
⚠️ 해당 포스팅은 인프런 공룡책 강의를 듣고 개인적으로 정리하는 글입니다. 정확하지 않은 정보가 있을 수 있으니 주의를 요합니다.
Section 09
Chapter 8 Deadlocks
System Model

-
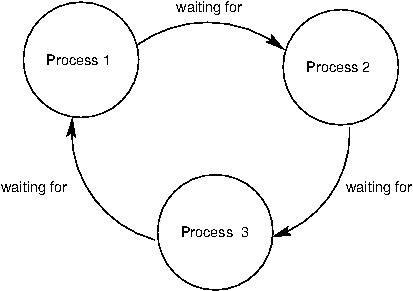
데드락(Deadlock)은 모든 프로세스들이 다른 프로세스의 이벤트를 대기하고 있을 때를 일컫는다.
-
즉,
waiting상태에 있는 스레드가 리소스를 요청했을 때, 리소스가 다른waiting상태의 스레드에 의해 점유되어 있어 다시는 자신의 상태를 바꾸지 못하는 경우를 의미한다.
다른 프로세스가 종료되는 것을 무한정 대기하는 상태
프로세스 집합에 있는 모든 프로세스가, 집합 내에 한 프로세스의 이벤트를 기다리고 있는 경우 -
한정된 리소스로 구성된 시스템을 여러 스레드로 공유해야 하는 상황을 생각해보자.
: 리소스 타입은 여러 개의 동일한 인스턴스 타입으로 구성되어 있다.
: (e.g., CPU cycles, files, and I/O devices(such as printers, drive, etc.) -
한 스레드(혹은 프로세스)가 어떤 리소스의 한 인스턴스를 요청할 때, 동일 리소스의 인스턴스를 할당하여 요청을 충족한다.
-
리소스의 타입이 중요하고, 안의 인스턴스의 개수는 중요하지 않다.
🥲 이 부분을 이해하는데 굉장히 애먹었는데, 맞는 이해인지는 모르겠지만 일단 적는다.
프린터를 리소스라고 하면, 프린터 내의 인스턴스는 복사, 출력등이 있을 것이다. 이 프린터에 프로세스가 접근하면, 프린터 내의 인스턴스 중 하나를 할당하여 프로세스의 요청을 처리하는 것이다.
- 스레드가 리소스를 실행할 때 과정은 아래와 같다.
: Request(요청) - Use(사용) - Release(해방)
: 사용 상황일 때 스레드는 여러 리소스를 사용할 수 있다.
Deadlock Characterization
- 데드락 발생에는 네 가지 조건이 있고, 이 중 하나라도 충족하지 않으면 데드락은 발생하지 않는다.
- Mutal Exclusion (상호 배제)
-> 어떤 리소스에 접근할 때 순간적으로 하나의 프로세스만 접근할 수 있음. - Hold and Wait (점유 및 대기)
-> 프로세스는 적어도 하나의 리소스를 점유하고 있고, 다른 리소스의 추가 획득을 대기하고 있음.
->프로세스가 리소스를 점유하고 있지 않으면, 애초에 데드락이 일어나지 않음. - No preemption (선점 불가)
-> 리소스는 선점될 수 없음.
->선점이 되어버리면 프로세스가 실행을 종료하니 데드락이 일어나지 않음. - Circular Wait (순환 대기)
-> 프로세스가 순환적으로 서로를 기다리고 있음.
Resource-Allocation Graph(RAP)
- 데드락을 쉽게 이해하기 위한 방향성 그래프이다.
- 각 정점을
V라고 칭하며,V에는 두 가지 타입이 있다.
:T: 스레드 집합
:R: 리소스 집합 - 각 간선은
E라고 칭하며, 역시 두 가지 타입이 있다.
: T -> R (요청 선), T에서 R로 리소스를 요청한다.
: R -> T (할당 선), R은 T에 할당되어 있다.
