1. 스핀락의 한계와 새로운 목표 (Objectives)
-
시간 낭비의 주범: 앞선 챕터에서 세마포어를 구현할 때 사용한 스핀락(while(s == 0))은 자원을 얻지 못하면 자신의 할당 시간(Time Slice, 예: 1ms)이 끝날 때까지 CPU를 붙잡고 아무 의미 없는 대기만 하며 시간을 낭비했습니다.
-
해결책 (협력과 블로킹): 스레드가 CPU가 당장 필요 없거나 자원을 기다려야 할 때, 다른 스레드에게 CPU를 자발적으로 양보하는 OS_Suspend 기능과 대기열 구조(FIFO 큐), 스레드 수면(Sleeping) 기능을 도입하여 이 낭비되는 시간을 되찾는 것이 이번 챕터의 목표입니다.
두 가지 방식의 메일박스 통신 비교 (첫 번째 & 두 번째 사진)
이 두 사진은 스레드끼리 데이터를 주고받을 때, 상황에 따라 어떤 방식을 써야 하는지를 명확히 보여줍니다.
[A] 메인 스레드 간의 통신 (Ping-Pong, Rendezvous, handshake 방식)
생산자와 소비자가 모두 '기다릴 수 있는(Block 가능)' 일반 스레드일 때 사용합니다.
-
Send (초기값 0): 보내는 쪽(Producer)이 받는 쪽(Consumer)에게 "나 데이터 썼어! 가져가!"라고 외치는 신호등입니다.
-
Ack (초기값 0): 받는 쪽(Consumer)이 보내는 쪽(Producer)에게 "응, 나 데이터 확실히 빼갔어! 이제 다음 거 써도 돼!"라고 응답(Acknowledge)하는 신호등입니다.
uint32_t Mail; // Shared data
int32_t Send=0; // Semaphore
int32_t Ack=0; // Semaphore
void SendMail(uint32_t data){
Mail = data; // Write data
OS_Signal(&Send); // Tell consumer data is ready
OS_Wait(&Ack); // Wait until consumer reads it
}
uint32_t RecvMail(void){
uint32_t theData;
OS_Wait(&Send); // Wait for data
theData = Mail; // Read mail
OS_Signal(&Ack); // Tell producer "I got it!"
return theData;
}핵심: Ack 세마포어가 존재합니다. 소비자가 읽을 때까지 생산자도 멈춰서 기다리므로 데이터 유실이 절대 발생하지 않습니다.
[B] 하드웨어 인터럽트(ISR)를 위한 통신
생산자가 마이크나 가속도계 같은 하드웨어 인터럽트(ISR)일 때 사용합니다. (Lab 2에서 우리가 짠 방식입니다!)
uint32_t Lost=0; // Counter for lost data
void SendMail(uint32_t data){
Mail = data;
if(Send){ // If previous mail is unread
Lost++; // Overwrite and increment error counter
} else {
OS_Signal(&Send);
}
}
uint32_t RecvMail(void){
OS_Wait(&Send); // Wait for data
return Mail; // Read and return mail
}핵심: 하드웨어 인터럽트는 OS_Wait으로 무한 대기할 수 없으므로 Ack 세마포어를 아예 없애버렸습니다. 대신 데이터를 덮어쓸 경우 Lost 카운터를 올려 에러를 기록합니다.
2. OS_Suspend의 하드웨어적 원리
void Task0(void){
Count0 = 0;
while(1){
Count0++;
Profile_Toggle0();
OS_Suspend(); // Yield the CPU immediately after finishing the job
}
}
// Task1 and Task2 have the exact same structure.동작 원리: 스레드가 켜지자마자 카운터를 하나 올리고 핀을 토글하는 아주 짧은 작업(약 몇 마이크로초 소요)을 합니다. 그리고 1ms 할당 시간을 멍하니 기다리지 않고, 곧바로 OS_Suspend()를 불러 다음 스레드에게 턴을 넘겨버립니다.
결과: 3개의 스레드가 1ms 주기가 아니라, 거의 빛의 속도(1.3 μs 주기)로 서로 양보하며 돌아가는 엄청난 반응 속도를 보여주게 됩니다.
