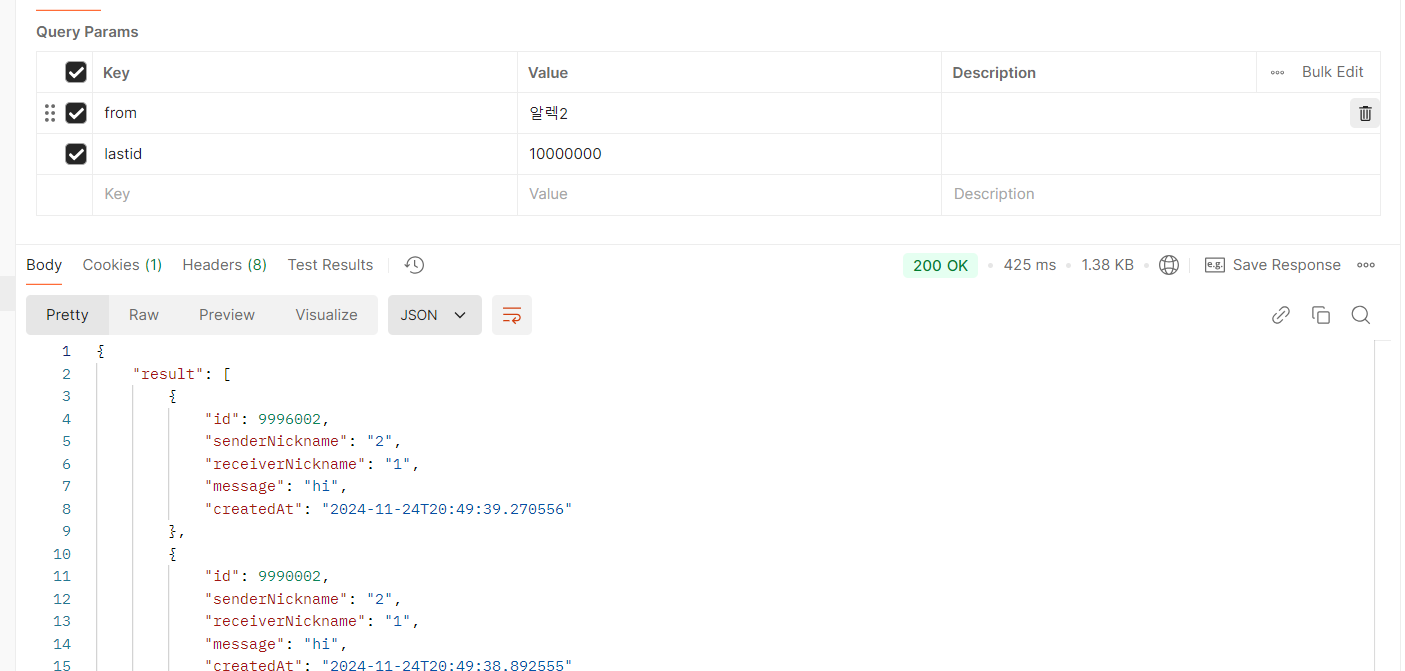
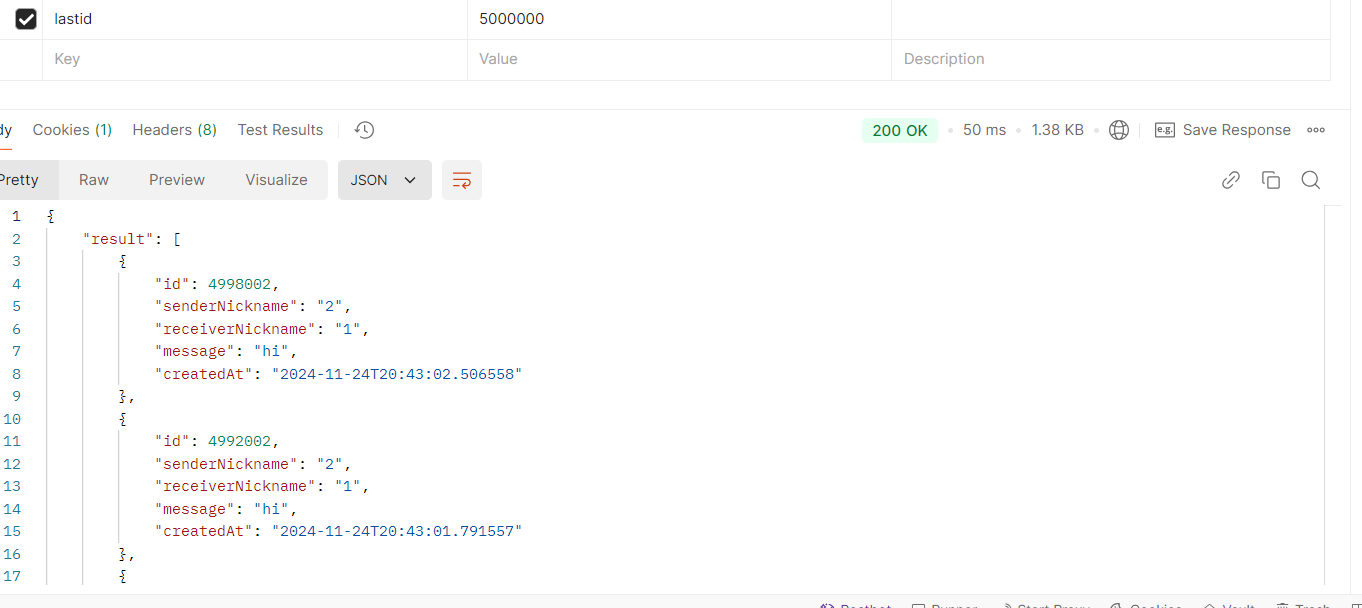
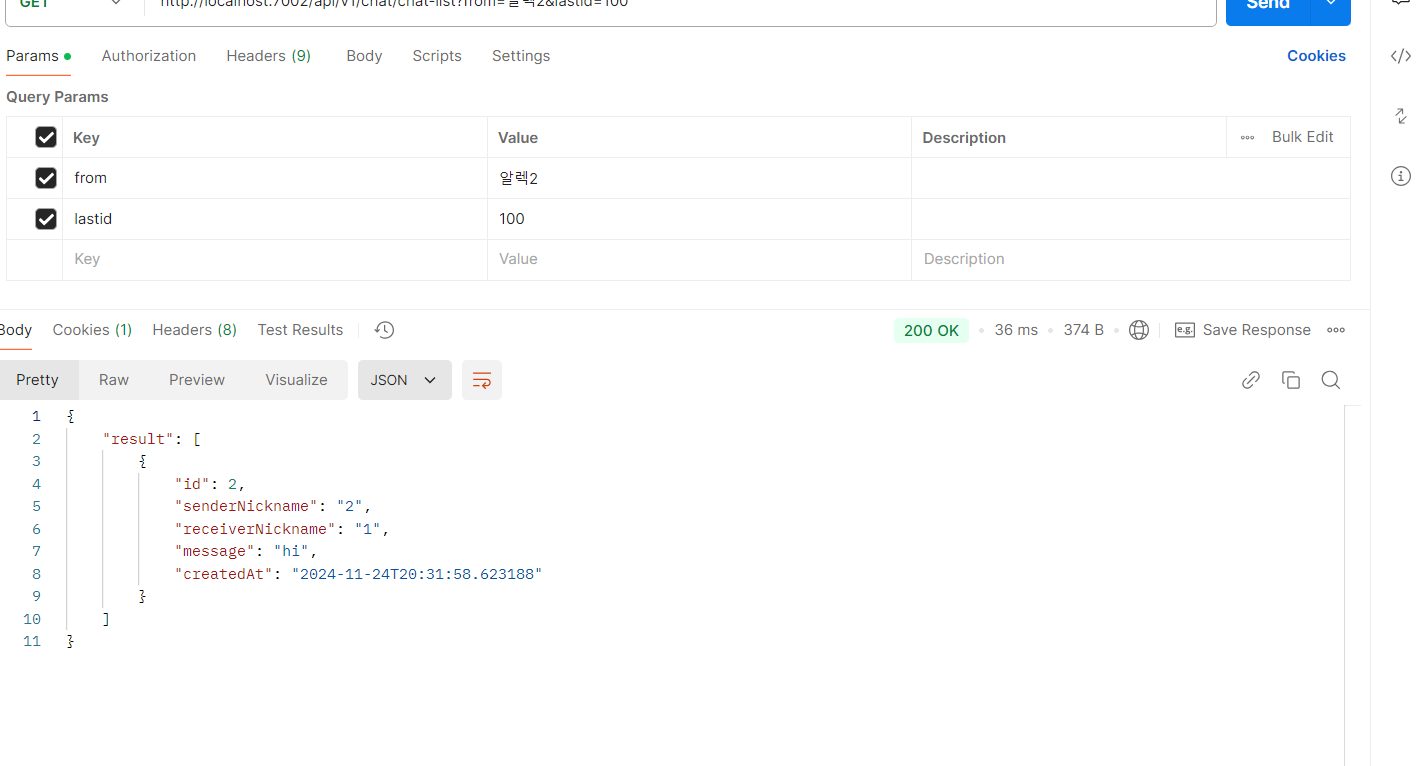