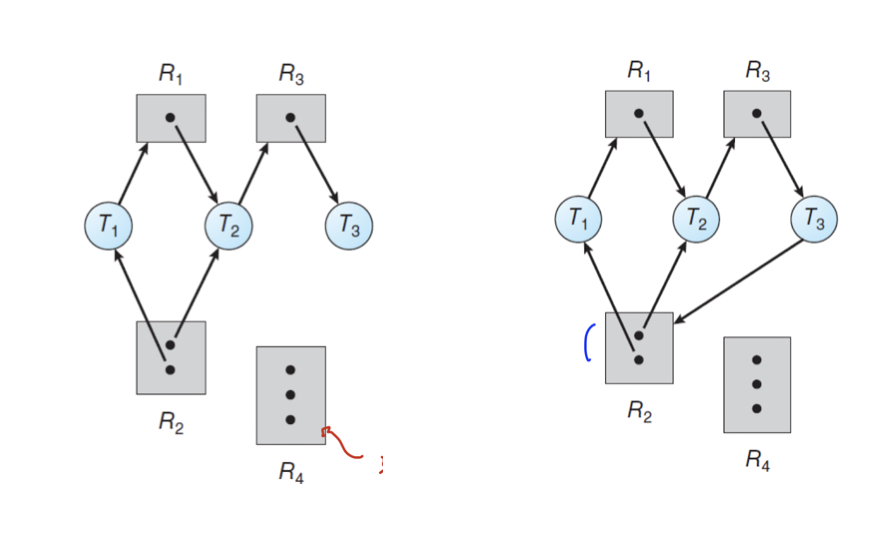
- 왼쪽 그림은 순환 대기, 즉 데드락이 일어나지 않은 상황이다.
- 그러나, 오른쪽 그림을 보면 T3가 R2에게 리소스를 요청하면서 데드락이 발생했다.
- 위의 상황은 사이클을 그리고 있는데, 똑같이 데드락일까?
- R2의 인스턴스가 2개임을 주목해서 보자.
-> T4가 작업을 완료하고 리소스를 놓아주면 T3가 R2에 접근할 수 있으므로 데드락 상황이 아니다.
- 정리해보면, RAP에서 사이클을 그리지 않으면 데드락은 절대 발생하지 않는다.
- 그러나, 사이클이 발생한다고 해서 데드락이 무조건 발생하는 것은 아니다.
- 데드락과 관련된 문제에 대해 세 가지 대응 방법이 존재한다.
-
문제 발생을 무시한다.
: 발생하지 않을 것이라고 가정한다.(🙏 기도한다.) -
데드락을 방지 혹은 회피하기 위한 프로토콜을 사용한다.
: 프로토콜을 이용하여 어떤 상황에서도 데드락에 빠지지 않게 설정하는 것이다.
: 데드락 완전 방지, 데드락 회피 등의 방법이 있다. -
시스템이 데드락 상황에 빠진 것을 확인했을 때 회복한다.
Deadlock Prevention
- 데드락을 완전히 방지하는 방법으로, 위에서 이야기 했던 데드락 발생의 네 가지 조건 중 하나를 완전히 해결해버리는 방법이다.
-
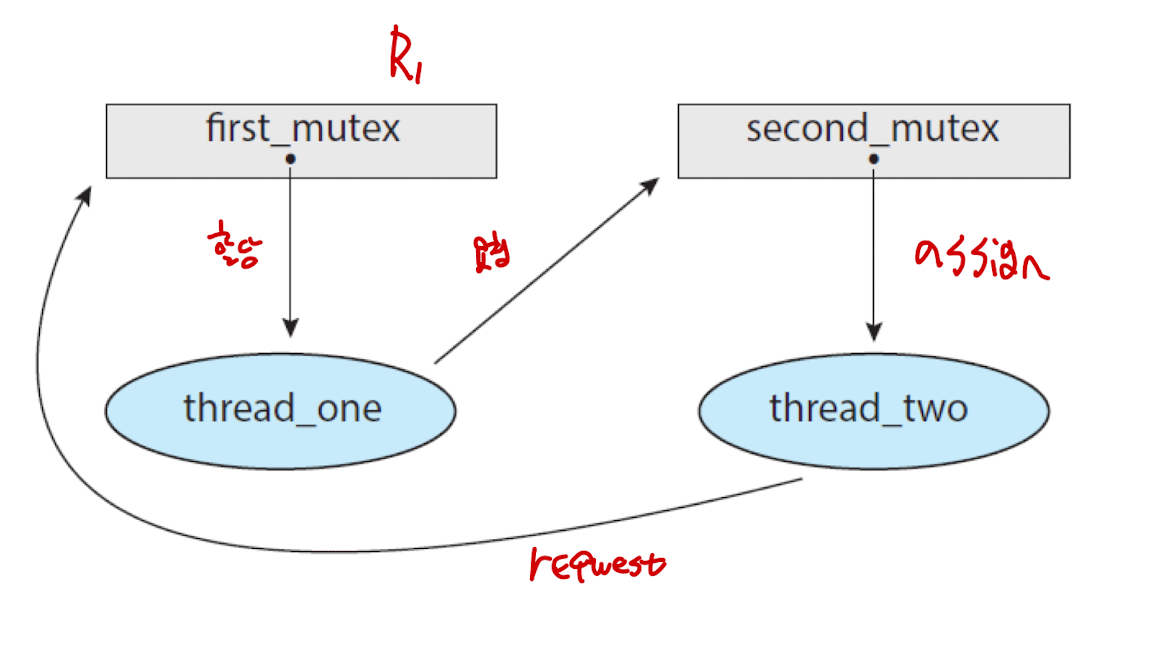
Mutual Exclusion
: 리소스 접근 시 여러 프로세스가 접근하게 해버리는 것이다.
