어제까지 DAU 20인 서비스에 갑자기 10만명이 몰릴 때 프론트 개발자로 살아남는 법 with NextJS

글을 쓰기에 앞서 이 글은 기술적인 관점보단 개인의 회고에 가깝습니다. 또, 거의 전날 까지 기능 개발만 하던 프론트엔드 관점, 특히 Vercel을 사용하는 Next.js 개발자의 관점으로 작성함을 밝힙니다. DevOps 적인 관점이나 백엔드적 관점 등은 거의 들어있지 않다는 점을 밝힙니다.
사건의 발단
우리 회사는 Web3 서비스 회사이다.
(작성일 기준 당장 어제 비트코인이 9천만원을 찍었다.)
인류의 미래자산 비트코인을 외치며 떠났던 Web3 유저들이 돌아오는 상황에서 우리 회사는 Web3 씬의 구글, Consensys 재단의 Linea 체인과 이벤트를 열게 되었다.
이벤트는 몇 주 동안 진행되었고, 각 서비스에서 준비한 이벤트가 순차적으로 열리는 구성이었다. 다행스럽게도 1주차 프로젝트나 유입률을 확인하여 미리 대비가 가능했었다는 점이 고무적이었다.
문제는 Week1에서 추산해봤을 때, 동접자수 최대 3만 명, WAU 15 만 명 정도가 나왔다는 점이었다. 처음 다뤄보는 높은 트래픽에 기대반 설렘 반으로 약속의 11시를 맞이한 것이다.
문제 발생과 원인 추적 그리고 대응
Q. 서버 or 호스트가 터졌는가?

Web2의 인프라 준비는 완벽했다.
회사의 경험 많은 DevOps 엔지니어 분이 스케일 조정을 잘 해주셔서, CDN이나 인스턴스 관리가 꽤 잘되어있어서 터지는 일은 다행히도 일어나지 않았다. NextJS로 빌딩된 프로젝트는 일반적으로 Vercel을 거쳐 배포가 되는데, 이미 Pro 플랜을 사용하고 있었기에 호스트에서 문제는 일어나지 않았다.
다만,Web3의 인프라는 미흡했다.
말 그대로 아비규환이 따로 없었다.
Dapp을 운영하는 회사의 장점이자 단점은 바로 실시간 유저의 반응을 팔로업할 수 있다는 점이다. 1시부터 디스코드에서 유저의 반응과 모니터링 툴, Google Analytics, Vercel Monitoring, 사내 운영툴을 켜두고 반응을 모니터링했다.
준비해둔 RPC의 limit을 단 1시간만에 넘겨버렸고, 정확히 2시부터 모든 요청에 429 throttling이 걸리기 시작했다.
혹시나 모를 사태에 대비하여 안쓰길 바랬던, 프론트 단의 Kill Switch를 바로 머지하여 기능을 막았다.
회사의 코드를 그대로 복사할 순 없지만, Kill Switch 로직을 단순하게 재현해보자면 아래와 같다.
프론트의 Kill Switch
enum buildTier = {
off = 0;
local = 1;
development = 2;
production = 3;
};
const featureSwitch = () => {
// env를 가져와도 되고 리터럴로 off를 넣어주자.
const env = process.env.NEXT_PUBLIC_ENV;
const tier = buildTier[env];
const result = {
auth: false,
feature1: false,
feature2: false,
//...
}
/** Switch Case
* Switch로 구분했지만, Number 부등호 비교로 하는게 더 유용하다.
* 각 티어값의 크기를 대조하여 들어갈 기능을 여기서 정의해주면 좋다.
*/
switch(tier) {
case buildTier.off:
// 모든 feature를 off;
case buildTier.local:
// 모든 feature를 on;
case buildTier.development:
// dev preview 환경에서 기능 on;
case buildTier.production:
// production 환경에서 기능;
}
Object.freeze(result);
return result;
}이제 이 featureSwitch 객체를 API 요청을 보내는 레이어에서 불러와 확인을 해 대응한다. (react-query의 enabled prop에 묶어두면 굉장히 유용하다.)