스레드가 스스로 "나 턴 마칠게, 다음 사람 들어와!"라고 외치는 기능입니다.
-
인터럽트 강제 발생: OS_Suspend 함수는 INTCTRL 레지스터(Register 67)의 26번째 비트(PENDSTSET)에 1을 기록하여(즉, 0x04000000을 입력하여) 하드웨어 타이머가 다 돌지 않았어도 강제로 SysTick 인터럽트를 발생시킵니다.
-
스케줄러 호출: SysTick 인터럽트가 터지면 우리가 짰던 SysTick_Handler가 실행되고, 이는 곧 자연스럽게 다음 스레드로 문맥 전환(Context Switch)이 일어남을 의미합니다.
-
우선순위 주의: 이때 SysTick의 우선순위는 반드시 가장 낮음(Priority 7)으로 설정되어야 다른 중요한 하드웨어 ISR(타이머, 센서 등)의 흐름을 방해하지 않습니다.
기본 OS_Suspend 함수 구현
void OS_Suspend(void){
INTCTRL = 0x04000000; // trigger SysTick, but not reset timer
}설명: CPU의 소중한 시간을 양보하기 위해 소프트웨어적으로 타이머 인터럽트를 강제로 터뜨리는 코드입니다.
0x04000000의 비밀: 이 숫자를 2진수로 바꾸면 26번째 비트가 1입니다. ARM Cortex-M 프로세서의 INTCTRL (Interrupt Control and State, Register 67) 레지스터의 26번째 비트는 PENDSTSET이라는 특별한 스위치입니다. 여기에 1을 쓰면 하드웨어 타이머가 다 안 돌아갔어도 "지금 당장 SysTick_Handler 실행해!"라고 명령을 내리게 됩니다.
완벽해진 OS_Suspend (시간 공평성 해결)
void OS_Suspend(void){
STCURRENT = 0; // reset counter
INTCTRL = 0x04000000; // trigger SysTick
}명: 1번 코드의 치명적인 단점(시간 불공평)을 해결한 최종 완성본입니다.
STCURRENT = 0;이 추가된 이유: 만약 1ms(밀리초) 타이머 중 스레드 A가 0.75ms를 쓰고 OS_Suspend를 불렀다고 가정해 봅시다. 1번 코드처럼 타이머를 초기화하지 않고 다음 스레드 B로 넘어가면, B는 타이머에 남은 자투리 시간인 0.25ms만 쓰고 쫓겨나는 억울한 일이 생깁니다.
그래서 STCURRENT = 0;을 통해 타이머를 강제로 0으로 초기화해 줍니다. 이렇게 하면 다음 스레드는 무조건 온전한 1ms의 Time Slice(할당 시간)를 보장받게 됩니
3. 세마포어 OS_Wait의 극적인 진화