:mutex락을 여러 프로세스가 공유하면 대참사가 날 것이므로, 본질적으로 불가능한 방법이다. -
Hold and Wait
: 프로세스가 리소스를 점유하고 있지 못하게 하는 방법이다.
: 프로세스가 리소스를 요청할 때, 가지고 있는 리소스를 모두 내려놓고 리소스를 요청한다.
: 이 후 획득하면 가지고 있던 리소스를 다시 요청한다.
: 딱 봐도 실용적이지 않다. -
No premmption
: 다른 프로세스가 리소스를 점유하고 있을 때, 이를 선점하여 실행하는 방법이다.
: 선점당한 프로세스는 어떤 작업을 하든 일단waiting상태로 돌입한다.
: 다시 프로세스를 실행하려면 이전 리소스와 새 리소스를 되찾아야만 다시 시작할 수 있다.
: 이 역시 실용적이지 않은 방법이다. -
Circular Wait
: 그나마 실용적인 방법으로, 리소스에 순서를 부여하는 방법이다.
: 각 프로세스가 순서대로 리소스를 요청하게끔 요구한다.
: 우선순위를 부여하는 것과 마찬가지가 되어 기아 상태가 발생할 가능성이 높다.

: 위의 사진을 보면 알겠지만 데드락을 완벽하게 방지하는 것도 아니다. -
결론 : 모두 실용적인 방법이 아니다.
Deadlock Avoidance
- 데드락 방지를 사용하면 디바이스 사용률이 낮아지고, 시스템의 처리량이 감소할 위험이 높다.
- 즉, 멀티 스레딩으로 얻은 장점이 사라진다.
- 이 단점을 피하기 위해 데드락 회피 방법을 사용한다.
- 프로세스의 리소스 요청을 받을 때, 시스템은 발생 가능한 데드락이 있는지 먼저 확인한다.
- 그 상황에서 데드락이 발생하지 않으면 리소스 요청을 허용하고, 데드락이 발생하면 요청을 허용하지 않는다.
- 이를 위해서는 몇 가지 선행 지식이 필요하다.
: 최대 얼마의 리소스가 필요한지?
: 사용 가능하거나 할당된 리소스의 수는 몇 개인지?
: 프로세스는 최대 얼마의 리소스를 요구하는지?
Safe State
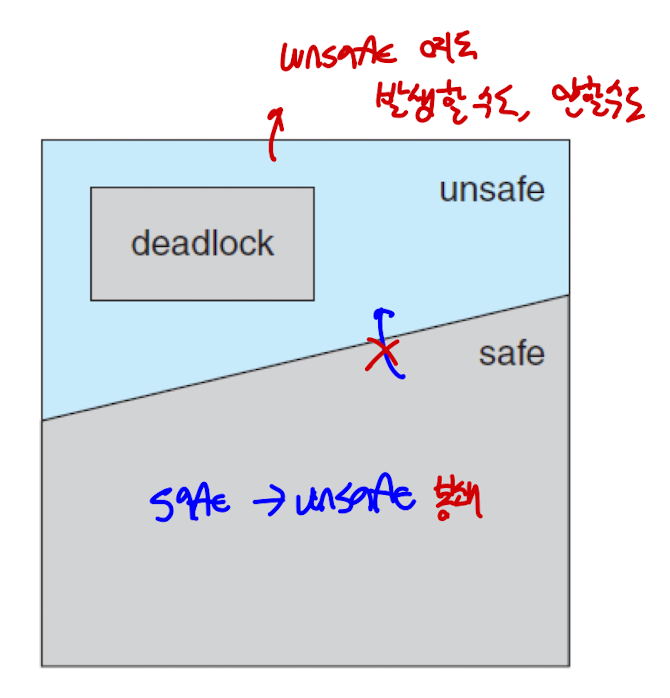
- 특정 순서대로 스레드에 리소스를 할당하면, 리소스도 최대한 활용할 수 있고 데드락도 발생하지 않는 상태를 의미한다.
