Elastic Search 기본개념
Elastic Search 란?
- 루씬 기반의 오픈소스 검색 엔진
- Json 기반의 문서를 저장하고 검색할 수 있으며 분석 작업도 가능합니다.
Elasitc Search의 특징
1 준실시간 검색 시스템
- 색인된 데이터가 빠르게 검색 가능합니다.
- refresh-interval (설정에 따라) 색인이 되고 언제부터 검색이 되는지 결정 가능하게 합니다.
2 고가용성을 위한 클러스터 구성
- 한 대 이상의 노드로 클러스터를 구성하여 높은 수준의 안정성을 달성하고 부하 분산이 가능하다.
- 여러 대의 노드로 클러스터를 구성할 경우, 한 대의 노드가 사용 불가능한 상태가 되더라도, 사용 가능한 남은 두대 에서 해당 문제를 해결할 수 있습니다 🙂
- 여러 대의 노드로 구성하게 되면, 부하가 분산 되어서 효율적인 처리가 가능합니다
3 동적 스키마 생성
- 입력될 데이터들에 대해 미리 스키마를 정의하지 않아도 동적으로 스키마 생성이 가능 합니다.
- RDB를 주로 써왔던 저에게는, 꽤나 큰 장점이라고 생각합니다.
(동적으로 처리하고 싶을 때가 꽤 있었습니다.)
- RDB를 주로 써왔던 저에게는, 꽤나 큰 장점이라고 생각합니다.
4 Rest API 기반의 인터페이스
- Rest API 기반의 인터페이스를 제공하여 사용의 진입 장벽을 낮췄다.
- 추가적인 Client 개발 없이 사용이 가능하다는 점에서 큰 장점이라고 생각합니다 🙂
(Rest API 를 기반으로 개발을 많이 하는 저에게는 엄청 반가운 소식입니다.)
- 추가적인 Client 개발 없이 사용이 가능하다는 점에서 큰 장점이라고 생각합니다 🙂
클러스터와 노드
ES에서 클러스터 와 노드
클러스터
- 여러 대의 노드 들이 각자의 역할을 바탕으로 연결되어 하나의 시스템처럼 동작하게 되어 있습니다.
- ** 어떤 노드에 어떤 요청을 해도 동일한 응답을 줍니다.
( 하지만 각 노드의 성격에 맞게 요청을 하는 것이 중요합니다)
- ** 어떤 노드에 어떤 요청을 해도 동일한 응답을 줍니다.
노드
- 클러스터를 구성하는 하나의 인스턴스 입니다
-
논리적인 서버로 구성되어 데이터를 저장하고 인덱싱 검색 기능에 관여합니다.
노드의 종류
-
노드의 종류는 다양하게 있고 각 역할이 다릅니다. 가장 많이 사용되는 노드 종류에 대해서 알아 보도록 하겠습니다.
- 마스터 노드 : 클러스터 상태 관리 및 메타데이터 관리
- 마스터 노드 & 마스터 후보 노드
- 마스터 노드 : 1대만 으로 구성
- 마스터 후보 노드 : 마스터 노드에 문제가 생겼을 때, 마스터 노드가 될 수 있는 노드
- 마스터 노드 & 마스터 후보 노드
- 데이터 노드 : 문서 색인 및 검색 요청 처리
- 코디네이팅 노드 : 검색 요청 처리
- 인제스트 노드 : 색인되는 문서의 데이터 전처리 (수정)
- 마스터 노드 : 클러스터 상태 관리 및 메타데이터 관리
-
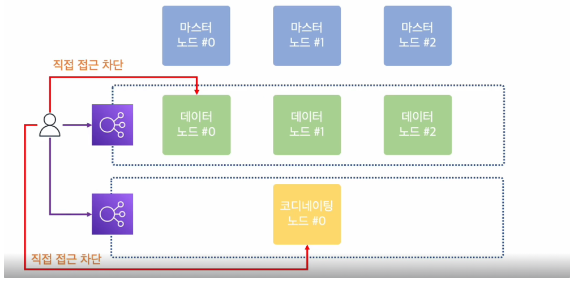
#cf) 클러스터를 구성할 때, 어떤식으로 인프라를 구성하는게 이상적일까요?
각 요청마다 해당 기능을 위한 노드에게 요청하는것이 바람직하고, 여러 대의 노드가 역할을 갖고 있을 때에는, 로드밸런서를 앞에 달고 그곳으로 요청을 보내 트래픽을 분산하는 것이 좋은 방법이라고 할 수 있겠습니다. ( 아래의 그림 예시 참조)
인덱스와 샤드
인덱스란?
문서가 저장 되는 논리적인 공간입니다.
