보통 동시성 문제는
선착순 쿠폰이나, 인기 상품의 재고를 차감할 때나 다룰 것이라고 생각했다.
그런데, 동시성을 서치해보니
포인트 충전 및 사용에서도 동시성 이슈를 고려한다는 글들이 꽤 보였다.
동시성이 언제 발생하는데?
동시성이 발생할 수 있는 상황을 정리해보자.
우선 생각나는 건 포인트 충전이 여러번 되는 경우다.
만약, 클라이언트에서 충전 API를 한번에 여러번 호출한다면?
실수로 코드를 그렇게 짤 수도 있고, 네트워크 문제로 재전송해야 하는 경우 그럴 수도 있다.
문제를 해결해보자
요청이 한번에 여러번 온 경우
이 경우는 기존 동시성 문제를 해결하는 방식으로는 막기 어려워 보인다.
그래서, 생각해본 게 클라이언트에서 요청에 대해서 uuid같은 식별자값을 보내주는 것이다.
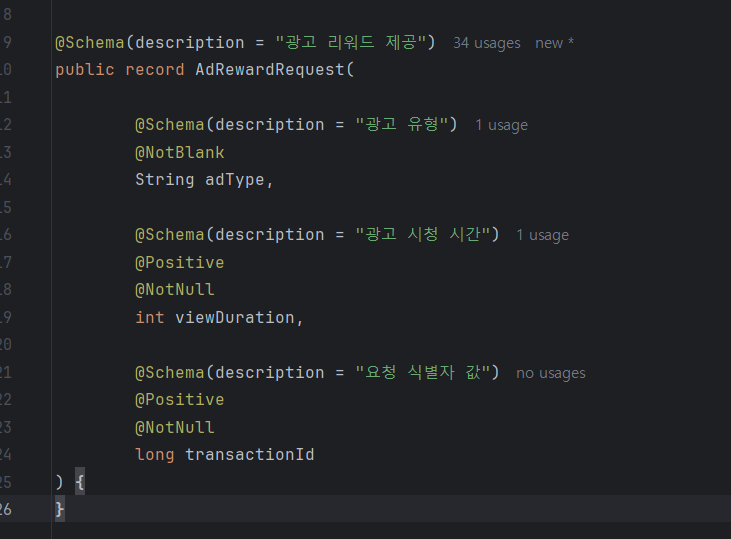
이렇게 DTO로 요청을 받고서 이제 처리를 해줘야 하는데
지금도 DB부하가 상당할 것이라고 생각을 했다.
로직이 복잡해지면서 작업 하나에도 DB를 여러번 조회하고 데이터를 저장하는 탓이다.
그래서, 이걸 레디스를 활용해야할지 DB에 엔티티로 추가해야할지 고민이 됐다.
레디스를 사용하면 DB부하를 줄일 수 있을 것이고(근데 사실 그렇게 크지는 않을 거 같다)
빠르게 검증이 가능하다. 그런데, 장애가 발생했을 때 단일장애지점이 될 수 있다.
즉 여기서 장애가 발생하면 전체 시스템에 장애가 생기는 것이다.
물론, 이를 해결하기 위해서 서킷브레이커를 쓰면 될 것이다.
레디스를 구현해보자.
@Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
public RedisTemplate<String, String> redisTemplate() {
RedisTemplate<String, String> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
// 일반적인 key:value의 경우 시리얼라이저
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
return redisTemplate;
}
}
@RequiredArgsConstructor
@Component
public class DuplicateRequestChecker {
private final RedisTemplate<String, String> redisTemplate;
public void checkDuplicateRequest(String userId, String transactionId) {
boolean isFirstRequest = Boolean.TRUE.equals(redisTemplate.opsForValue()
.setIfAbsent(userId + ":" + transactionId, "success", 10, TimeUnit.SECONDS));
if (!isFirstRequest) {
throw new CustomException(ErrorCode.TRANSACTION_ALREADY_PROCESSED);
}
}
}
공통적으로 사용할 로직이라서 이렇게 별도로 빼두었다.
처음에 레디스에 값이 저장이 안돼서 왜 그런가? 하고 봤더니
private final RedisTemplate<String, String> redisTemplate 이렇게 의존성을 만들어 놓고, redisConfig에서는 RedisTemplate<String, Object> redisTemplate 이렇게 타입을 지정을 해두어서 인식을 못한 것으로 보인다.

우선 DB에는 위처럼 transactionId가 저장된다.
이 칼럼에는 유니크 특성이 걸려 있어서 중복이 자동으로 걸러진다.
그런데, 유니크를 굳이 걸어야 할까 싶었다... 이 칼럼이 필요한 건 요청의 id를 영속화한다기보다는 동시 요청을 제어하기 위해서다.
그렇다면, 요청이 한번에 따다닥 들어올 때만 걸러내주면 되지 전반적으로 유니크할 필요까지는 없다.
유니크 칼럼을 넣으면 insert하기전에 한번 스캔해서 중복체크를 해야 하기 때문에 성능상의 이슈가 있을 것이라고 생각한다.
RealMySQL에 따르면, 조회에서는 둘다 성능상의 차이는 없지만 쓰기에서는 인덱스와 유니크 인덱스에 차이가 있다.
유니크 인덱스는 쓰기 작업을 할 때 중복된 값이 있는지 확인해야 한다. 이때 쓰기 잠금을 쓴다.
InnoDB 스토리지 엔진에서는 인덱스 키의 저장을 버퍼링하기 위해 체인지 버퍼(Change Buffer)가 사용된다. 그래서 인덱스의 저장이나 변경 작업이 상당히 빨리 처리되지만, 유니크 인덱스는 중복 체크를 반드시 해야해서 버퍼링하지 못한다.(Real MySQL)
이런 내용도 있다.
그래서, transactionId를 유니크 인덱스가 아닌 일반 인덱스로 변경하기로 했다. 레디스에 장애가 생겼을 때 DB에서 existBy를 통해서 이미 처리된 요청인지를 확인해야 하기 때문이다.
레디스 장애와 관련해서는 다음 글에서 다룬다.
