우선, 메시지의 경우에는 여러 방식으로 우회를 할 수 있다.
"계좌1번호"
"돈@@ 보내줘"
이런식으로 우회하는 걸 막으려면 우선 정규표현식으로 우회하는 표현들을 다 지워줘여 한다.
private static final Pattern FILTER_ALL_PATTERN = Pattern.compile(
// 1) 한글 사이의 모든 문자(자음/모음/영문자/특수문자/숫자) 제거
"(?<=[가-힣a-zA-Zㄱ-ㅎㅏ-ㅣ])[^가-힣a-zA-Z]+(?=[가-힣a-zA-Zㄱ-ㅎㅏ-ㅣ])|" +
// 2) 단어 앞뒤의 특수문자/숫자 제거 (자음/모음은 유지)
"^[^가-힣a-zA-Zㄱ-ㅎㅏ-ㅣ]+|[^가-힣a-zA-Zㄱ-ㅎㅏ-ㅣ]+$|" +
"\\s"
)
//2번째 정규표현식
^ : 문자열의 시작
$ : 문자열의 끝
+ : 하나 이상의 단어를 지우는 걸 해줘야 여러 특수문자가 겹쳤을 때 삭제된다다만, 이 경우는
!ㄱㅈ나 ㄱㅈ~ (계좌의 자음표현)
이런 것처럼 자음인 경우를 걸러내지 못한다.
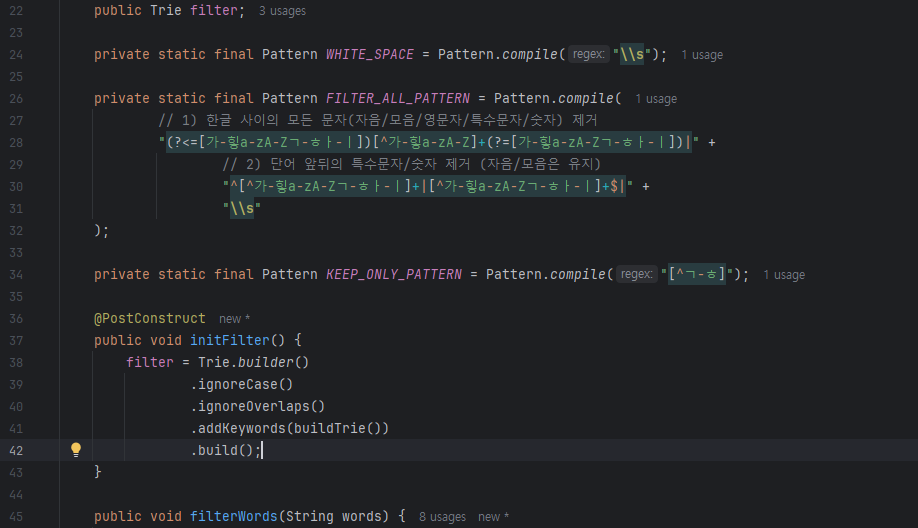
그래서, 자음이나 모음만 남겨놓는 방식으로 한번 더 메시지를 정리하고 두번에 걸쳐서 검증을 한다.
private static final Pattern KEEP_ONLY_PATTERN = Pattern.compile("[^ㄱ-ㅎ]");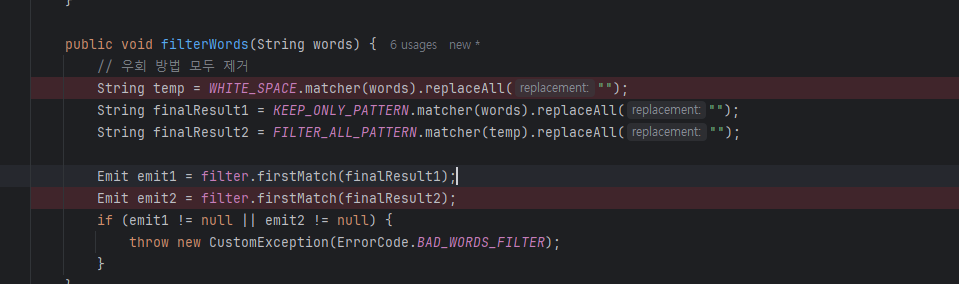
성능은 어떨까?
총 세번에 걸쳐서 정규표현식을 사용한다.