이렇게까지 페이지네이션을 많이 할 일은 없지만 성능적으로 상당히 괜찮다.
그렇다면, 현재 where절에서 날짜를 기준으로 조회를 하고 있으니
복합 인덱스를 걸어보는 게 어떨까 싶다.
CREATE INDEX idx_chat_room_created
ON chat (chat_room_id, created_at);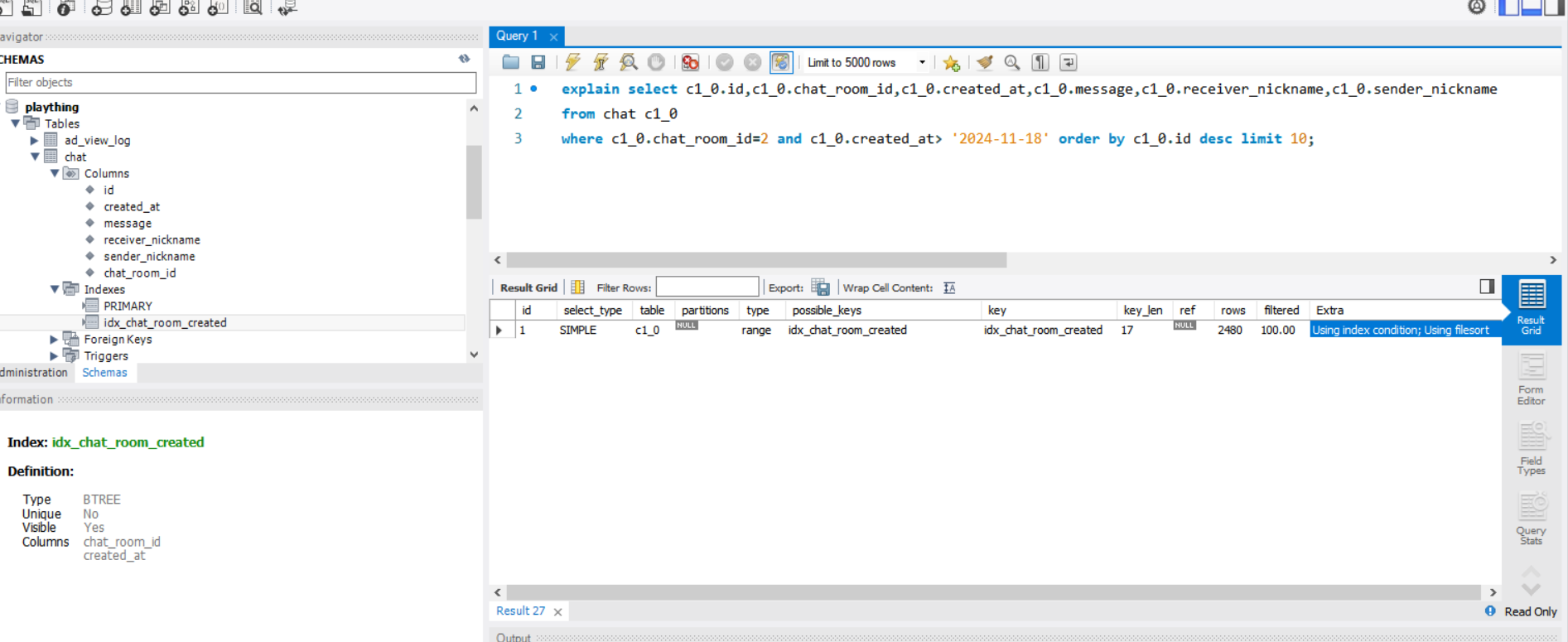
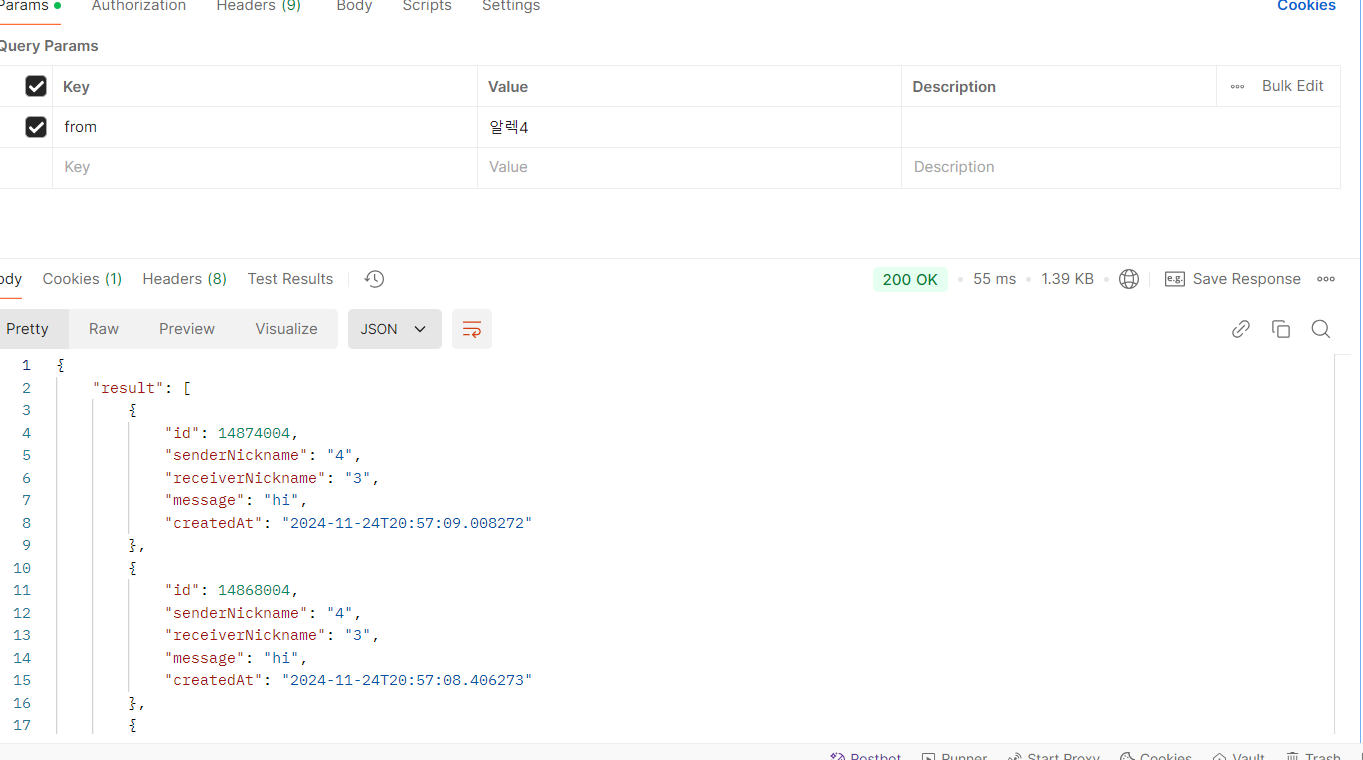
복합 인덱스를 거니 최근 데이터 조회는 923ms에서 55ms로 94% 개선됐다. 배수로 치면 16배 개선된 셈이다.
filter는 33%에서 100%로 개선됐다. 30%는 조회를 하고서 70%의 데이터가 불필요했다는 수치다. 스캔 효율성이 굉장히 높아진 것.
