Plaything에서 사용할 수 있는 재화는 Key다.
Key를 얻는 방법은 캐시로 구매하거나, 이벤트에 참여해서 리워드로 받는 것이다.
그렇다면, 이 Key를 어떻게 설계해야할까?
이 기술블로그 글을 참고해서 설계를 했다.
Point의 사용 흐름을 추적할 수 있어야 한다
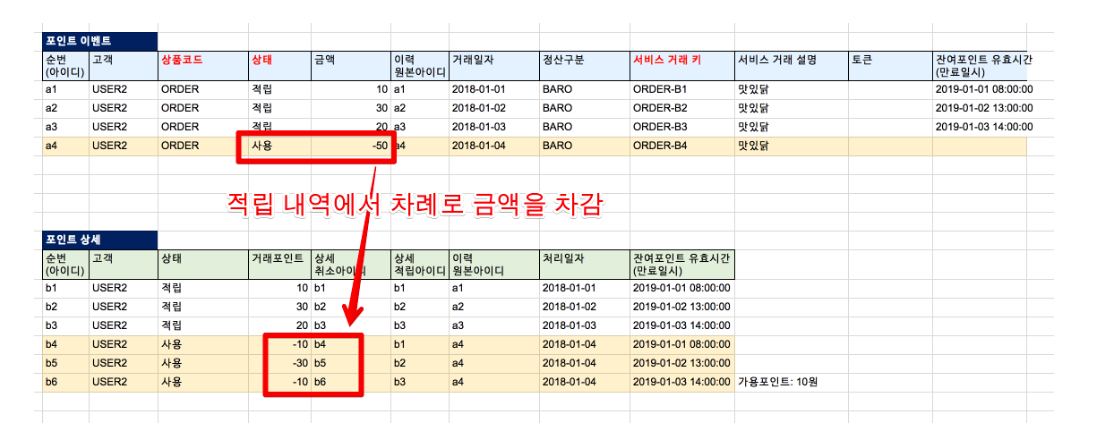
배달의민족에서는 point의 이력을 추적하기 위해서 point 레코드를 삭제하지 않는다.
적립과 사용 레코드를 둘다 추가하는 식이다.
public class PointKey {
/*
변동 내역을 추적하기 위해서 PointStatus로 관리한다.
레코드를 업데이트나 삭제하지 않고 생성, 사용으로 레코드를 만들고
group by를 통해서 개수를 구해오는 방식
*/
@Column(nullable = false)
@Enumerated(value = EnumType.STRING)
private PointStatus status;
}
public enum PointStatus {
EARN, // 적립
USED, // 사용됨
}
이 방식을 벤치마킹해서 적립과 사용 레코드를 만드는 방식을 쓸 계획이다.
이용자별 Point_KEY 테이블에서 적립과 사용을 각각 카운팅하고, 현재 사용 가능한 Point_key의 숫자를 조회한다.
다만,DB 부하를 걱정하지 않을 수 없다.
sum이나 group by는 레코드 수가 많아지면 부하가 커질 수밖에 없다.

이런 질문의 내용이 있었다

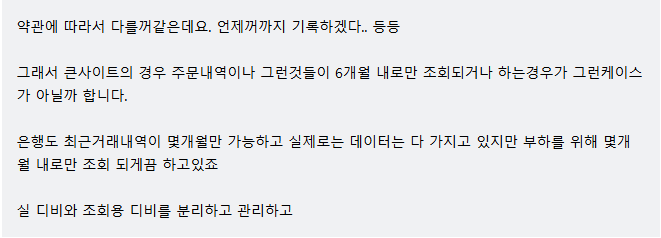
라고 한다.
보통은 조회 기간을 짧게 한다거나 디비를 분리해서 관리하는 것으로 보인다.
우리와는 잘 맞는 방식이야?
Plaything에서는 매칭에 KEY를 1개씩 사용한다.
포인트처럼 쪼개서 쓰는 게 아니라서, 복잡하게 할 필요가 있을까 싶었다.
그렇다면, KEY를 썼으면 레코드를 삭제하는 방식을 써야 할까?
그러면 키가 어떤 로그와 맵핑되는지 확인하기가 어려웠다.
적립, 사용, 환불, 매칭 이 모든 단계에 걸쳐서 로그를 쌓아야 하는데
키 레코드를 삭제하면 로그가 무의미해진다.
대체로 KEY를 사용하면서 생길 문제는 다음과 같을 것이다.
- 매칭을 하고 싶지 않았는데 실수로 잘못 눌렀다!
- 광고를 봤는데 PointKey가 생기지 않았다!
- 키 중복 사용
이럴 때, 결국 로그를 봐서 복구를 해줘야 한다. KEY를 여차저차 복구했다고 해보자. 기존의 Key 유효기간, 생성 방식 등에 대한 정보가 없다...!(로그로 있지만, 이걸 일일이 찾아줘야 하는 것)
조회 성능이 느려지지 않을까?