- 해당 순서를 안전 배열(safe sequence)이라고 한다.
- 데드락을 회피하기 위해서는 알고리즘을 이용하여 안전하지 않은 상태에서 안전한 상태로 이동할 수 없게 설정해야 한다.
- 또한, 안전한 상태의 스레드는 계속해서 안전한 상태로 머물러야 한다.
Revisit the RAG
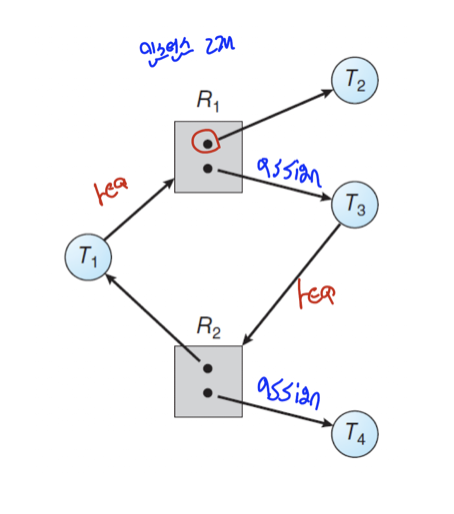
- 데드락을 회피하기 위한 방법 중 하나로, 각 리소스에 하나의 인스턴스만 존재할 때 사용 가능한 방법이다.
- 위에서 이야기했던 RAG를 이용한 방법으로, 새로운 간선을 그릴 때 실선이 아닌 점선으로 그려본다.
- 이 점선을 클레임 엣지(claim edge)라고 부르며 이는 스레드가 나중에 리소스를 요청할 수 있음을 의미한다.
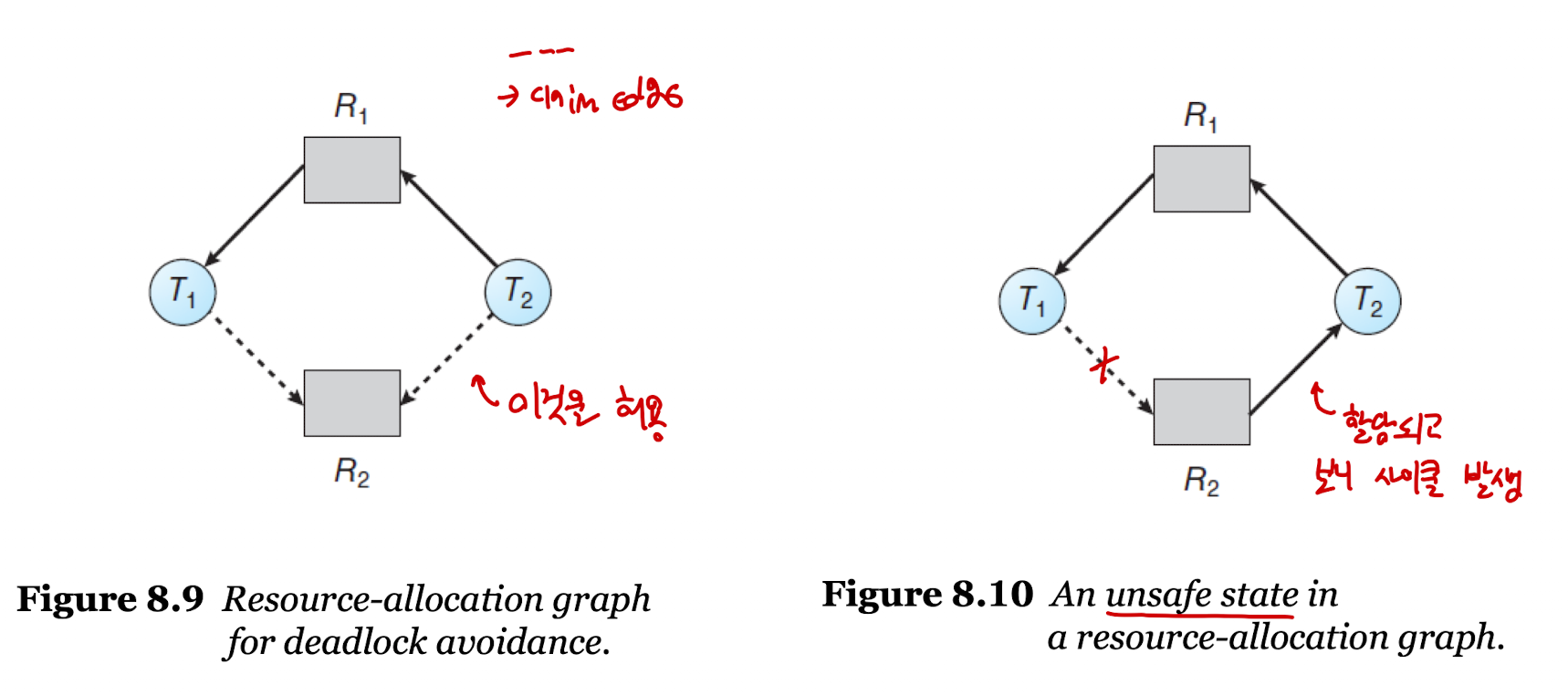
- 이 점선을 이용하여 선을 그렸을 때 사이클이 일어나지 않는지 확인한다.
: 사이클이 그려지지 않으면 안전 상태로 판단되어 스레드의 요청을 즉시 허용한다.
: 사이클이 그려지면 안전하지 않은 상태로 판단되어 스레드의 요청을 거절한다.
Banker's Algorithm
- RAG는 리소스에 여러 인스턴스가 있을 때는 사용할 수 없는 방법이다.
- 은행원 알고리즘이 여러 인스턴스가 있을 때 데드락 회피를 위한 방법으로 적합하다.
- 그러나, RAG에 비해 복잡하고 효율이 떨어지는 면이 있다.
- 리소스의 최대 개수를 할당해도 안전한 상태가 유지되는지 확인한다.
- 변수 설정
