과적합 방지하는 여러 방법들 중 데이터를 분리하는 방법과 KFold 교차검증에 대해 공부하였다.
(데이터는 iris : 붓꽃 데이터를 사용하였다.)
과적합 방지방법 1 : train test split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=123)
과적합 방지방법 2 : KFold 교차검증(cross-validation)
KFold 교차검증 :
- 데이터셋을 설정한 K개로 나누고, K개 중 하나를 검증세트로 나머지를 훈련 세트로 하여 모델을 학습시키고 평가한다.
- K개 모두가 한번씩 검증세트가 되도록 K번 반복하여 모델을 학습시킨 뒤 나온 평가지표들을 평균내서 모델의 성능을 평가한다.
- 데이터양이 충분하지 않을 때 사용한다.
ex) 데이터양이 적을 때 train / test split을 안하고 바로 KFold 검증함.
KFold 교차검증 하는 이유
데이터를 학습용/평가용 데이터 세트로 여러 번 나눈 것의 평균적인 성능을 계산하면, 한 번 나누어서 학습하는 것에 비해 일반화된 성능을 얻을 수 있기 때문
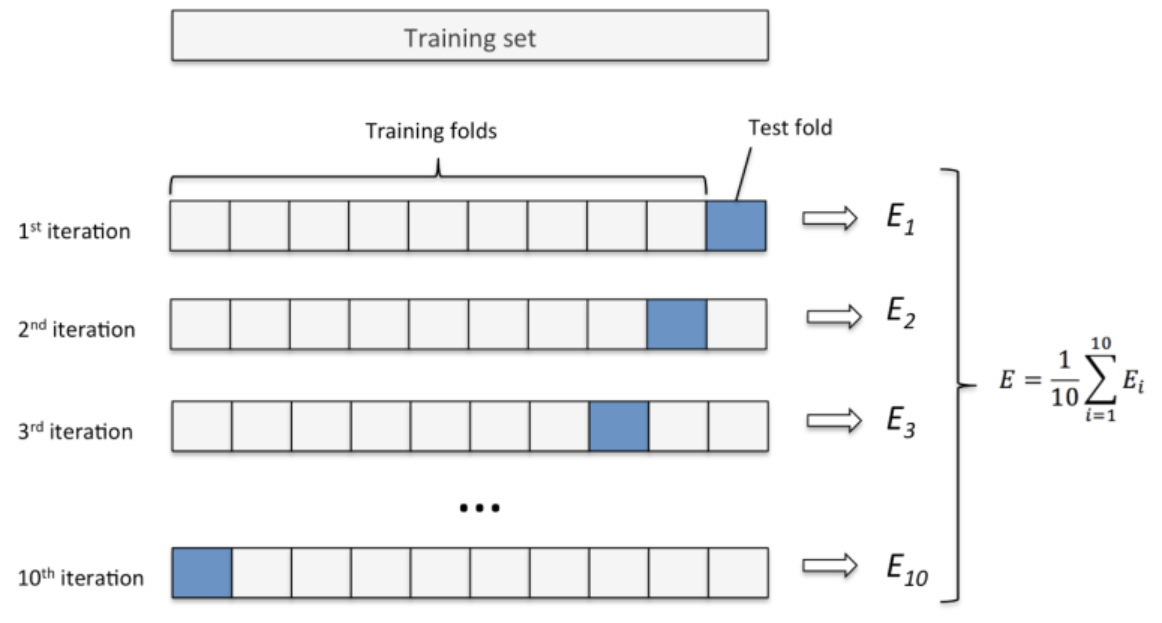
- KFold 검증 원리 코드
from sklearn.model_selection import KFold
import numpy as np
feature = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier(random_state=123)
kfold = KFold(n_splits=5) # 5개의 fold set로 분리한다는 뜻 --> 정확도도 5개가 나옴
cv_acc= [] # 정확도 담기 위해
print('iris shape : ', feature.shape) # (150, 4) 전체 행 수가 150
# 학습데이터 0.8(=4/5) * 150 = 120, 검증데이터 : 30
n_iter = 0 # 횟수,, 5번까지 진행
for train_index, test_index in kfold.split(feature):
# print('n_iter : ', n_iter)
# print(train_index, ' ', len(train_index))
# print(test_index, ' ', len(test_index))
xtrain, xtest = feature[train_index], feature[test_index]
ytrain, ytest = label[train_index], label[test_index]
# 모델 생성 중 학습 및 검증
dt_clf.fit(xtrain, ytrain) # train으로 학습
pred = dt_clf.predict(xtest) # test로 검증
n_iter += 1
# 반복할 때 마다 정확도 측정
acc = np.round(accuracy_score(ytest, pred), 3) # 실제값, 예측값 소수 3째 자리까지
train_size = xtrain.shape[0]
test_size = xtest.shape[0]
print('반복 수 : {0}, 교차검증 정확도 : {1}, 학습데이터 크기 : {2}, 검증데이터 크기 : {3}'.format(n_iter, acc, train_size, test_size))
print('반복 수 : {0}, 검증자료 인덱스 : {1}'.format(n_iter, test_index))
cv_acc.append(acc) # 반복할때마다 정확도가 나오는걸 위 cv_acc에 담음- 일반적으로 사용하는 KFold 검증 코드
from sklearn.model_selection import cross_val_score
data = iris.data
label = iris.target
score = cross_val_score(dt_clf, data, label, scoring='accuracy', cv=5)
print('교차 검증별 정확도 : ', np.around(score, 3))
print('검증 정확도 : ', np.round(np.mean(score),3))
# 출력
# 반복 수 : 1, 교차검증 정확도 : 1.0, 학습데이터 크기 : 120, 검증데이터 크기 : 30
# 반복 수 : 1, 검증자료 인덱스 : [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
# 24 25 26 27 28 29]
# 반복 수 : 2, 교차검증 정확도 : 0.967, 학습데이터 크기 : 120, 검증데이터 크기 : 30
# 반복 수 : 2, 검증자료 인덱스 : [30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
# 54 55 56 57 58 59]
# 반복 수 : 3, 교차검증 정확도 : 0.9, 학습데이터 크기 : 120, 검증데이터 크기 : 30
# 반복 수 : 3, 검증자료 인덱스 : [60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
# 84 85 86 87 88 89]
# 반복 수 : 4, 교차검증 정확도 : 0.933, 학습데이터 크기 : 120, 검증데이터 크기 : 30
# 반복 수 : 4, 검증자료 인덱스 : [ 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107
# 108 109 110 111 112 113 114 115 116 117 118 119]
# 반복 수 : 5, 교차검증 정확도 : 0.8, 학습데이터 크기 : 120, 검증데이터 크기 : 30
# 반복 수 : 5, 검증자료 인덱스 : [120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
# 138 139 140 141 142 143 144 145 146 147 148 149]
남들과 함께 발자국을 남기는 까만호랭