✍Machine Learning 구성 요소들
대학교 수업에서 들은 ML course의 정리
Machine learning이란?
A computer program is said to learn from experience E
with respect to some class of tasks T
and performance at tasks in T, as measured by P,
improves with experience E.
-Tom Michell
직역하자면 컴퓨터 프로그램은 성능 지표와 어떤 분류의 일을 고려한 경험을 토대로 학습하고, 그 경험을 토대로 성능 개선을 위한 학습을 한다 (맞나?)라고 표현할 수 있을 것 같다.
그럼 data란 무엇인가?
Raw Data는 무엇이든 될 수 있다?!
그러나 이러한 것들을 포함해야 한다
- ID (또는 key) 값
- 각 ID는 다양한 변수를 갖고 있어야한다
- 특성이 있는 관찰된 변수들
- ID에 의해 변하는 변수들
변화 ∩ 관심사 ∩ 특성
ML의 알고리즘
모델링의 타입
머신러닝의 모델은 4가지 정도의 타입이 있다. 그 중 지도 학습과 비지도 학습이 큰 비중을 차지한다고 한다. 그 외 2가지는 이상치 탐지와 강화학습이 있다.
지도학습 (supervised learning)
지도학습은 예측하는 output 변수(target y)가 존재하여, input과 output의 관계를 찾아 예측모델을 만든다(?)
지도학습은
- 예측 (prediction)
- 분류 (classification)
- 회귀 (regression)
로 나뉜다.
분류 (classification)
분류는 타겟 y가 가질 수 있는 값이 유한한 경우 분류라고 한다.
예를 들면 사람이라는 시각적 데이터 (raw data)를 남/녀 성별로 구분하려고 한다고 가정한다. 이때 머리카락의 길이와 키를 카테고리로 정하여 그래프로 나타낸 후, 남 녀의 구분을 위해 선을 찾는 과정을 분류라고 할 수 있다. 이것 외 손글시 인식이나 번호판 인식 등 여러가지 예시가 있다.
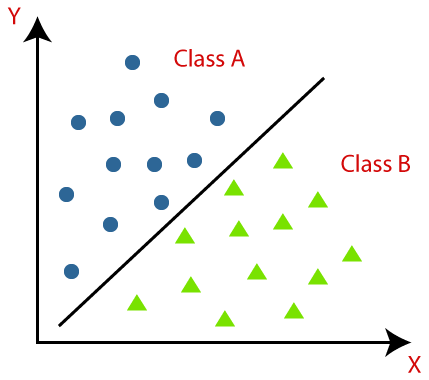
분류를 사용하는 기법으로는 나이브 베이즈 분류(Naive Bayes classifier), Neural network, 서포트 벡터 머신, KNN, 의사 결정 트리 등이 있다.
회귀 (Regression)
회귀는 타겟 y가 가질 수 있는 값이 실수인 경우 회귀라고 한다. 특징량을 바탕으로 구분하는 구분선을 찾아내는 방법을 수행한다.
예를 들어 마트의 고객들의 연봉 데이터를 갖고 있고, 이들이 마트에서 쓰는 돈의 양을 연속적인 y로 나타낸다고 하자. 이때, 연봉에 따른 소비 금액을 선으로 나타내기 위해 회귀 분석을 사용한다고 한다.
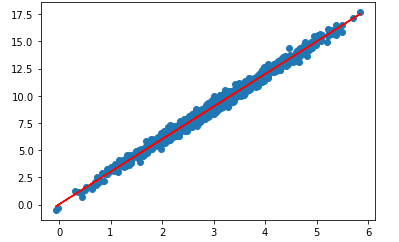
회귀를 사용하는 기법으로는 선형 회귀, multivariate linear regression, Ridge와 Lasso regression, Neural network regression, Support vector regression, Decision tree regression 등이 있다.
비지도 학습 (unsupervised learning)
비지도 학습은 output (target y)가 존재하지 않고 input 만을 이용하여 예측 모델을 만드는 것이다. input 데이터를 군집화/분포 측정을 통해 input을 그룹으로 나누는데 이것을 clustering 기법이라고 한다.

이상치 탐지 (Novelty detection)
이상치 탐지는 정상에서 벗어난 데이터를 탐지하는 것을 말한다. 데이터 중, 이상치 데이터 수집이 어려운 경우가 존재한다. 이러한 데이터를 탐지하기 위해 정상치 영역을 학습시킨다. 이후 학습된 영역에서 벗어난 데이터를 이상치 데이터로 판단한다.
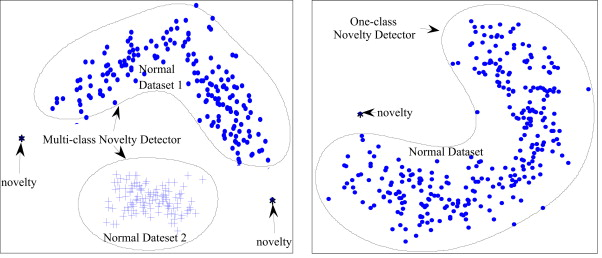
강화 학습 (Reinforcement learning)
강화 학습은 주로 게임에서 활용된다. Agent(시스템)은 status(상태)에 따라 Action(동작)을 취하면 실시간으로 reward가 주어진다. 이렇게 실시간으로 reward를 여러가지 action에 따라 주어져야 함으로 가상환경에서 적합하다. 대표적인 예시로 AlphaGo가 있겠다.
차원 축소 (Demension Reduction)
차원 축소는 변수의 수가 많을 때 주로 사용한다고 한다. 변수가 많을 수록 불필요한 변수들에 의해 모델에 악영향을 미친다. 따라서 이러한 악영향을 줄이기 위해 적절한 차원 축소가 필요하다.
그 외...
그 외 High capacity 모델인 RNN, CNN이 있다. 자세한건 추후에 다룰 것 같다.
실생활에선..?
실생활 (real world)에서 적용되는 분야는 다양하다고 한다. 수업에서 제시한 것은 이미지/비디오 인식, 자연어 처리, 언변 인식, 산업 분야의 예측 보수(?), 의료분야, 공공분야 등 다양하다.
끝 마치며...
ML 수업의 첫주차 내용을 두번을 나누어 정리해봤다. 아직 본격적인 내용을 접하지 않아 뭔가 많이 부족해 보이지만, 이제 시작이니 참으로 기대가 된다. 😁