.env 를 환경 별로 여러 개로 분리해두고 사용하면 각 빌드티어별로 대응이 쉽게 가능한데, killSwitch로 사용하려면, 지역변수 env를 선언할 때 리터럴로 off를 넣어주면 간단하게 구현이 가능하다.
우선 급한 대로 public 한 RPC도 사용하고 의사결정이 굉장히 급박하게 이뤄졌었다. Hot Fix 대응에는 항상 손에 땀이 나는데, git branch를 따로 파서 대응하는게 아니라 preview 브랜치에 바로 push를 하고 production 머지로 바로바로 쳐냈다.
지금 확인해보니 production 머지를 포함해서 당일 대응에만 프론트 파트에서 합쳐서 26개의 push를 했었다.
결국 다음날 7시까지 꼴딱 밤을 새우고, 안정화된 걸 확인했다.
후속 대처와 그 성과
next/image는 돈이 듭니다. 알고 계셨나요?
원래 우리 서비스의 경우, 최근 몇 달 동안 기능 개발에 주력해왔기 때문에 이번 사태 전날의 DAU는 20명, MAU로 따져봐도 많아봐야 약 3천 명정도가 사용하는 작은 서비스였다.
이벤트 첫 날 우리 서비스는 기쁘게도(?) 유래없는 기록적인 성장을 이뤘다.
- 신규 가입자가
2,000%늘었다. - 동시 접속자(30분 이내)가
최대 5,000 명까지 찍혔다. - DAU가 GA 기준으로
5 만명이 찍혔다.
우리 개발자들은 비용문제가 걱정이 되어 안정화된 이후로는 쓰고 있던 인프라를 점검했었다.
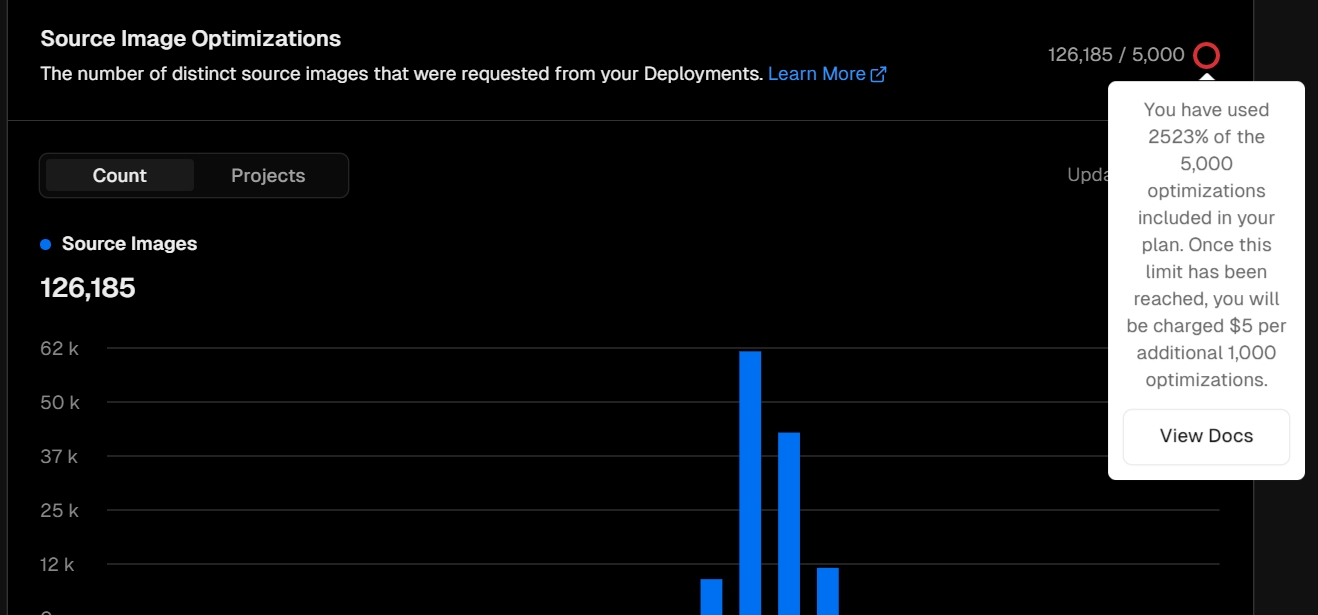
Vercel에서 권장하는 next/image를 사용한 image optimization은 프레임워크 상의 API를 사용하기에, 비용이 든다는 사실을 알고 있었는가? (부끄럽지만 나는 몰랐었다...)
