Hikari cp
Hikari란
- Hikari는 connection pooling을 제공하는 JDBC DataSource의 구현체입니다.
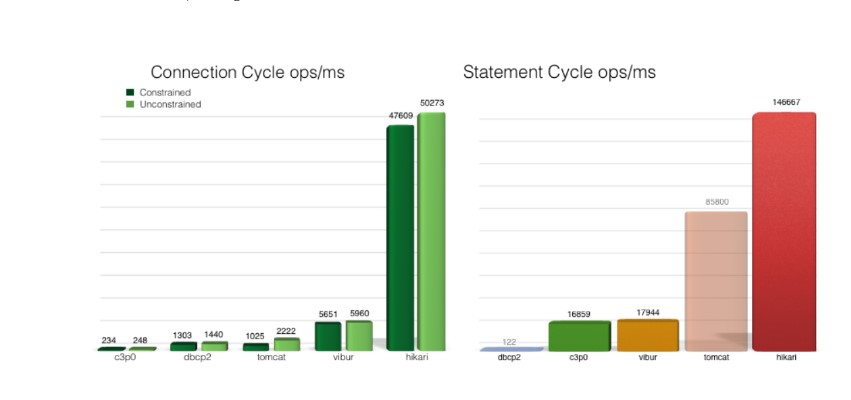
- 이 프레임워크가 다른 connection pooling 보다 가장 빠른 이유는 몇몇 바이드코드 레벨의 구현이 있으며, 마이크로 최적화, ArrayList 사용 대신 FastList 직접 구현으로 처음부터 끝까지 모든 것을 스캔하는 과정 생략 등이 있습니다.
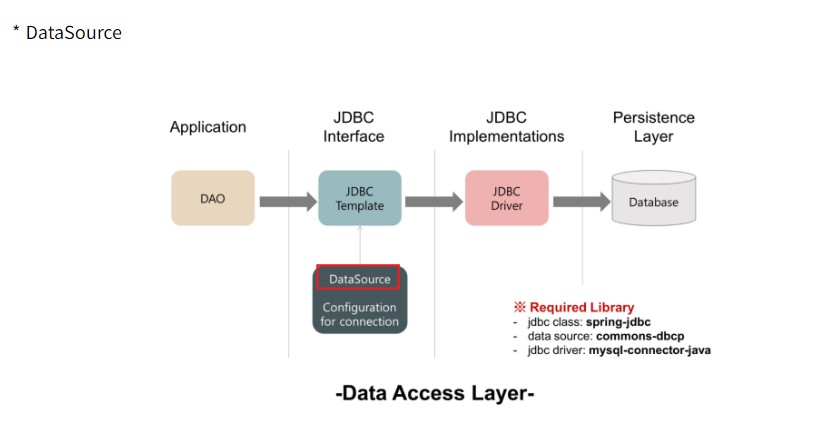
- 데이터소스(DataSource)는 물리적인 데이터베이스에 연결하기 위한 팩토리입니다. 데이터소스는 데이터베이스에 연결하기 위해 이름/비밀번호, URL을 사용합니다. 보통 데이터소스는 커넥션을 얻기 위해 사용됩니다. JDBC API가 제공하는 데이터소스 객체를 사용하면, DriverManager를 사용하지 않고 DB연결을 할 수 있습니다.
- 자바에서 데이터소스는 javax.sql.DataSource 인터페이스를 구현합니다. 이 데이터소스의 구현체는 JNDI 서비스에 등록되고, JNDI 이름을 사용하여 식별됩니다.
- 데이터소스를 통해 다음을 얻을 수 있습니다. 1. 커넥션 객체 2. 커넥션 풀에서 사용가능한 커넥션 3. 분산 트랜잭션과 커넥션 풀에서 사용가능한 커넥션
자바 설정으로 기본 세팅하기
@Configuration
public class JpaConfig {
@Bean
public DataSource getDataSource() {
public DataSource dataSource() {
DataSource ds = new DataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost/spring5fs?characterEncoding=utf8");
ds.setUsername("id"); // id 설정
ds.setPassword("password"); // password 설정
ds.setInitialSize(2);
ds.setMaxActive(10);
return ds;
}
}
//DriverClassName, Url, Username, Password 등 물리적 DB와 연결을 위한 기본 정보를 설정합니다.
//미리 생성할 커넥션 개수를 initialSize로 지정합니다.
//maxActive는 활성 상태가 가능한 최대 커넥션 개수를 지정합니다.
//현재 활성 상태의 커넥션이 최대치라면 maxWait시간 만큼 대기하고 대기 시간 내에 풀에 반환된 커넥션이 없으면 Exception이 발생합니다.Connection Pool
- 커넥션풀(connection pool)이란, 미래의 데이터베이스에 요청이 올 때 다시 사용되는 데이터베이스 커넥션의 캐시입니다. 커넥션풀들은 전체적인 리소스 낭비를 줄일 수 있습니다.
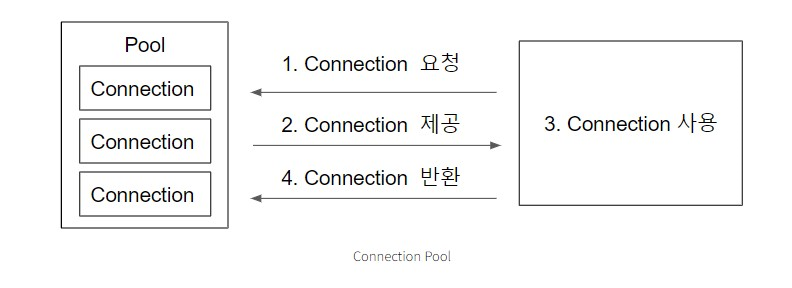
커넥션 풀 관리가 중요한 이유는, 커넥션을 맺는 과정이 상당히 복잡하고 컴퓨터 자원을 많이 사용하기 때문입니다. Hikari는 미리 connection을 pool에 담아두고, 요청이 들어오면 Thread가 pool을 요청하고, Hikari는 Connection을 제공합니다.
Hikari 사용하기
(https://velog.io/@house1021/JUnit 참조)
풀링 데이터 소스를 생성하기 위해 스프링 부트는 유효한 드라이버 클래스가 사용 가능한지 확인합니다.
spring.datasource.driver-class-name 속성이 설정되면, 설정된 드라이버 클래스가 로드됩니다.
- 자동 설정은 처음에 HikariCP을 확인하고 설정합니다.
- 사용하지 못한다면, Tomcat Pooling을 설정합니다
- 둘 다 사용이 안된다면, Commons DBCP2를 확인합니다.

.