동시성이란
동시성이란 애플리케이션이 둘 이상의 작업을 동시에 진행 중임을 의미한다. 보통의 동시성을 설명할 때 주로 CPU를 예로 들어 설명한다.
실제 우리의 컴퓨터는 사용자의 입장에서 멈춤없이 동시에 여러 프로그램이 실행되는 것처럼 보이지만, 내부의 CPU는 빠르게 여러 프로그램들을 돌아가며 태스크를 수행한다.
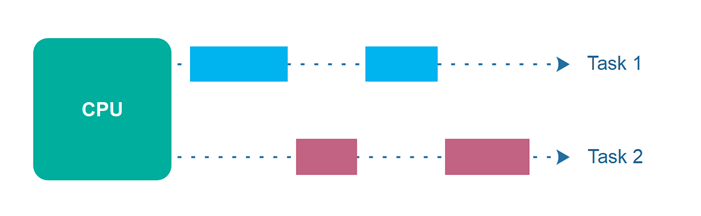
동시성이란 여러 작업을 동시에 실행하는 것을 의미하지만 반드시 동일한 시간에 실행될 필요는 없다. 즉 CPU의 코어가 1개일 경우 한 작업을 먼저 실행하고 다음 작업을 실행하거나, 한 작업과 다른 작업을 번갈아 가며 실행하는 등의 방식으로 실행된다.
이런 현상은 우리의 애플리케이션 전반에서도 일어나는 일반적인 현상이 될 수 있다.
사용자가 CPU의 빠른 태스크 작업을 눈치재치 못하는 것처럼, 많은 사용자의 요청에 대해 우리의 Java 혹은 DB, 애플리케이션 또한 마찬가지로 많은 요청들이 동시에 발생한다는 착각을 할 수 있다.
이러한 동시성은 멀티 스레드 프로그래밍이 가능한 Java, 데이터베이스의 정합성, 혹은 선축순 예약시스템, 재고 시스템 등의 애플리케이션 서비스에서 고려해야할 대상이다.
Java의 동시성 문제
Java는 멀티 스레드 프로그래밍이 가능한 언어이다. JVM은 보통 어떤 서버 상에서 실행되고 있는 프로세스를 말한다. 이러한 JVM은 최소 한 개(main 스레드) 이상 여러 스레드를 가질 수 있다.
그렇다면 많은 스레드가 공유한 자원에 동시에 접근하게 되면 어떤 문제가 발생할 수 있을까?
public class Main {
public static void main(String[] args) {
Counter counter = new Counter();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
counter.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
counter.increment();
}
});
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Final Counter Value: " + counter.getCount());
}
public static class Counter {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
}위 코드만 간단하게 본다면, 정상적으로 동작했을 경우 count의 수는 20000이 되어야 한다.
실제 코드를 실행하고 결과를 확인하면 아래와 같다.
Final Counter Value: 16950매 실행마다 다른 결과값을 받아 볼 수 있다. 그 이유는 Java 특성인 멀티 스레드 프로그래밍에 있다. 두 스레드가 하나의 자원에 동시에 접근하며, 동기화 되지 않은 데이터의 결과이다.
Java의 동시성 해결과 동기화
이러한 멀티 스레드 환경에서의 동시성 문제를 해결하기 위해 Java는 객체에 대해 thread-safe 할 수 있게 스레드 간 동기화를 시키는 방법을 사용한다.
Java에서 모든 Class의 최상위 클래스는 Object Class이다. 모든 Java class 들은 직접 또는 간접적으로 Object Class를 상속 받고 있다.
이러한 Object Class 내부를 보면 아래와 같은 메서드들을 확인할 수 있다.
public final native void notify();
public final native void notifyAll();
public final void wait();
public final native void wait(long timeoutMillis);
public final void wait(long timeoutMillis, int nanos)각각의 메서드를 간단하게 설명하면 wait() 메서드를 호출하면 현재 락을 가지고 있던 스레드는 해제하고, 스레드는 다시 스레드 스케줄링에 의해 재사용하게 된다.
notify(), notifyAll() 메서드는 둘 다 wait()으로 잠든 메서드를 깨운다. 둘의 차이는 잠든 스레드 하나만 깨우냐, 모두 깨우냐의 차이이다. notify() 의 경우 한 객체에 대해서 기다리는 스레드가 있다면, 그 중 하나의 스레드가 활성화 된다.