:n: 시스템에 있는 스레드의 수
:m: 시스템에 있는 리소스의 수
:Available: 사용 가능한 리소스의 인스턴스 수vector
->avaliable[1] = 5 ->: 1번 리소스의 인스턴스는 5개
:Max: 각 스레드가 요청할 인스턴스의 최대 수matrix
->Max[3][5] = 5 -> 3번 스레드는 5번 리소스의 인스턴스를 최대 5개 요청 가능
:Allocation: 각 스레드에 할당된 리소스의 수matrix
->Allocation[1][3] = 3 -> 1번 스레드가 6번 리소스의 인스턴스를 3개 할당 받았음
:Need: 앞으로 요청할 리소스의 수matrix
->Max[3][5] - Allcation[1][3] = Need[2][2]
:Request: 스레드가 요청한 리소스의 수matrix
->Request[4][6] = 5 -> 4번 스레드가 6번 리소스의 인스턴스 5개를 요청함
Safety Algorithm
Work,Finish벡터를 아래와 같이 초기화한다.
:Work=Available,Finish[i] = false- 아래의 두 조건을 만족하는 인덱스를 찾는다.
:Finish[i] == false,Need[i] <= Work
: 만족하는게 없다면 4번으로 간다. - 조건을 만족한다면 아래를 실행한다.
:Work=Work+Allocation[i]
:Finish[i]=true
: 다시 2번으로 돌아가 끝날 때까지 반복한다. - 만약
Finish[i]가 모두true라면, 안전한 상태라는 의미이다.

