적대적 예제란?
의도적으로 딥러닝 시스템을 속이기 위해 교묘하게 제작된 결과물
적대적 공격을 고려해야 하는 이유
- 조작된 데이터를 활용하여 공격자가 큰 이득을 편취할 수 있다.
ex)시스템의 오분류를 이용해 높은 보험금을 가져가는 것 - 자율주행에서의 무단횡단 등 불확실한 상황에 대처할 수 있다. 적대적 공격을 방어할 수 있다면 worst-case 에 대한 보안성을 입증하는 것이고 이는 다른 돌발적인 상황도 어느정도 방어가 가능하다는 증거가 된다.
적대적 공격을 방어하려면 적대적 예제가 어떻게 생기는지 알아야 한다. 방어 방법에 대해서는 다음번에 포스팅 하기로 하고 오늘은 적대적 예제 생성 방법에 대해 알아보자.
사용된 공격 방법: FGSM (Fast Gradient Sign Attack)
FGSM 공격 방식: 입력 데이터에서 계산된 손실 변화도를 조정하여 손실이 최대가 되게 함
라이브러리
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt공격받는 모델 생성
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
])),
batch_size=1, shuffle=True)
print("CUDA Available: ",torch.cuda.is_available())
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")
model = Net().to(device)
model.load_state_dict(torch.load(pretrained_model, map_location='cpu'))
model.eval()FGSM 공격 정의
def fgsm_attack(image, epsilon, data_grad):
sign_data_grad = data_grad.sign()
perturbed_image = image + epsilon*sign_data_grad
perturbed_image = torch.clamp(perturbed_image, 0, 1)
return perturbed_image테스팅 함수 정의
전체 테스트를 수행하고 최종 정확도를 보고함
엡실론(ϵ) 값에 따라 모델의 정확도 결정 (엡실론이 증가할수록 정확도 감소)
성공적으로 얻은 적대적 예제를 저장하여 시각화
def test( model, device, test_loader, epsilon ):
correct = 0
adv_examples = []
for data, target in test_loader:
data, target = data.to(device), target.to(device)
data.requires_grad = True
output = model(data)
init_pred = output.max(1, keepdim=True)[1]
if init_pred.item() != target.item():
continue
loss = F.nll_loss(output, target)
model.zero_grad()
loss.backward()
data_grad = data.grad.data
perturbed_data = fgsm_attack(data, epsilon, data_grad)
output = model(perturbed_data)
final_pred = output.max(1, keepdim=True)[1]
if final_pred.item() == target.item():
correct += 1
if (epsilon == 0) and (len(adv_examples) < 5):
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
else:
if len(adv_examples) < 5:
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
final_acc = correct/float(len(test_loader))
print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc))
return final_acc, adv_examples공격 실행
accuracies = []
examples = []
for eps in epsilons:
acc, ex = test(model, device, test_loader, eps)
accuracies.append(acc)
examples.append(ex)정확도와 엡실론간의 반비례 관계 확인
plt.figure(figsize=(5,5))
plt.plot(epsilons, accuracies, "*-")
plt.yticks(np.arange(0, 1.1, step=0.1))
plt.xticks(np.arange(0, .35, step=0.05))
plt.title("Accuracy vs Epsilon")
plt.xlabel("Epsilon")
plt.ylabel("Accuracy")
plt.show()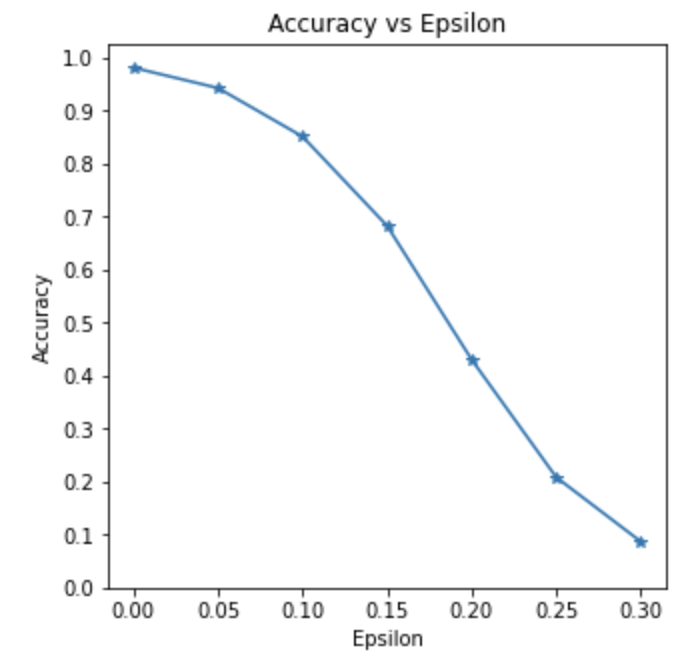
얻어낸 적대적 예제 시각화
cnt = 0
plt.figure(figsize=(8,10))
for i in range(len(epsilons)):
for j in range(len(examples[i])):
cnt += 1
plt.subplot(len(epsilons),len(examples[0]),cnt)
plt.xticks([], [])
plt.yticks([], [])
if j == 0:
plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)
orig,adv,ex = examples[i][j]
plt.title("{} -> {}".format(orig, adv))
plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()엡실론이 높아질수록 이미지가 망가지는 것을 확인할 수 있다.
적대적 공격은 사람이 보기에는 정상이지만 딥러닝 시스템에는 오류를 일으키도록 noise를 발생시키는 것이 목표다. 따라서 엡실론을 0.3까지 높혀서 육안으로 구별되게 하기 보다는 0.05, 0.1 정도로 기계 학습에만 오류를 일으키는 수치를 사용하는 것이 적합하다.

자료 출처: https://pytorch.org/tutorials/beginner/fgsm_tutorial.html