세 메서드가 가지는 공통적인 특징은 호출하는 스레드가 반드시 고유 락을 갖고 있어야 한다는 것이다. 만일 고유한 락 없이 위 메서드들을 실행하게 되면 IllegalMonitorStateException 이 발생하게 된다.
그렇다면 위 메서드들의 공통적인 특징인 고유 락을 가지고 있어야 한다는게 무엇일까?
Lock
Java에서 말하는 고유한 락(lock)은 공유 리소스에 대한 엑세스를 조정하고 여러 스레드가 동시에 엑세스하지 못하도록 코드의 중요한 부분을 보호하는데 사용된다.
이러한 메커니즘은 한 번에 하나의 스레드만 동기화된 블록 혹은 메서드에 엑세스할 수 있도록 하여 데이터 손상과 경합을 방지한다. Java는 이러한 동기화 달성을 위해 여러 메커니즘을 제공한다.
java 8 부터 낙관적인 잠금 메커니즘을 제공하는 StampedLock 클래스가 추가되었다.
아래는 스레드간의 동기화를 위한 Lock의 방식이다.
synchronized Blocks and Methods + Intrinsic Locks (Monitors)
Java는 동기화를 구현하기 위해 내재적 잠금(모니터)를 사용한다. 모든 Java 객체에는 연결된 내재적 잠금이 있으며, 동기화된 블록/메서드는 이 잠금을 획득하고 해제한다.
스레드가 동기화된 블록에 들어가면 잠금을 획득하고, 동일한 블록에 들어가려는 다른 스레드는 잠금이 해제될 때까지 차단된다. 이런 내재적 잠금은 내장된 효율적인 동기화 메커티즘을 제공한다.
java는 동기화된 블록과 메서드 정의를 위해 키워드를 제공하며, 이는 우리가 많이 알고 있는 synchronized 키워드이다. 해당 키워드를 통해 한 번에 하나의 스레드에서만 해당 메서드나 블록을 사용할 수 있다.
public static class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}
}위 코드의 실행결과는 몇 번을 실행해도 동일하게 20000이 출력된다. 그 이유는 synchronized 키워드로 인해 스레드간 데이터의 충돌을 방지해주기 때문이다.
여기에 위에서 설명한 Object Class의 wait(), notify() 등을 적절히 사용해 동기화기능을 더 똑똑하게 사용할 수 있다.
ReentrantLock
ReentrantLock은 보다 유연하고 명시적인 잠금 관리 방법을 제공하는 java.util.concurrent.locks 패키지의 클래스이다.
위에서 설명한 내재적 잠금과 달리 ReentrantLock은 시간 제한 잠금, 잠금 중단 및 공정성 정책과 같은 고급 기능을 사용할 수 있다.
public static class Counter {
private final ReentrantLock lock = new ReentrantLock();
private int count = 0;
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
return count;
}
}위 코드의 실행 결과도 동일하게 count는 20000을 반환한다. 실제 Synchronized의 경우 키워드를 통해 사용할 수 있다는 간편함이 있으며, 반대로 특별한 상황에서는 ReentrantLock를 통해 명시적인 동기화를 제공할 수 있다. 또한 동기화된 블록을 잠그거나 해제할 때 더 유연하게 선택할 수 있다.
Database의 동시성 문제
Java와 마찬가지로 동시성 문제는 모든 데이터베아스 관리 시스템을 운영하면서 직면하게 되는 일반적인 문제이다. 이러한 동시성 문제는 동일한 데이터베이스에서 여러 Transaction이 제한 없이 실행될 때 발생한다.
데이터베이스에는 이러한 동시성으로 인해 발생할 수 있는 문제 몇 가지가 있다.
- Lost Update Problem
- Incorrect Summary Problem
- Dirty Read Problem
- Unrepeatable Read Problem
- Phantom Read Problem
이러한 문제들로 인해 데이터의 무결성이 깨지고, 의도하지 않은 결과가 반환된다. 특히나 쇼핑몰 같은 경우는 상품 혹은 은행시스템에 있어 큰 문제가 발생할 수 있다.
Java의 메서드 동기화(synchronized 등)을 이용하여 데이터 충돌을 방지한다고 생각해 볼 수 있겠지만, 애플리케이션 운영의 입장에서 몇 가지 단점이 존재한다.
