Introduction
어플리케이션에서 API 성능향상을 위해 Database Connection Pool의 개수를 조절해 보았습니다. DBCP의 개념과 어떻게 동작하는지 정리하는 개념 글 입니다.
DBCP가 필요한 이유
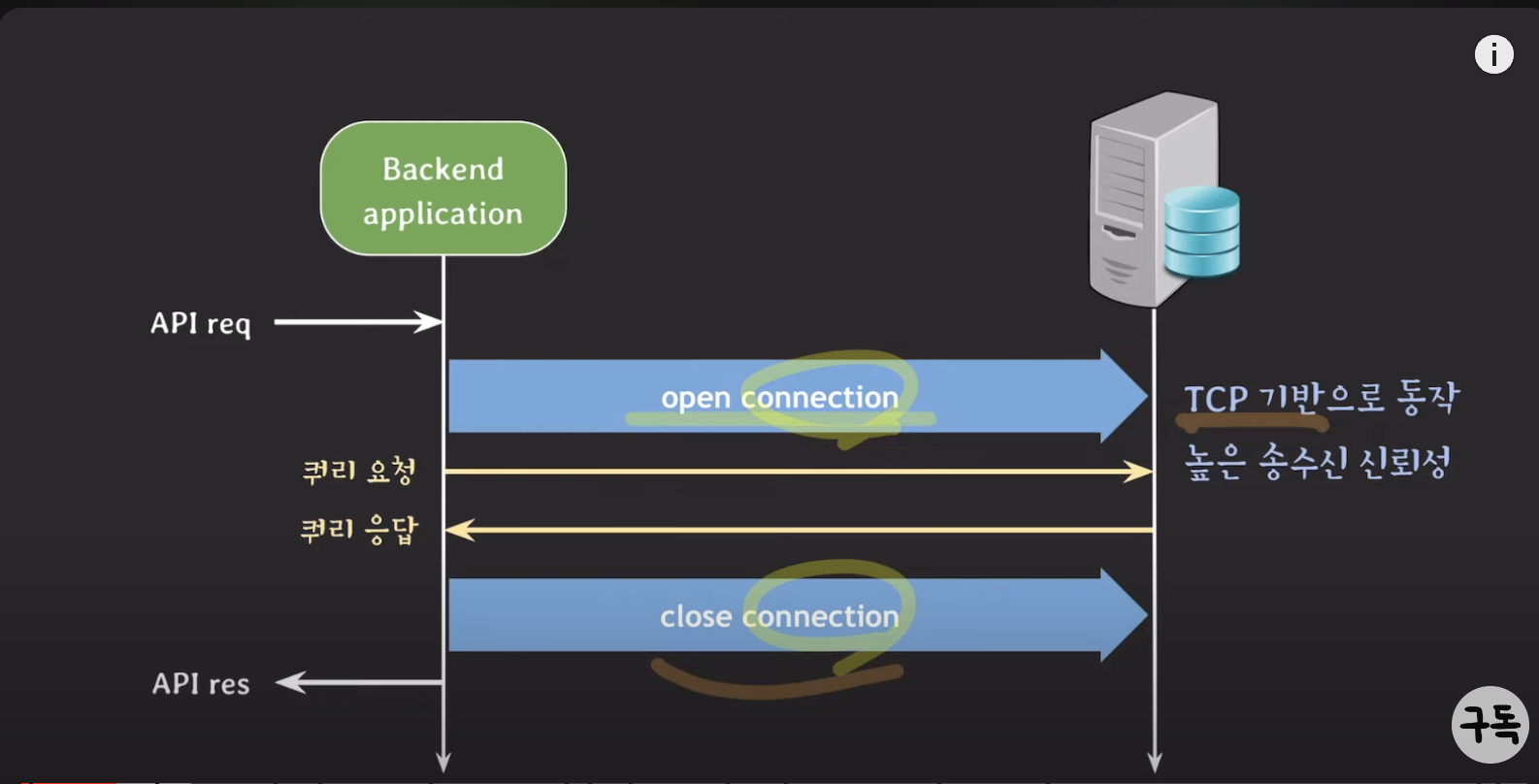
-
위의 사진은 백엔드 서버로 API가 요청을 보내고, DB를 검색할일이 있을 때를 나타낸 Sequence Diagram입니다.
-
DB와의 통신을 할 때 대부분 TCP를 통해 연결을 하게됩니다. 이 때 TCP의 Three-way handshake, Four-way handshake를 통해 연결을 하고 끊기 때문에 네트워크 비용이 꽤나 들게 됩니다.
-
이러한 네트워크 비용을 줄이기 위해 미리 커넥션을 만들어 놓고 pool에 모아놓는 개념을 DB Conneciton Pool 이라고 합니다.
(연결을 계속 유지하고 어플리케이션에서 들고 있다는 개념)
DBCP 설정들
여러 DBCP를 구현해놓은 라이브러리들이 있었으나, 스프링 같은 경우 Hikari CP를 채택하고 제공하고 있습니다.
Hikari CP Settings (Backend Application)
-
minimumidle: pool에서 유지하는 최소한의 idle connection 수
-
maximumPoolSize: pool이 가질 수 있는 최대 connection 수 (우선순위가 더 높은 옵션)
(최대 connection 수 = idle connection + active(in-use) connection)
(이 세팅을 이용해서 성능측정을 해보았습니다.) -
maxLifetime: pool에서 connection의 최대 수명
(maxLifeTime을 넘기면 idle일 경우 pool에서 바로제거 active인 경우 pool로 반환된 후 제거. 주의 DB Settings의 conneciton time limit 보다 짧게 설정 해야함. 그렇지 않으면, db 쿼리 날리기전에 application 로직이 동작하다가, db connection time limit에 의해 exception이 발생할 수 있음..) -
connectionTimeout: pool에서 connection을 받기 위한 대기 시간
(connection을 획득하는 과정에서 기아현상이 발생하면.. exception이 날거라 생각이 든다)
DB Settings
-
max_connections: client와 맺을 수 있는 최대 connection 수
(이 때 WAS를 여러개 띄울 때를 고려해서 DB의 max_connection 수를 고려해서 세팅해놔야 합니다.) -
wait_timeout: connection이 inactive할 때, 다시 요청이 오기까지 얼마의 시간을 기다린 뒤에 close할 것인지를 결정
( idle(대기하는) connection 수가 많아졌을 때를 대비하기 위한 설정)
적절한 connection 수를 찾아보자.
- 부하테스트 환경에서, TPS나 response time이 변하는 변곡 지점에서의 active connection 수를 확인한다.
- 이 때, maximumPoolSize와 active connection이 같다면, connection Pool의 부족 문제 일 수 있다. 값을 조정하면서 적절한 값을 세팅한다.
( 나 같은 경우는 락을 통해 connection을 잡고 있는 시간이 길어서 TPS가 나오지 않았던 것이여서 이쪽 문제는 아니었던걸로 결론 내리고 다른 방법을 모색했다.)
위의 접근 방식은 thread per request 모델일 때 유의미할 것으로 생각된다. ( Spring MVC 일 때), webflux에서는 또 다른 고려할 점이 있을것으로 생각되낟.
Referecne