(참고로 정규표현식의 Pattern 객체를 만드는데 메모리를 많이 쓰기 때문에 이 경우는 캐시를 해두고 쓴다)
정규표현식+Trie 객체를 활용한 아호코라식 알고리즘를 같이 사용할 때
성능적인 이슈는 없을까?
한번 테스트해보자.
@Test
void testx() {
List<String> messages = generateTestInputs(5000); // 1000개의 다른 테스트 케이스
int iterations = 10;
long[] executionTimes = new long[iterations];
for (int i = 0; i < iterations; i++) {
long startTime = System.nanoTime();
for (String message : messages) {
try {
filteringService.filterWords(message);
} catch (CustomException e) {
// 예외는 무시하고 계속 진행
}
}
executionTimes[i] = System.nanoTime() - startTime;
}
// 평균 계산
double averageTime = Arrays.stream(executionTimes).average().orElse(0) / 1000000.0; // nano -> ms
// 최소, 최대 시간
double minTime = Arrays.stream(executionTimes).min().orElse(0) / 1000000.0;
double maxTime = Arrays.stream(executionTimes).max().orElse(0) / 1000000.0;
System.out.println("평균 실행 시간: " + averageTime + "ms");
System.out.println("최소 실행 시간: " + minTime + "ms");
System.out.println("최대 실행 시간: " + maxTime + "ms");
System.out.println("메시지당 평균 처리 시간: " + (averageTime / messages.size()) + "ms");
}
private List<String> generateTestInputs(int count) {
List<String> baseInputs = Arrays.asList(
"안녕하세요ㅋㅋㅎㅎ",
"금칙어~!관련#단어",
"ㄱㅊㅇ테스트123ABC",
"특수@#$문자!섞인~문장",
"일반적인 대화문장"
);
Random random = new Random();
List<String> testInputs = new ArrayList<>();
for (int i = 0; i < count; i++) {
// 기본 문장 선택
String base = baseInputs.get(random.nextInt(baseInputs.size()));
// 랜덤하게 변형
StringBuilder modified = new StringBuilder(base);
// 랜덤 위치에 특수문자 삽입
modified.insert(random.nextInt(modified.length()), "!@#$%^&*".charAt(random.nextInt(8)));
// 랜덤 위치에 숫자 삽입
modified.insert(random.nextInt(modified.length()), String.valueOf(random.nextInt(10)));
// 랜덤 위치에 자음/모음 삽입
modified.insert(random.nextInt(modified.length()), "ㄱㄴㄷㄹㅁㅂㅅㅇㅈㅊㅋㅌㅍㅎ".charAt(random.nextInt(14)));
testInputs.add(modified.toString());
}
return testInputs;
}
여러 상황마다 문장 5000개를 처리하는 데 시간이 얼마나 걸리는지 보자.
캐싱을 안 했을 때
지금은 레디스 연결을 안해둬서(굳이 해둘 필요가 없다)
DB에서 금칙어를 조회하고, 이걸 통해서 Trie를 빌드한다.
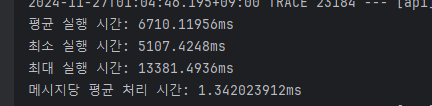
5천개를 처리하는데 대략 6초 정도가 걸린다.
그렇다면,
이 단어들을 db에서 조회하지않고
로컬 메모리에 올려놓은걸 읽고서 빌드하는 건 어떨까?
(지금은 단어를 세개만 올려뒀다)
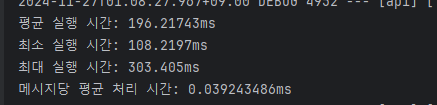
메모리에 올렸을 때도 굉장히 빠르다.
0.1초 정도 걸리는 수준
캐싱을 했을 때
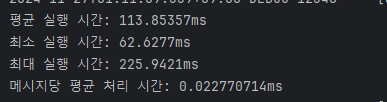
절반정도로 빨라졌는데
캐싱을 안해둬도 워낙 빨라서 큰 차이는 없다.
이 정도면 웹소켓 채팅에 쓰더라도 성능적인 이슈는 없을 것으로 보인다.
아무리 채팅이 많아봤자 실시간 채팅이 그렇게 활발한 서비스가 아니기도 하고
5000건의 메시지를 0.1초정도 만에 검증하는 거면 굉장히 빠르다.
결론적으로 Trie를 한개 캐싱해두기로 했다.
금칙어를 레디스에 넣고 이걸 가져와서 매번 빌드를 하면
중간중간 레디스에 요청을 계속 보내야하기에
오히려 더 느려질 수 있다.