기본적으로 성능 저하가 있다. 모든 스레드가 해당 메서드를 점유하고 있는 스레드의 작업이 끝날때 까지 기다려야 하기 때문이며, 여러 스레드가 서로를 기다리는 경우 교착상태 까지 고려를 해봐야한다.
또한 보통의 애플리케이션의 경우 여러 인스턴스와 하나의 데이터베이스 서버로 구성되어 있는 경우가 많은데 이때 서로 다른 인스턴스 서버에서 실행되는 메서드의 데이터의 경우 데이터베이스의 입장에선 동시성이 발생하기 충분한 조건이다.
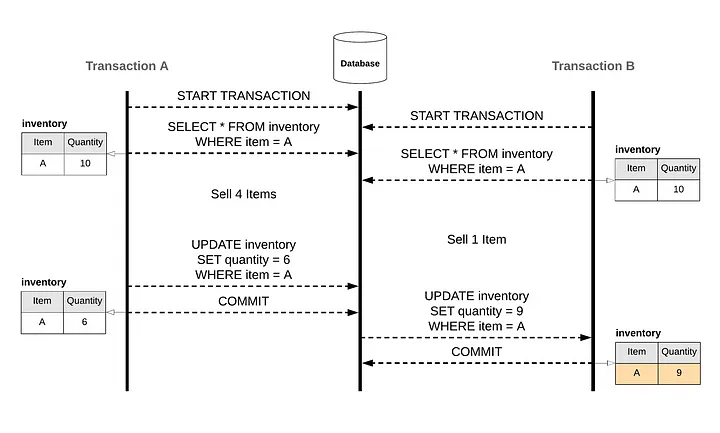
Database의 동시성 해결
우선 우리가 흔히 알고있는 RDB는 모두 Transaction Database 라는 한 가지 공통점을 공유하고 있다. 즉, 모두 트랜잭션에 의존한다.
트랜잭션은 일반적으로 여러 개의 낮은 수준의 단계를 포함하는 논리적 단위를 의미한다.
데이터를 생성, 업데이트 또는 검색하는데 사용된다. 이러한 일련의 작업은 데이터베이스의 데이터가 항상 안정적이고 일관된 상태로 유지하도록 보장한다.
이는 데이터베이스는 유효하며, 일관적인 데이터를 제공해야 하는 것을 의미하며, 동시성의 상황에 있어서도 이를 유지하기 위해 여러 방법을 제공한다.
Lock-Based Protocol
데이터베이스에서 잠금 기반 프로토콜은 필요한 잠금을 얻을 때까지 트랜잭션이 데이터를 읽거나 쓸 수 없도록 하는 메커니즘으로 정의할 수 있다.
이는 특정 트랜잭션을 특정 사용자에게 잠궈 동시성 문제를 제거하는데 도움이 된다. 잠금은 특정 데이터 항목에 대해 실행할 수 있는 작업을 나타내는 변수이다.
데이터베이스의 잠금 기반 프로토콜에는 데이터 항목을 잠그고 해제하는 두 가지 모드가 존재한다.
그리고 이러한 두 가지 모드를 통한 네 가지 잠금 기반 프로토콜이 존재한다.
Mode
- Shared Lock
흔히 lock-S() 로 표시되는 공유 잠금은 관련된 정보에 대한 읽기 전용 액세스를 제공하는 잠금으로 정의된다. 여러 사용자가 읽을 수는 있지만, 정보나 데이터 항목을 읽는 사용자는 해당 정보에 대한 편집 혹은 변경 권한이 없다.
공유 잠금은 read lock 이라고도 읽히며, 데이터 객체를 읽는 데만 사용되며, 이러한 특징으로 읽기 무결성은 공유 잠김을 통해 지원된다. - Exclusive Lock
배타적 잠금의 경우 읽기와 쓰기 모두에 대한 엑세스를 제공하는 잠금으로 정의된다. 한 번에 하나의 트랜잭션만 배타적 잠금을 회득할 수 있으며, 쓰기 연산을 완료한 후 데이터 항목의 잠금을 해제할 수 있다. 그 동안 다른 트랜잭션은 해당 데이터 항목을 읽거나 쓸 수 없다.
Types
- simplistic Lock Protocol
트랜잭션 중 데이터를 보호하는 가장 기본적인 방법으로 정의된다. - Pre-Claiming Lock Protocol
트랜잭션을 시작하기 전에 데이터베이스 관리 시스템에 모든 데이터 항목에 대한 모든 잠금을 요청한다. - Two-phase Locking Protocol
잠금을 Grwoing Phase 와 Shrinking Phase 2단계로 나누어 관리한다. - Strict Two-Phase Locking Protocol
엄격한 2단계 잠금 프로토콜이라는 개념으로 계단식 롤백을 방지한다.