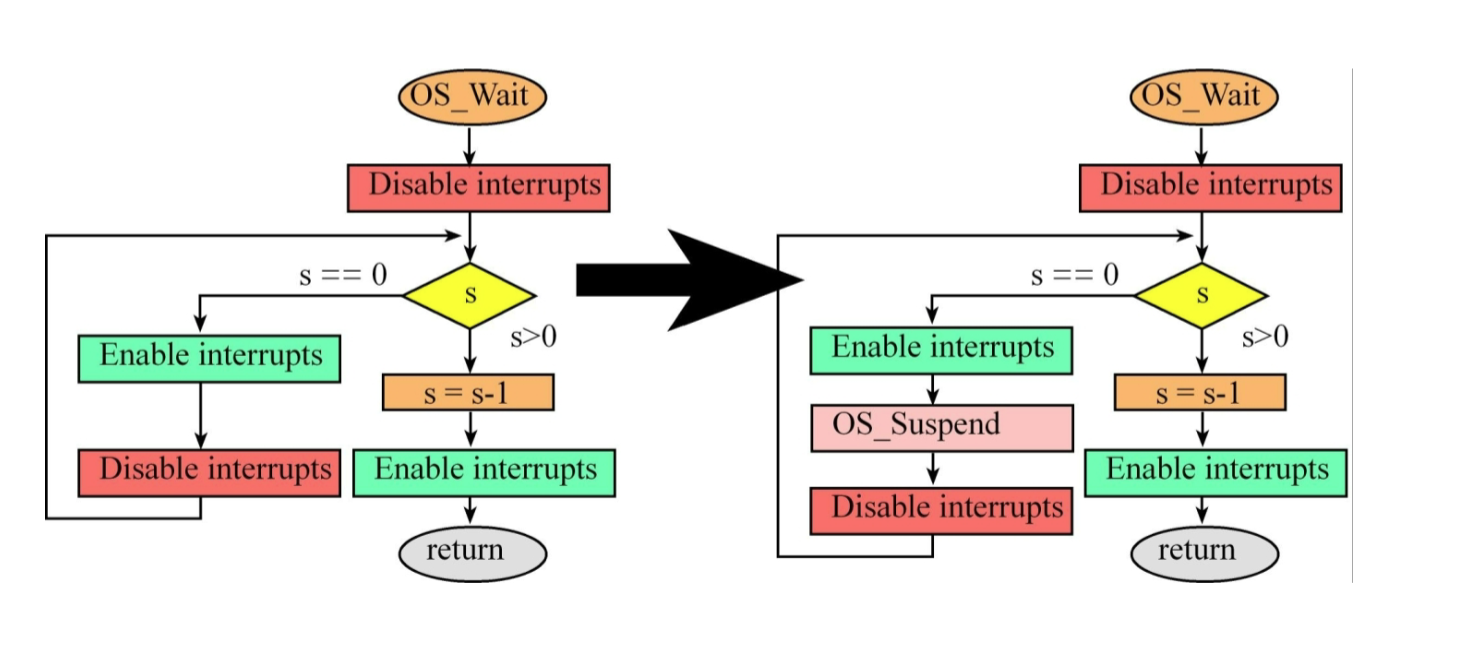
가장 중요한 변화는 세마포어 대기 함수인 OS_Wait의 내부 구조가 바뀌는 것입니다.
과거 (Regular Spinlock):
// wastes time here until the next thread switch
void OS_Wait(int32_t *s){
DisableInterrupts();
while((*s) == 0){
EnableInterrupts();
// CPU가 아무것도 안 하고 허공에 1ms(자신의 턴)를 다 날려버림
DisableInterrupts();
}
(*s) = (*s) - 1;
EnableInterrupts();
}열쇠(s)가 0이면, 아주 잠깐 인터럽트를 열었다가 닫기만 하고 계속 제자리걸음을 했습니다.
현재 (More Efficient):
// more efficient
void OS_Wait(int32_t *s){
DisableInterrupts();
while((*s) == 0){
EnableInterrupts();
OS_Suspend(); // 열쇠가 없네? 내 남은 시간 다음 스레드한테 바로 양보할게!
DisableInterrupts();
}
(*s) = (*s) - 1;
EnableInterrupts();
}열쇠(s)가 0이면, 인터럽트를 열어준 직후 OS_Suspend()를 호출해 버립니다. "어차피 못 들어갈 거, 내 남은 시간 다른 스레드한테 줘버릴게!" 하고 곧바로 스케줄러를 불러버리므로 CPU 낭비가 완벽하게 사라집니다.
+ 알파
"The priority of the SysTick ISR needs to be 7" (SysTick의 우선순위는 반드시 7이어야 한다)
ARM에서 7은 가장 낮은 우선순위를 뜻합니다. 문맥 전환을 하는 SysTick 인터럽트가 마이크, 가속도계 등 아주 예민한 하드웨어 타이머(ISR)의 실행을 방해하거나 끊어먹지 않게 하려고 일부러 가장 낮게 설정하는 것입니다.
"The thread switch time to be about 1 μs... the 1-μs overhead is significant." (문맥 전환 오버헤드)
스레드가 OS_Suspend를 부르면서 초당 엄청난 횟수(약 1.3μs 주기)로 교대를 하게 됩니다. 이때 레지스터를 넣고 빼는 SysTick_Handler의 실행 시간이 약 1μs 정도 걸리는데, 교대 주기가 너무 빠르다 보니 이 1μs의 시간이 시스템 전체 성능에 부담(Overhead)을 줄 만큼 커진다는 의미입니다.