그래서, 삭제를 하지 않고 적립/사용 레코드를 쌓는 방식을 택하기로 했다.
하지만, 문제가 있다.
레코드가 너무 많아지면서 조회 성능이 문제가 될 수 있다는 것이다.
현재 MVP 목표 규묘는 1000명이다. 이후로 최종적으로 목표로 잡는건 2~5만명의 유저.
대략적으로 계산을 해보자.
현재 이용자는 하루 최대 13개의 Point_key를 받을 수 있다. 이용자 한명당 10개를 받는다고 가정하자.
서비스가 어느정도 잘 돼서 1만명의 유저를 모았다.
3000명의 유저가 6개월 내내 매일 10개의 Point_key를 받는다고 해보자.
(유효기간이 6개월이라서, 기간에 맞춰서 파티셔닝할 계획)
1100만개의 레코드가 쌓인다. 사용하는 것뿐 아니라, 사용한 것까지 생성을 해야 하니 2200만개의 레코드가 쌓인다.
조회 성능 테스트하기
이정도의 데이터를 DB에 넣어보고 인덱스를 걸어서 성능 테스트를 해보기로 했다.
DELIMITER //
CREATE PROCEDURE generate_test_users()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 5000 DO
INSERT INTO user (name, role, created_at, modified_at)
VALUES (
CONCAT('user', LPAD(i, 4, '0')), -- user0001, user0002, ...
'ROLE_USER',
NOW(),
NOW()
);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
-- 프로시저 실행
CALL generate_test_users();
-- 프로시저 삭제 (사용 후 정리)
DROP PROCEDURE generate_test_users;
========================
이용자 5천명을 넣는 쿼리
DROP PROCEDURE IF EXISTS generate_test_point_key;
-- 2. point_key 데이터 생성 프로시저
DELIMITER //
CREATE PROCEDURE generate_test_point_key()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE total_users INT DEFAULT 3000;
START TRANSACTION;
WHILE i <= total_users DO
INSERT INTO point_key (created_at, modified_at, expiration_date, is_valid_key, status, user_id)
WITH RECURSIVE numbers AS (
SELECT 1 AS n
UNION ALL
SELECT n + 1
FROM numbers
WHERE n < 1000
)
SELECT
NOW(),
NOW(),
NOW(),
1,
'EARN',
i
FROM numbers;
SET i = i + 1;
IF i % 10 = 0 THEN -- 10명마다 커밋
COMMIT;
START TRANSACTION;
END IF;
END WHILE;
COMMIT;
END //
DELIMITER ;
-- 실행 순서
CALL generate_test_point_key();
==배치로 Point key를 넣는 쿼리
2천만개의 데이터를 넣어주는 작업을 했다.
이용자 1부터 3000까지는 레코드가 약 7~8천개정도씩 있다.
SELECT SUM(
CASE
WHEN status = 'EARN' THEN 1
WHEN status = 'USED' THEN -1
ELSE 0
END)
FROM point_keys
WHERE user_id = ?;이 쿼리를 사용해서 count를 한다.
인덱스가 없을 때
우선, 인덱스를 삭제하고 테스트해보자.
SHOW CREATE TABLE point_key;
//외래키 제약조건 확인
ALTER TABLE point_key DROP FOREIGN KEY [외래키 이름]
ALTER TABLE point_key DROP INDEX 인덱스 이름
워크벤치에서 20초정도의 시간이 걸렸다.

포스트맨에서는 28초 정도가 걸렸다.
인덱스가 있을 때
이건 기본 설정이긴 하다. 외래키로 갖고 있는 user_id에서 인덱스가 생성되기 때문이다.
위에서 인덱스를 지웠으니, 다시 생성해주자.