위와 같은 protocol들은 Starvation이 발생할 수 있는 여지가 있다는 문제점이 있다.
잠긴 항목에 대한 대기 체계가 올바르게 제어되지 않거나, 하나의 트랜잭션면 계속해서 배제되는 경우가 이에 해당한다. 또한 락을 획득하기 위해 서로 리소스를 해제하기를 기다리면서 발생하는 deadLock도 문제가 된다.
Pessimistic & Optimistic Concurrency Control
데이터베이스는 위와 같은 data의 Lock을 통해 동시성을 제어하며 이를 통해 데이터베이스의 쓰기 순서를 유지하고 데이터간의 불일치를 방지할 수 있다.
데이터베이스는 이처럼 동시에 두 명의 사용자가 데이터 필드를 업데이트 할 때 일관성을 유지하기 위해 비관적 락(Pessimistic)과 낙관적 락(Optimistic)을 통해 동시성을 처리할 수 있다.
Pessimistic Concurrency Control
비관적 동시성 제어는 기본적으로 트랜잭션 간의 충돌이 자주 발생할 수 있다고 가정하는 방식이다. 이를 위해 사용자가 업데이트를 시작하면 데이터 레코드를 차단하는 방식을 통해 다른 사용자는 잠금이 해제될 때까지 해당 데이터를 업데이트할 수 없게 하는 방법을 사용한다.
비관적 동시성 제어 방식에는 세 가지의 잠금 모드가 사용되며, 이는 각각 Shared Lock, Exclusive Lock, Update Lock 사용자는 적용된 잠금에 따라 잠긴 레코드를 읽을 수 있다.
JPA 에서는 이러한 비관적 동시성 제어를 어노테이션을 통해 지원 하며, 아래와 같이 사용할 수 있다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithPessimisticLock(Long id);이때 LockModeType에 따라 공유락 혹은 베타락을 설정할 수 있으며, 위의 코드상에서는 현재 WRITE 즉 Exclusive Lock으로 읽기와 쓰기 모두에 Lock을 걸게 되어있다.
이런 비관적 동시성 제어의 경우 Lock을 활용하는 방식이며, 이는 Lock으로 인해 발생할 수 있는 문제점 등 몇가지 단점들이 존재한다.
- 잠금 기간이 길어질 경우 서비스의 성능 문제가 발생할 수 있다.
- DeadLock이 발생할 수 있다.
- 애플리케이션 확장성에 영향을 미친다.
- 잠금과 그에 따른 대기로 인해 높은 리소스가 소비된다.
이러한 비관적 동시성 처리 방식은 트랜잭션을 처리하기 전에 충돌을 차단하므로 나중에 트랜잭션을 롤백할 필요가 없으므로 데이터 충돌이 많은 애플리케이션에 적합하다.
Optimistic Concurrency Control
낙관적 동시성 제어는 이름에서 알 수 있듯 동시성을 처리할 때 최상의 시나리오를 기대한다.
즉, 이는 트랜잭션 간의 충돌이 드물게 발생한다고 가정하고, 데이터 접근 시점에 락을 걸지 않고 비동기화된 방식으로 진행될 수 있도록 허용한다. 이는 트랜잭션을 수행할 때 락을 걸어 차단하는 비관적 동시성 제어와는 다르다.
낙관적 동시성 제어는 사용자의 변경 사항이 데이터베이스에 커밋되기 직전에 트랜잭션 간의 충돌이 있는지 확인한다. 충돌이 있는 경우 사용자가 개입(애플리케이션 단에서)하여 트랜잭션을 수동으로 완료해야 한다.
이러한 낙관적 동시성 제어는 compare-and-set 연산을 통해 구현이 가능하다. 타임스탬프 혹은 버전 번호를 사용하여 동시성을 제어하는 것이다. 사용자가 데이터베이스에 변경 사항을 커밋하려고 할 때 두 항목을 비교하여 어떠한 레코드를 유지할지 결정하는 방식이다.