Blocking Semaphore
1. 스핀락을 버리고 '블로킹(Blocking)'을 써야 하는 3가지 이유
극강의 효율성 (Inefficiency 극복): 스핀락은 열쇠를 얻을 때까지 아무 일도 안 하면서 CPU 시간만 낭비합니다. 스레드 개수가 많아질수록 이 낭비되는 시간은 눈덩이처럼 커집니다. 반면, 블로킹 세마포어는 이 버려지는 시간을 완벽하게 회수하여 다른 스레드에게 넘겨줍니다.
공평성 (Fairness & Bounded Waiting): 스핀락은 운이 나쁘면 영원히 열쇠를 못 얻고 굶어 죽을 수 있습니다(Starvation). 하지만 블로킹 방식은 '유한 대기(Bounded Waiting)'를 보장합니다. 즉, 내가 줄을 서면 내 앞에 새치기할 수 있는 스레드의 수가 유한하게 정해져 있어서, 언젠가는 반드시 내 차례가 온다는 것을 보장합니다.
우선순위 스케줄러 (Priority Scheduler) 필수 조건: 스핀락은 스레드에 '우선순위(VIP 등급)'를 매기는 고급 스케줄러에서는 아예 사용할 수가 없기 때문에, 반드시 블로킹 세마포어를 써야만 합니다.
2. TCB(스레드 제어 블록)의 업그레이드: Blocked 필드 추가
스레드를 대기실에 가두기 위해, TCB 구조체에 blocked라는 새로운 명찰(필드)을 하나 추가합니다.
-
Blocked == 0 (Null): 아무것도 이 스레드를 막고 있지 않다는 뜻입니다. 즉, 스케줄러가 차례를 주면 언제든 달릴 수 있는 준비 상태(Ready/Running)입니다.
-
Blocked == 특정 세마포어 주소: 현재 이 스레드가 열쇠(자원)를 얻지 못해 특정 세마포어 앞에서 잠들어 있음(Blocked)을 의미합니다. 스케줄러는 이 명찰을 확인하면 이 스레드를 실행하지 않고 그냥 건너뜁니다.