CREATE INDEX idx_user_id ON point_key (user_id);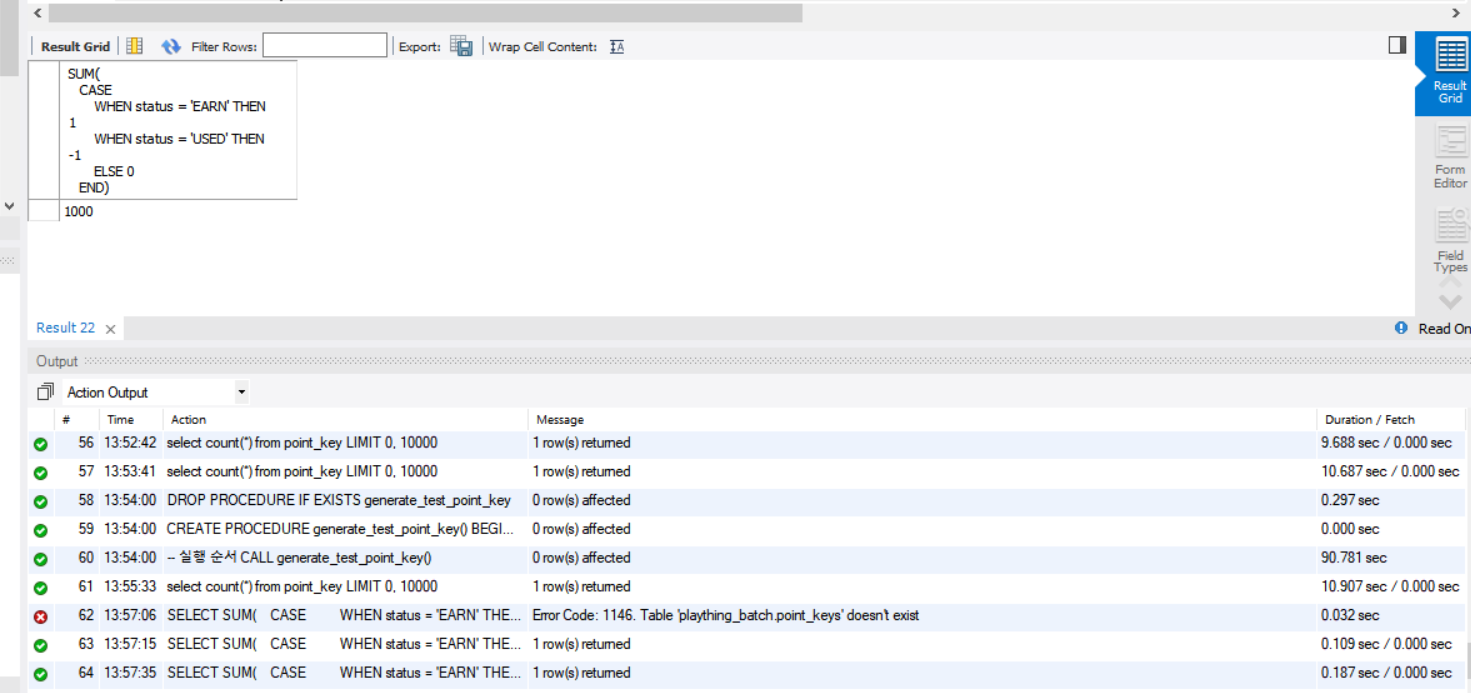
인덱스가 있을 때는 워크벤치에서 조회 시 0.1초 정도밖에 걸리지 않는다.
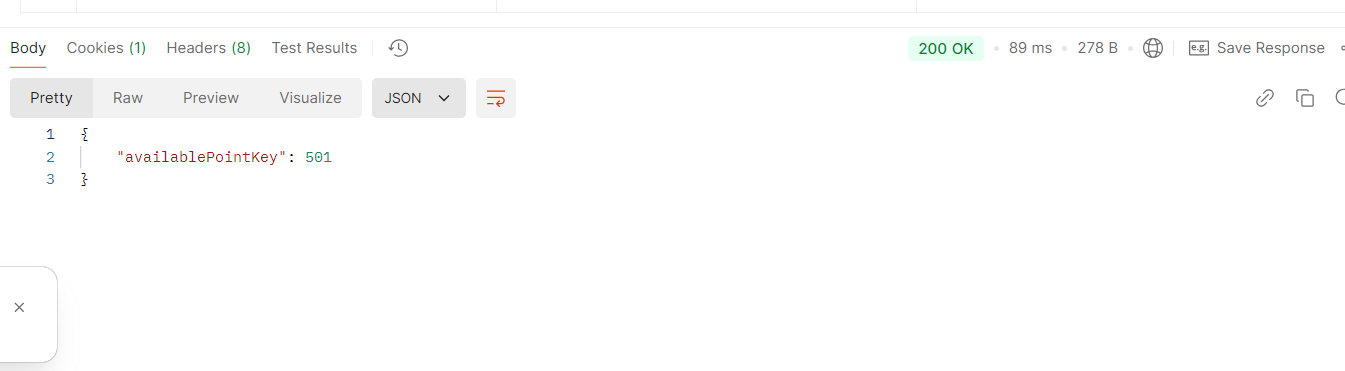
포스트맨에서는 89ms 정도로 굉장히 빠르다.
복합 인덱스는?
CREATE INDEX idx_user_id2 ON point_key (user_id, status);이렇게 status(EARN, USED) 두가지의 경우에도 인덱스를 걸고 해보자.

복합인덱스를 걸어도 단일 인덱스와 차이가 없다.
이미 단일 인덱스로도 굉장히 빠르게 조회가 되는데 복합인덱스를 걸 필요는 없을 거 같다. 인덱스 숫자가 많아질 수록 insert 과정에서 시간이 더 오래걸리는 탓이다.