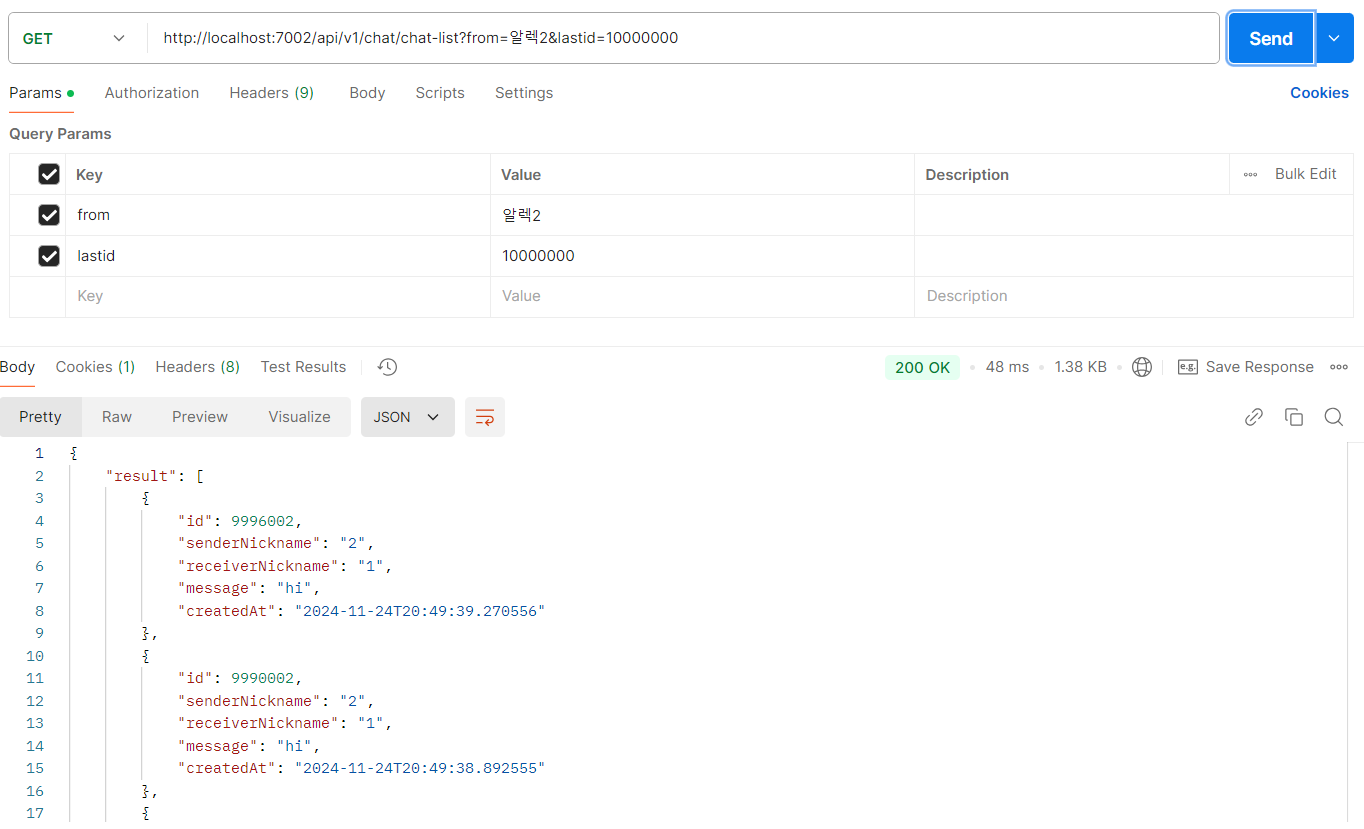
lastId가 10000000인 경우 425ms에서 48ms로 10배 개선됐다.