기본적으로 Pro plan을 사용하면 cache된 이미지의 max_age까지를 1로 잡아서 집계되는데 5,000 건까지 무료 이다. 이미지에서 보이지만, 현재는 약 120,000 건으로 overused가 집계되는데, 5,000 건 이상부터 1,000건 단위로 5$가 부과되기 때문에 지금 기준으로, 600$가 부과된다.
프론트파트에서 언젠가부터 기본 <img /> 태그 대신 <Image /> 태그를 주로 사용했기 때문에 비용 절감차원에서 리팩토링 작업을 논의했다. 로고나 용량이 작은 이미지들 처리, SVG 이미지들은 최적화를 지양하는 걸로 정책을 바꾸고, 당장 사용자 유입이 많은 이벤트 페이지나 랜딩페이지, 로그인 페이지에 들어가는 리소스들을 처리했다.
비슷한 맥락으로 BandWidth도 1TB까지 무료이지만, 이후부터는 100GB당 40$가 부과된다. 알아두면 좋다.
svgr/webpack 설정
lighthouse 스코어를 중요 지표로 고려하진 않지만, 이미지를 많이 사용하는 웹사이트에서는 최적화가 중요하다. Hero 이미지에 해당하는 이미지들은 선명한 화질에, 용량이 적어야한다. 마찬가지 맥락으로 작은 아이콘이나 로고, indicator로 사용되는 이미지 에셋은 SVG로 빼주는 게 좋다.
NextJS 코드 포맷에 따라 /public 경로 하위에 보통 에셋을 모아두게 되어 svgr/webpack 설정을 해두고도 잘 사용하지 않았는데, 비용절감 측면에서 향 후 적극 도입하기로 결정했다.
/* package.json */
yarn add -D svgr/webpack
npm i svgr/webpack --dev// next.config.js
/** @type {import('next').NextConfig} */
const nextConfig = {
//..
webpack: (config, { isServer }) => {
const fileLoaderRule = config.module.rules.find((rule) =>
rule.test?.test?.('.svg'),
);
config.module.rules.push(
{
...fileLoaderRule,
test: /\.svg$/i,
resourceQuery: /url/, // *.svg?url
},
{
test: /\.svg$/i,
issuer: /\.[jt]sx?$/,
resourceQuery: { not: /url/ }, // exclude if *.svg?url
use: ['@svgr/webpack'],
},
);
return config;
},
}svgr/webpack을 사용하면 import와 동시에 /src 하위의 SVG 파일을 ReactElement로써 불러오는게 가능하다.
next/image로 인한 최적화 비용까지 극한으로 아끼겠다는 마인드로, svg 파일을 리액트 컴포넌트로 사용하는 것도 비용 절감의 방법 중 하나라고 생각한다.
PS. Vercel과의 meet
트래픽이 몰림을 대비할 수 있는 비용적인 상담을 위해 Vercel 측에 메일을 넣었더니 바로 미팅이 잡혔다. 외국 회사와 주도적인 미팅은 처음이라 꽤 설렌다.
미팅 후 혹시 색다른 내용이 있다면 수정 반영하여 업데이트 해두도록 하겠다.