( 문서가 저장하기 위해서는 반드시 인덱스가 존재해야 합니다 🙂 )
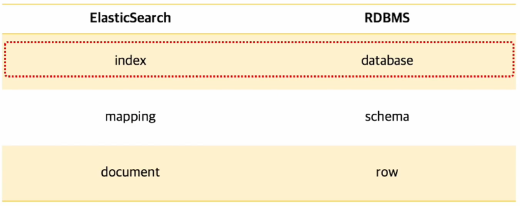
ElasticSearch 에서 인덱스를 이해하기 위해 RDBMS와 비교해보도록 하겠습니다.
( RDB를 많이 사용해보셨다면, 이해하는게 도움이 될 거 같습니다.)
인덱스 설계 기본지식
-
인덱스를 설계 하는것이 ElasticSearch를 사용하기 위해 고려해야 하는 첫 단계 입니다.
- 왜? 인덱스 설계에 따라 문서의 구조 와 검색쿼리 가 달라지기 때문입니다
-
인덱스를 설계할 때, 하나의 인덱스를 넣어서 사용할 때와 여러 개의 인덱스를 나눌 떄의 장단점을 알아보겠습니다.
-
하나의 인덱스를 사용할 때,
- 장점 : 관리해야 할 인덱스 수가 적어 관리 리소스가 적게 발생합니다.
- 단점 : 쿼리와 문서의 구조가 복잡해질 수 있습니다.
-
여러 개의 인덱스로 나눌 떄,
- 장점: 각각의 경우 최적화된 쿼리와 문서 구조를 사용할 수 있다.
- 단점: 관리해야할 인덱스 수가 많아 관리 리소스가 발생할 수 있다.
#cf) 개인생각
(개인적인 생각으로는, 엘라스틱 서치를 쓰는 이유로 방대한 데이터 내에서 원하는 것을 빠르게 검색 할 수 있다는 것인데.. 관리 리소스의 문제로 하나의 인덱스를 사용한다는 것은 주객전도 된 선택이 아닐까 생각합니다. (이 부분은 좀 더 개념 공부와 실제 테스트를 통해 알아볼 수 있을거 같네요..) )
#cf) 강의자의 조언
하나의 인덱스로 단순하게 시작한 후, 확장해서 사용 패턴에 따라 인덱스를 별도로 운영하는 것을 추천하였습니다.
샤드란?
- 인덱스에 색인되는 문서가 저장되는 공간입니다.
- 하나의 인덱스는 반드시 하나 이상의 샤드를 가집니다. 샤드의 종류
- 프라이머리 샤드 :
- 문서가 저장되는 원본 샤드, 색인과 검색 성능에 모두 영향을 줍니다.
- 문서가 분석되어서, 프라이머리에 저장되고 그 후, 레플리카 샤드에 저장되는데 이 전체 과정을 색인과정 이라고 합니다.
- 문서가 저장되는 원본 샤드, 색인과 검색 성능에 모두 영향을 줍니다.
- 레플리카 샤드 :
- 프라이머리 샤드의 복제 샤드로 검색 성능에 영향을 주고, 프라이머리 샤드에 문제가 생긴다며, 레플리카 샤드가 프라이머리 샤드로 승격하게 됩니다.
- 프라이머리 샤드 :
샤드의 라우팅
- 문서가 샤드에 저장되는 방법을 의미합니다.
- 예시를 들어 설명해보자면, 총 3개의 샤드(각각 0,1,2번 샤드라고 칭하겠습니다.)가 존재하고, A,B,C,D를 저장한다고 해보겠습니다.
- 그렇다면 0번 샤드에 A 1번 샤드에 B 2번 샤드에 C 다시 0번 샤드에 D가 저장될 것입니다.
여기서 만약 샤드가 1개가 동적으로 추가된다면, 라우팅 룰이 깨지게 되기 때문에 인덱스의 primary shard의 개수는 index 생성 시에만 설정이 가능하고 변경이 불가능 합니다 🙂
(primary shard의 기본 값 7버전 부터 1이 되었 습니다. → 성능이 잘 안나올 수 있습니다. 사용자가 변경해야 합니다 )
맵핑
맵핑이란?
- 문서의 구조를 나타내는 정보 입니다.
- ElasticSearch는 (스키마리스)가 아니라 미리 정의하지 않아도 될 뿐입니다!
맵핑의 종류
- 동적 맵핑
- 처음 색인되는 문서를 바탕으로 맵핑 정보를 ES가 동적으로 생성합니다.
- 동적으로 생성된 후에 추가되는 문서의 타입이 안맞을 경우 파싱이 불가능 합니다.
- 처음 색인되는 문서를 바탕으로 맵핑 정보를 ES가 동적으로 생성합니다.
- 정적 맵핑
- 문서의 맵핑 정보를 미리 정의 합니다.
- 문서의 필드들이 가지는 값에 따라 타입을 지정해줄 필요가 있을 때 사용합니다 🙂
- 일부만 정적 맵핑하고, 나머지는 동적 맵핑이 되게끔 할 수도 있습니다
- 불필요한 색인이 발생하지 않게 하기 위해 사용할 수 있습니다.
- 문서의 맵핑 정보를 미리 정의 합니다.
Reference