채팅방이 많아질 땐?
지금은 채팅 데이터가 4천만개, 채팅방은 6000개 정도다.
채팅방 숫자가 많아진다면 좀 느려질 수도 있지 않을까?
이용자 1명당 채팅방을 7개정도 만든다고 가정해보자.
6000명이니 약 4만2000개 정도가 생긴다.
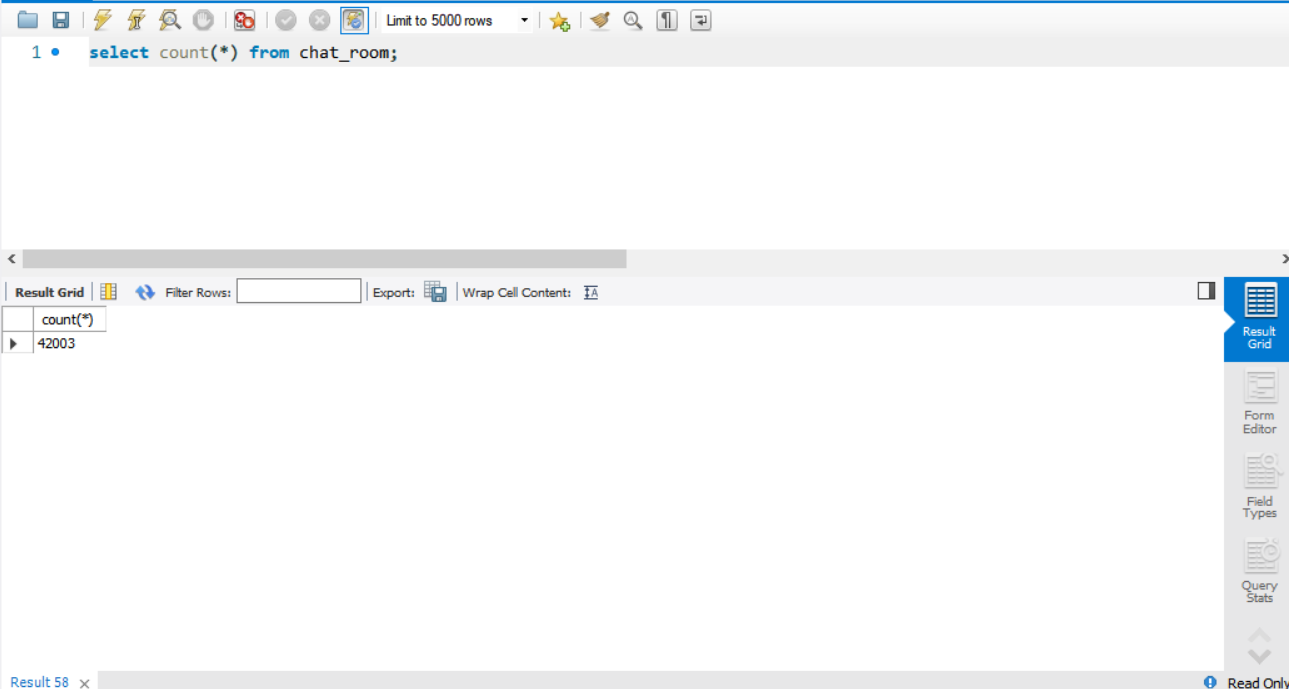
지금은 채팅방을 이용자들의 닉네임으로 조회하고 있다.
그런데, 연관관계를 맺지 않아서 따로 인덱스가 존재하지 않는다.

큰 차이는 없는 것으로 보인다.
다만, 채팅방은 연관관계를 맺는 방식으로 변경해야 한다. 그래야 채팅방에서 유저들에 대한 정보를 보여줄 수 있기에 ㅎㅎ.. 그렇게 되면 성능 개선이 미미하게나 발생할 것으로 보인다.
결론
결론적으로 MySQL을 써도 괜찮을까? 싶었는데 초기 단계에선 큰 무리가 없어 보인다.
물론, 채팅인만큼 insert가 많아지기에 여기서 성능 저하가 발생할 수 있다.
이를 추후에 다시 해결해보자.