MySQL에서는 낙관적 동시성 제어를 사용할 테이블에 버전 번호 혹은 타임스탬프를 기록하기 위한 컬럼을 추가하여 구현이 가능합니다.
create table users(
user_id INT NOT NULL AUTO_INCREMENT,
user_name VARCHAR(100) NOT NULL,
version INT NOT NULL,
PRIMARY KEY ( user_id )
);처음에는 각 레코드의 version column이 1이 된다. 이후 해당 레코드에 업데이트 쿼리를 작성할 때 레코드의 버전을 변경한다. 예를 들어 업데이트 전에 버전이 1이었다면 업데이트 쿼리를 사용하여 2로 변경이 필요하다.
SELECT * from users WHERE user_id = 1;
UPDATE users SET user_name = 'Chameera', version = version + 1
WHERE user_id = 1 AND vrsion = 1;비관적 동시성 제어와 마찬가지로 JPA에서는 이러한 낙관적 동시성 제어를 어노테이션을 통해 간단하게 CAS(compare-and-set) 연산 구현이 가능하도록 지원하며, 아래와 같이 사용할 수 있다.
@Entity
public class Stock {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private Long quantity;
@Version
private Long version; //CAS 연산을 위한 version 정보
@Lock(LockModeType.OPTIMISTIC)
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithOptimisticLock(Long id);이때 persistemce provider가 Entity에서 낙관적 락의 충돌을 감지할 경우
OptimisticLockException 을 던지게되며, 이 예외로 인해 활성 트랜잭션은 롤백을 위한 롤백마크가 표시된다. 권장되는 예외처리 방법에서는 Entity를 다시 로드하거나 새로고침하여 업데이트를 재 시도하는 방법이다.
- 동시성 처리 과정:
트랜잭션 A와 트랜잭션 B가 동시에 같은 row를 읽습니다.
이 row의 현재 버전 번호는 v1이라고 가정합니다.
두 트랜잭션 모두 row의 버전 번호 v1을 가지고 있습니다. - 트랜잭션 A 커밋 시:
트랜잭션 A는 row를 수정하고 커밋하려고 시도합니다.
데이터베이스는 트랜잭션 A가 row의 현재 버전 번호 v1을 수정하려고 한다는 것을 확인합니다.
트랜잭션 A의 커밋이 성공하면, row의 버전 번호가 v2로 증가합니다. - 트랜잭션 B 커밋 시:
트랜잭션 B도 row를 수정하고 커밋하려고 시도합니다.
데이터베이스는 트랜잭션 B가 row의 버전 번호 v1을 수정하려 한다는 것을 확인합니다.
하지만, 현재 row의 버전 번호는 이미 v2로 변경되었기 때문에, 버전 번호가 일치하지 않습니다.
이 경우, 트랜잭션 B의 커밋은 실패하며, OptimisticLockException과 같은 예외가 발생합니다. - 트랜잭션 B의 재시도:
트랜잭션 B는 예외를 처리하여, 변경된 데이터를 다시 읽고, 새로운 버전 번호 v2를 가져옵니다.
필요한 수정 작업을 다시 수행하고, 버전 번호 v2로 커밋을 시도합니다.
만약 이번에도 성공적으로 커밋되면, row의 버전 번호는 v3로 증가합니다.
위와 같은 특성의 낙관적 동시성 제어의 경우 아래 와같은 장점과 단점들이 존재합니다.
장점
- 잠금이 필요하지 않아 교착 상황이 없다.
- 애플리케이션 확장을 위한 지원 제공
- 한 번에 여러 사용자에게 서비스 제공 가능
단점
- 버전 또는 타임스탬프 유지 관리 필요
- 동시성 처리 로직을 수동으로 구현해야 함
- 트랜잭션의 롤백에 대한 비용이 비쌈
이런 낙관적 동시성 제어는 충돌이 적은 애플리케이션에 적합하고 데이터 충돌이 많지 않은 경우 필요한 롤백 횟수와 롤백에 드는 비용을 줄일 수 있다.
분산 락을 통한 동시성 해결
지금까지 설명한 Java의 스레드 동기화 또는 락을 활용해서 애플리케이션을 구현한다면, 동시성의 문제는 어느정도 해결되지 않을까? 라는 생각이 들 수 있다.
우선 Java의 스레드 동기화의 경우 단일 인스턴스에선 해결이 가능한 문제처럼 보일지 모르지만, 여러 인스턴스가 실행되는 분산 환경에서는 각 인스턴스 간의 동시서을 처리하기엔 적합하지 않다.
