특성공학(feature engineering)
ML 모델을 위한 데이터 테이블의 컬럼을 생성하거나 선택하는 작업을 의미한다.
모델 성능에 영향을 많이 미치기 때문에 ML 응용에 있어서 굉장히 중요한 단계이기 때문에 전문성과 시간이 많이 드는 작업이다.
주성분 분석(Principal Component Analysis, PCA)
- 주성분 분석은 가장 널리 사용되는 차원 변형 기법(특성공학) 중 하나로, 원 데이터의 분포를 최대한 보존하면서 고차원 공간의 데이터들을 저차원 공간으로 변환한다.
- PCA는 기존의 변수를 조합(국어 + 영어 -> 어학)하여 서로 연관성이 없는 새로운 변수, 즉 주성분(principal component, PC)들을 만들어 낸다.
- n개의 관측치와 p개의 변수로 구성된 데이터를 상관관계가 없는 k개의 변수로 구성된 데이터로 요약하는 방식.
- 이때 요약된 변수는 기존 변수의 선형조합으로 원래 성질을 최대한 유지해야 한다.
- 선현대수 관점으로 볼 때 입력데이터의 공분산 행렬을 고윳값 분해하고 이렇게 구한 고유벡터에 입력데이터를 선형변환하는 것 이다.
- 이 고유벡터(행렬을 곱하더라도 방향이 변하지 않고 크기만 변하는 벡터)가 PCA의 주성분벡터로서 입력데이터의 분산이 큰 방향을 나타낸다.
- 주성분 분석에서 각 주성분은 원래 데이터의 분산을 가장 크게 하는 방향으로 정의되는데, 이는 데이터의 변동성을 가장 잘 설명하는 방향으로 설정된다.
iris data를 이용해 PCA 실습하기
from sklearn.datasets import load_iris
iris = load_iris()
n = 10 # 관측치 10개
x = iris.data[:n, :2]
df = pd.DataFrame(x)
print(df.head(2))
print()
print(x.shape) # (10, 2)
# PCA로 차원축소(꽃받침 길이, 꽃받침 너비 -> 한 개의 값)
pca1 = PCA(n_components=1) # 2개를 한개로
x_low = pca1.fit_transform(x) # 비지도 학습이므로 y값(target)은 주지 않는다.
print('x_low : ', x_low[:3], ' ', x_low.shape) # (10, 1)
x2 = pca1.inverse_transform(x_low) # 주성분 분석된 값을 원복 -> 똑같은 값이 아닌 근사한 값으로 됨
print('차원 복귀 후 x2 : ', x2, ' ', x2.shape) 또한,
원본 데이터.

주성분 분석 후 데이터.
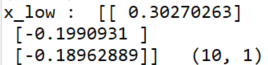
주성분 분석이 된 데이터들을 원복하였을 때.
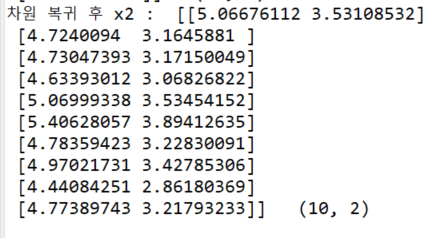
주 성분 분석을 통해 모양이 (10,2)였던 자료가 (10,1)로 바뀌었으며, 이전 값과 똑같은 값이 아닌 근사치로 바뀐 것을 알 수 있다.
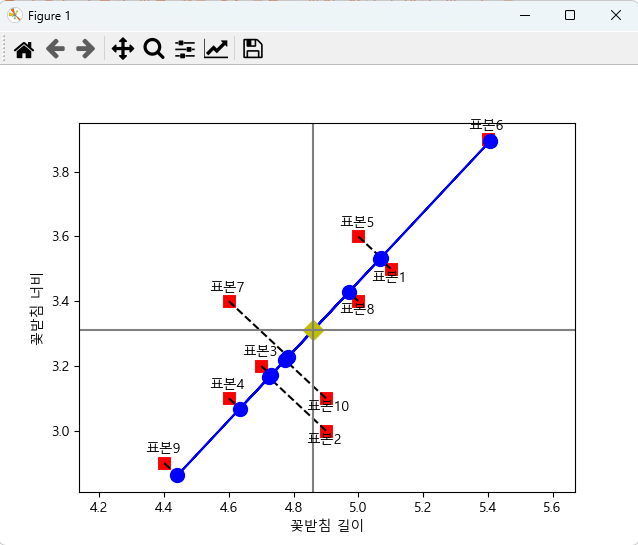
노란색 점을 주축으로 표본 값들이 투영된다.
2개의 2차원 데이터를 한개의 1차원 데이터로 직교한다.
결론
- 독립변수가 너무 많아 중요하다고 판단되는 변수들 몇 개만 뽑아 모델링을 하려고 할 때 주로 PCA를 사용한다.
- PCA의 본질은 차원 축소이다.
- 차원이 축소됐다는 것은 원본 데이터가 아니라 주성분을 이용해
분석 혹은 모델링을 진행한다는 것 이다.

남들과 함께 발자국을 남기는 까만호랭