
선형 검색
선형 검색(linear search)은 정렬되지 않은 배열에서 특정 값을 찾기 위해 배열의 처음부터 끝까지 순차적으로 검색하는 알고리즘입니다.
list01 = [3, 2, 5, 7, 9, 1, 0, 8, 6, 4]
print(f'list01 : {list01}')
print(f'list01 lenght : {len(list01)}')
searchNum = int(input('숫자를 입력하세요 : '))
searchResultIdx = -1
n = 0
while True:
if len(list01) == n:
searchResultIdx = -1
break
elif searchNum == list01[n]:
searchResultIdx = n
break
n += 1
print(f'찾는 인덱스의 번호 : {searchResultIdx}')위에서 개념 설명한 것 처럼 list01안에서 사용자가 입력한 searchNum 값이 나올때까지 계속해서 while문이 실행되며 list01의 끝까지 확인하였을 때까지 발견 되지 않으면 searchResultIdx에 -1을 넣는 프로그램입니다.
보초법
list01 = [3, 2, 5, 7, 9, 1, 0, 8, 6, 4]
print(f'list01 : {list01}')
print(f'list01 length : {len(list01)}')
searchNum = int(input('숫자를 입력하세요 : '))
searchResultIdx = -1
list01.append(searchNum)
n = 0
while True:
if list01[n] == searchNum:
if n != len(list01) - 1:
searchResultIdx = n
break
n += 1
print(f'searchResultIdx : {searchResultIdx}')
print(f'list 개수 : {len(list01)}')보초법은 선형 검색의 종료 조건을 단순화하여 검색 효율을 높이는 방법입니다. 보초법에서는 검색 대상과 동일한 값을 리스트의 맨 끝에 추가합니다. 검색을 진행하면서 만약 리스트의 마지막 원소와 검색 대상이 일치하면 검색 성공으로 간주하고 반복을 종료합니다. 만약 일치하지 않으면 검색 실패로 간주하고 -1을 반환합니다.
실습
listData = [4, 7, 10, 2, 4, 7, 0, 2, 7, 3, 9]
n = 0
searchNum = int(input('숫자 입력하세여 : '))
searchResultIdx = []
listData.append(searchNum)
while True:
if listData[n] == searchNum:
if n != len(listData) - 1:
searchResultIdx.append(n)
else:
break
n += 1
print(f'listData :{listData}')
print(f'listData length:{len(listData)}')
print(f'searchResultIdx :{searchResultIdx}')1개만 찾는게 아닌 리스트 내의 모든 위치를 찾는 프로그램입니다.
이진 검색
이진 검색(binary search)은 정렬된 배열에서 특정 값을 찾기 위해 배열을 반씩 나누어 검색하는 알고리즘입니다. (제로베이스 강의 자료 참고)
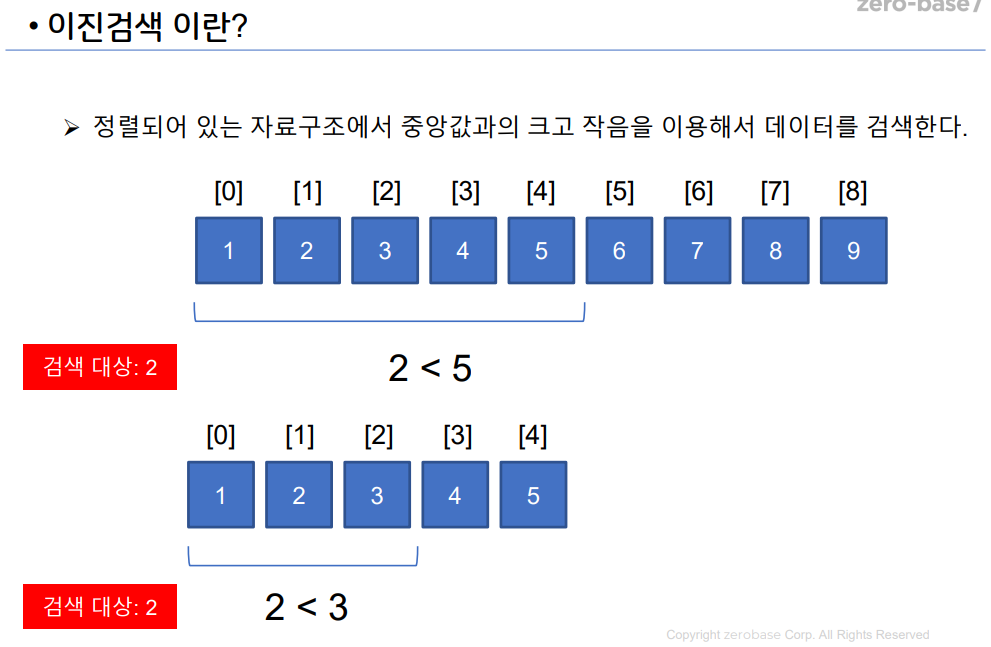
다음 그림과 같이 배열안에서 반을 나눠 찾는 값이 그 값보다 큰지 작은지를 확인하고 작으면 다시 그 반으로 나눠진 값에서 찾는값보다 큰지 작은지를 찾는과정을 반복하는 알고리즘입니다.