또한 락을 활용한 데이터베이스의 동시성 해결의 경우 성능저하 혹은 DeadLock의 영향이 있으며, 낙관적 동시성 제어를 통한 방법 또한, 충돌된 트랜잭션들은 대기 없이 실패하게 되거나 별도의 재시도 구현이 필요하며 재시도 자체의 실패 등을 고려해야 하기에 이는 곧 코드의 복잡도로 이어진다. rollback 비용 또한 무시할 수 없다.
동시성에 의한 충돌이 더 많은 시스템에선 좀 더 확장성과 가용성이 높고 유연한 처리가 필요하며, 이를 위해 분산 락을 활용하는 경우가 더 많다. 또한 분산 락을 활용하고도 만약의 상황에서의 데이터 정합성이 틀어지지 않게 하기 위해 데이터베이스의 동시성 제어를 함께 활용하는 경우가 있다.
분산 락은 분산 컴퓨팅 환경에서 동시성을 향상시키는 기술이다. 클러스터의 여러 노드에 분산되어 있는 데이터베이스, 파일 또는 네트워크 리소스와 같은 공유 리소스에 대한 액세스를 규제하는데 사용된다.
이처럼 분산 잠금은 여러 노드가 동일한 리소스를 동시에 읽고 쓰는 것을 방지하기 위해 사용되는 방법으로 대규모 분산 시스템 혹은 고가용성 및 성능이 중요한 시스템에서 개별 노드들이 다른 노드가 무엇을 하고있는지 알 수 있도록 동기화하는 메커니즘을 통해 동시성 문제를 해결한다.
Redis Distributed lock
레디스는 흔히 많이들 알고있는 인 메모리 키-값 데이터 구조 스토어이다. Redis의 대표적인 특징은 바로 Single Thread를 사용하고 있다는 것이다. 이러한 단일 스레드를 사용함으로써 Redis는 CPU 소모의 최소화, Context Switching 비용의 최소화 또한 멀티스레드 애플리케이션 환경에서 스레드 동기화를 위해 필요한 잠금에 대한 오버헤드를 줄일 수 있다.
또한 인 메모리로 실행되기 때문에 지연 시간이 짧고 처리량이 높다는 장점이 있다. 이는 데이터 요청이 디스크로 이동할 필요가 없다는 것을 의미하며, 더 많은 작업 처리와 응답 시간에 대한 단축으로 이어진다.
이러한 Redis는 분산 잠금을 효과적으로 사용하기 위해 필요한 최소한의 세 가지 속성을 보장한다.
- 상호 배제로 한 클라이언트만 잠금을 보유할 수 있다.
- 교착상태가 없다.
- 내결함성. 대부분의 Redis 노드가 가동 중이면 잠김 획득이 가능하다.
Redis는 Lua Script를 하용하여 atomic한 작업 처리를 지원한다. Lua Script는 여러 가지 명령어를 조합할 수 있을 뿐 아니라, 스크립트 자체가 하나의 큰 명령어로 해석되기 때문에 스크립트가 atomic하게 처리된다는 특징이 있다.
이를통해 애플리케이션 로직의 일부를 Redis 내에서 실행할 수 있으며 Atomic 한 작업으로 Redis 데이터에 대한 복잡한 작업을 수행할 수 있다.
또한 Redis는 SETNX 명령을 통해 분산 락을 구현할 수 있으며, 해당 명령어는 SET if Not eXists로 특정 Key에 Value가 존재하지 않을 경우 값을 설정할 수 있다는 의미이다
추가로 DeadLock 방지를 위해 EX 명령어를 활용해 Lcok의 Timeout 설정 까지 가능하다. 이러한 명령어를 통해 Redis Client들은 각각 분산 락을 구현했다.
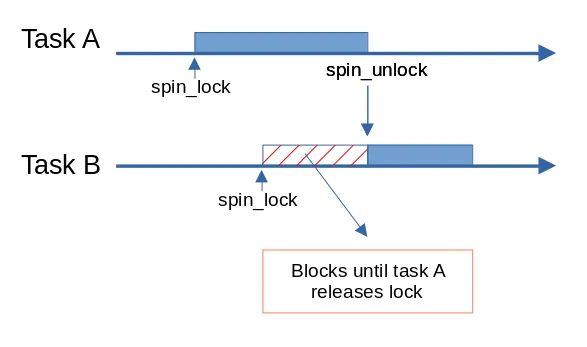
Spin Lock
흔히 우리가 이야기하는 Spin Lock 방식은 사실 운영체제에서 비롯된 이름이다. 공식적으로 Redis Client 중 Lettuce는 분산락 기능을 제공하지 않기 때문에 필요한 경우 Spin Lock 방식 등을 활용해 직접 구현해 사용하는 방식이다.