-
(참고: 하나의 스레드는 동시에 두 개의 세마포어에서 대기할 수 없습니다. 하나에서 막히면 그 자리에 그대로 멈춰버리기 때문입니다.)
3. 구조도 완벽 해부 (스레드의 상태)
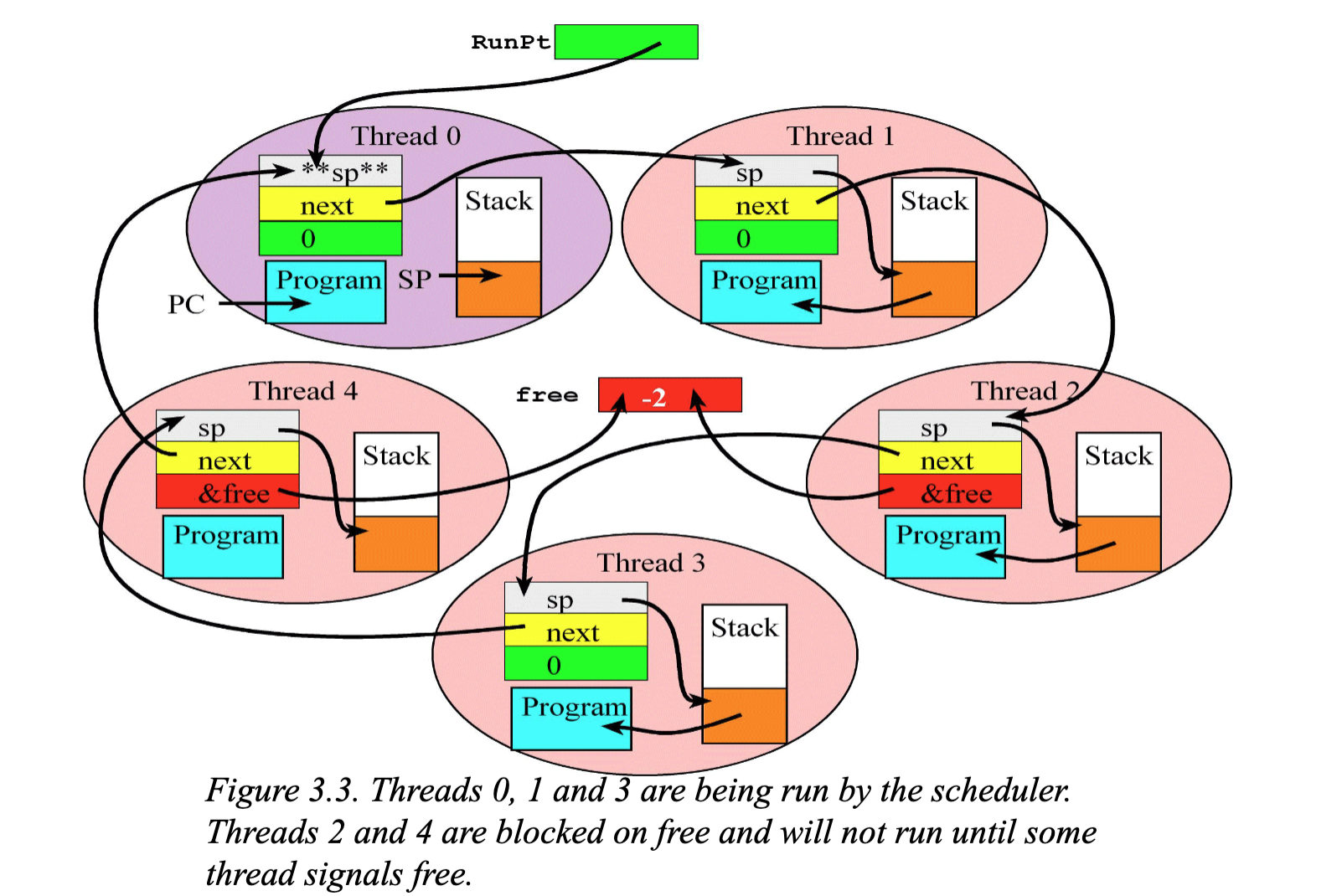
-
원형 연결 리스트: 5개의 스레드(0~4)가 next 포인터를 통해 빙글빙글 꼬리를 물고 이어져 있습니다.
-
실행 중인 스레드 (0, 1, 3): 이 세 개의 스레드는 녹색 필드(Blocked)가 0입니다. 아무런 제약이 없으므로 스케줄러가 차례대로 실행시켜 줍니다. 현재 RunPt는 Thread 0을 가리키고 있네요.
-
잠들어 있는 스레드 (2, 4): 이 두 스레드의 붉은색 필드(Blocked)를 보면 &free라는 세마포어의 주소가 적혀있습니다. 즉, 이 둘은 free라는 자원이 나오기 전까지는 스케줄러가 차례를 줘도 실행되지 못하고 무시당합니다. (이때 free 세마포어의 값은 -2로, 2명이 대기 중임을 나타냅니다.)
4. 어떻게 공평하게 깨울 것인가? (Bounded Waiting 구현법)
OS_Signal이 불려서 누군가를 깨워야 할 때, 가장 오래 기다린 사람부터 공평하게 깨우는 두 가지 방법입니다.
-
큐(Queue) 사용: 세마포어마다 대기줄(Linked List)을 따로 만들어서, 늦게 온 스레드는 줄 맨 뒤에 세우고, 깨울 때는 맨 앞에 있는 스레드부터 깨웁니다(FIFO 방식).
-
타임스탬프(Time-stamp) 사용: TCB에 스레드가 잠든 시간을 기록해 둡니다. 누군가를 깨워야 할 때 원형 연결 리스트 전체를 싹 뒤져서, 가장 과거의 시간을 가진(가장 오래 기다린) 스레드를 찾아내서 깨웁니다.