datas = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
print(f'data : {datas}')
print(f'data length : {len(datas)}')
searchData = int(input('search data : '))
searchResultIdx = -1
staIdx = 0
endIdx = len(datas) - 1
midIdx = (staIdx + endIdx) // 2
midVal = datas[midIdx]
print(f'midIdx : {midIdx}')
print(f'midVal : {midVal}')
while searchData <= datas[len(datas) - 1] and searchData >= datas[0]:
if searchData == datas[len(datas) - 1]:
searchResultIdx = len(datas) - 1
break
if searchData > midVal:
staIdx = midVal
midIdx = (staIdx + endIdx) // 2
midVal = datas[midIdx]
print(f'midIdx : {midIdx}')
print(f'midVal : {midVal}')
elif searchData < midVal:
endIdx = midVal
midIdx = (staIdx + endIdx) // 2
midVal = datas[midIdx]
print(f'midIdx : {midIdx}')
print(f'midVal : {midVal}')
elif searchData == midVal:
searchResultIdx = midIdx
break
print(searchResultIdx)첫 번째 부분에서 데이터 목록과 검색 데이터를 입력하고 코드의 두 번째 부분에서는 데이터 목록의 중간 인덱스와 값을 계산합니다.
마지막 부분은 데이터 목록의 중간 값이 검색 데이터보다 크거나 같으면 데이터 목록의 후반부를, 데이터 목록의 중간 값이 검색 데이터보다 작으면 데이터 목록의 전반부를 반복적으로 나눕니다. 데이터 목록의 중간 값과 검색 데이터가 같으면 검색 데이터가 발견된 것으로 간주하고 반복을 종료합니다.
순위
순위(rank)는 정렬된 배열에서 특정 값이 몇 번째에 있는지 나타내는 값입니다.

import random
nums = random.sample(range(50, 101), 20)
ranks = [0 for i in range(20)]
print(nums)
print(ranks)
for idx, num1 in enumerate(nums):
for num2 in nums:
if num1 < num2:
ranks[idx] += 1
print(nums)
print(ranks)
for idx, num in enumerate(nums):
print(f'num : {num} \t idx : {ranks[idx] + 1}')50~100사의 무작위의 난수 20개의 순위를 맥이는 코드인데 우선 rank라는 리스트를 하나 더 만들어 0으로만 20개를 채우고 각 난수에 대해, 다른 모든 난수와 비교합니다. 만약 현재 난수가 다른 난수보다 작다면, 현재 난수의 순위를 1 증가시킵니다.
이렇게 되면 다음 그림과 같이 순위가 결정되게 됩니다.

실습
학급 학생(20명)들의 중간고사와 기말고사 성적을 이용해서 각각의 순위를 구하고, 중간고사 대비 기말고사 순위 변화(편차)를 출력하는 프로그램을만들어 보자.(시험 성적은 난수를 이용한다.
class RankDeviation:
#모듈
def __init__(self, mss, ess):
self.midStudentScos = mss
self.endStudentScos = ess
self.midRank = [0 for i in range(len(mss))]
self.endRank = [0 for i in range(len(ess))]
self.rankDeviation = [0 for i in range(len(mss))]
def setRank(self, ss, rs):
for idx, num1 in enumerate(ss):
for num2 in ss:
if num2 < num1:
rs[idx] += 1
def setMidRank(self):
self.setRank(self.midStudentScos, self.midRank)
def getMidRank(self):
return self.midRank
def setEndRank(self):
self.setRank(self.endStudentScos, self.endRank)
def getEndRank(self):
return self.endRank
def printRankDeviation(self):
for idx, mRank in enumerate(self.midRank):
deviation = mRank - self.endRank[idx]
if deviation > 0:
deviation = '↑' + str(abs(deviation))
elif deviation < 0:
deviation = '↓' + str(abs(deviation))
elif deviation == 0:
deviation = '=' + str(abs(deviation))
print(f'mid_rank :{mRank}\t end_rank:{self.endRank[idx]}\t Deviation: {deviation}')
#main 프로그램
import random
import rankmod as rm
midStuScos = random.sample(range(50, 100), 20)
endStuScos = random.sample(range(50, 100), 20)
rd = rm.RankDeviation(midStuScos, endStuScos)
rd.setMidRank()
rd.setEndRank()
print(rd.getMidRank())
print(rd.getEndRank())
rd.printRankDeviation()