Spin Lock이란 조금만 기다리면 바로 쓸 수 있는데 굳이 Context Switching으로 부하를 줄 필요가 있는가? 라는 컨셉으로 개발된 것으로 진입이 불가능할 때 Context Switching을 하지 않고 루프를 돌며 재시도 하는 것을 의미한다.
Spin Lock은 Lock을 얻을 수 없다면, 계속해서 Lock을 확인하며 바쁘게 기다리는 busy waiting이라는 특성이 있으며, 이는 무한적으로 루프를 돌며 최대한 다른 스레드에게 CPU를 양보하지 않는다.
즉, Lock이 곧 해재되어 사용가능해질 경우 Context Switching이 줄어 CPU의 부담을 줄일 수 있다는 장점이 있는 반면, Lock이 오랫동안 유지된다면 오히려 CPU의 시간을 많이 소모할 가능성이 높다.
따라서 무한 적으로 루프를 돌기 보단 일정시간 Lock을 획득할 수 없다면 잠시 sleep 하는 방식의 Exponential Backoff(지수 백오프) 혹은 ConstantBackOff 알고리즘을 사용하는 것이 좋다.
위의 내용은 Redis에도 동일하게 작용한다. sleep을 주었다고는 하지만 정해진 시간 마다 계속해서 Redis에 요청을 보내는 것으로 작업이 오래 걸리고 요청수가 많아질 수 록 Redis에는 더 큰 부하를 가하게 된다.
그렇다고 레디스에 부담을 덜 기위해 sleep 시간을 크게 늘린다면 Lock을 획득하기 위해 대기하는 시간이 길어져 오히려 성능적으로 비효율적인 상황이 생기게 된다.
Spin Lock의 경우 예상 대기 시간이 짧은 경우 유용하며, 이를 위해 sleep에 대한 적절한 시간 설정 또한 중요하다.
pub-sub
Redis의 대표적인 Lock 방식중 Pub/Sub Lock은 대표적으로 Redisson Client가 제공하고 있다.
pub/sub은 게시와 구독이라는 의미를 가지고 있으며 이는 실제 서버리스 및 마이크로서비스 아키텍처에서 비동기적으로 통신하기 위한 소프트웨어 메시징 패턴을 말한다.
이런 Pub/Sub 방식은 수신자가 발행자의 새 메시지를 반복적으로 폴링할 필요가 없다는 효율적인 측면이 있다.
Redisson Client는 이처럼 Lock을 pub/sub 채널을 사용하여 제공하며, 잠금을 획득하기 위해 대기 중인 모든 Redisson 인스턴스의 다른 스레드에 알림을 보내는 방식을 사용한다.
또한 잠금을 획득한 Redisson 인스턴스가 충돌하면 해당 잠금은 획득된 상태에서 영원히 멈출 수 있기에 이를 방지하기 위해 Redisson은 잠금 감시를 유지하여 잠금 보유자인 Redisson 인스턴스가 살아있는 동안 잠금 만료를 연장한다. 기본적으로 잠금 감시 시간 제한은 30초이며 변경이 가능하다.
이러한 Pub/Sub 방식은 락이 해제될 때마다 subscribe 중인 클라이언트들에게 락 획득을 시도해도 된다는 알림을 보내기 때문에 Spin Lock 과는 다르게 지속된 요청으로 인한 Redis의 부하가 발생하지 않는다는 장점이 있다. 또한 사용자가 별도의 Retry 로직을 작성하지 않아도 되는 편리함도 있다.

정리
java 애플리케이션을 개발하면서 동시성이라는 문제를 만났을 때 해결 방법은
- 자바 코드로 인한 단일 스레드 유지 -> 데드락 일어날 수도 있음, 분산 환경에서 사용 불가능
- DB 단에서 락을 검 -> 비관적 락은 데드락 유발 가능성이나 리소스 낭비가 있음, 낙관적 락은 트랜잭션 실패 시 재시도 구현이 필요하므로 코드의 복잡성이 증가함
=> 분산 락을 통해서 확장성과 가용성이 높고 유연한 처리가 가능하게 함