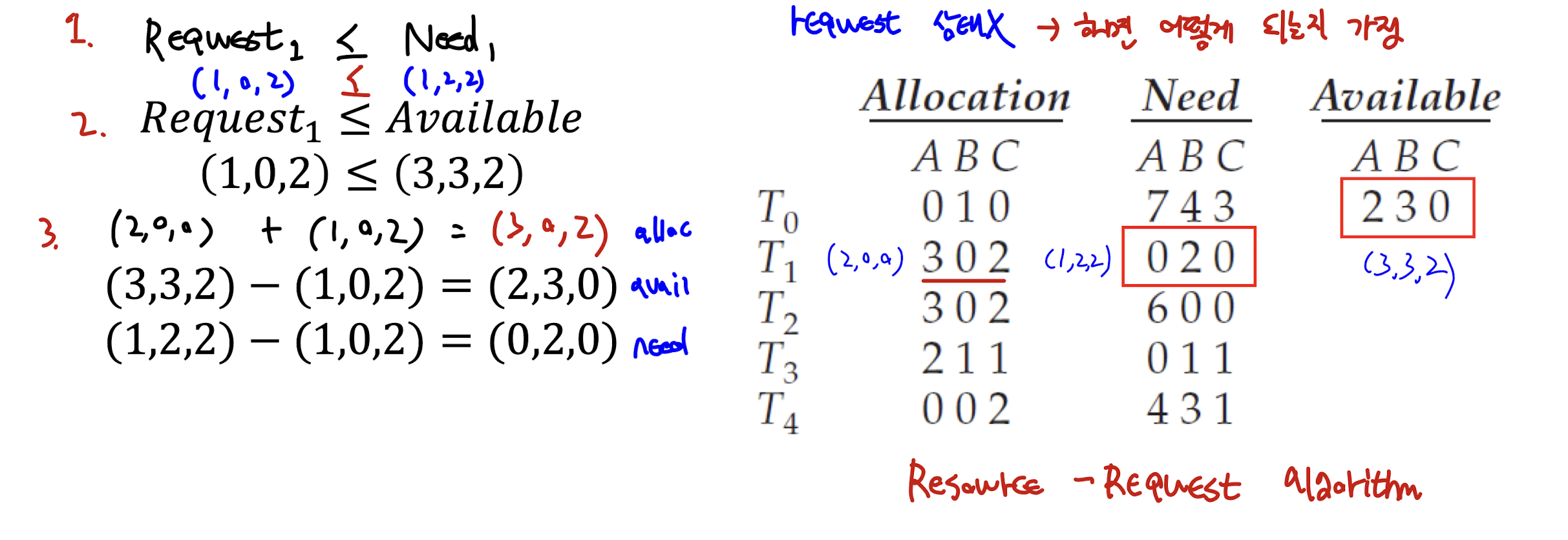
- 이 상태에서, T[1]이 A 인스턴스 1개와 C 인스턴스 2개를 요청한다.
- 이 때 리소스 - 요청 알고리즘을 사용한다.
Resource - Request Algorithm
Request[i] <= Need[i]이면 2번으로 간다.
: 반대의 경우 최초 등록한Max보다 더 많은 양의 리소스를 요청했다는 것을 의미한다.Request[i] <= Available[i]이면 3번으로 간다.
: 반대의 경우 할당 가능한 인스턴스의 양보다 요청 양이 더 많다는 것을 의미한다.- 요청을 받아주며 아래의 식을 적용한다.
: Allocation[i] = Allocation[i] + Request[i];
: Available = Available - Request[i];
: Need[i] = Need[i] - Request[i]; - 이 후 다시 위의 안전 알고리즘을 적용하여 안전한 상태라면 리소스를 완전히 할당한다.
Deadlock Detection
- 기본적으로 은행원 알고리즘은 시스템에 부담이 가는 방법이므로 아주 중요한 경우에만 사용하는 경우가 많다.
- 그렇다고 시스템에서 데드락을 방지하거나 회피하지 않는다면, 데드락은 매번 실행될 것이다.
- 이런 환경에서는 데드락이 일어났는지 확인하기 위한 방법을 사용한다.
- 즉, 데드락을 허용하고, 데드락이 일어나는지 감시하고, 데드락에 빠지면 그 때 복구한다는 뜻이다.
- 리소스에 인스턴스가 1개 있는 경우에는, 위의 RAG를 변형한 wait-for graph를 사용한다.
- 주기적으로 알고리즘을 실행하여 사이클이 있는지 확인한다.
- 있으면 당연히 데드락이 발생하고 있다는 의미이다.
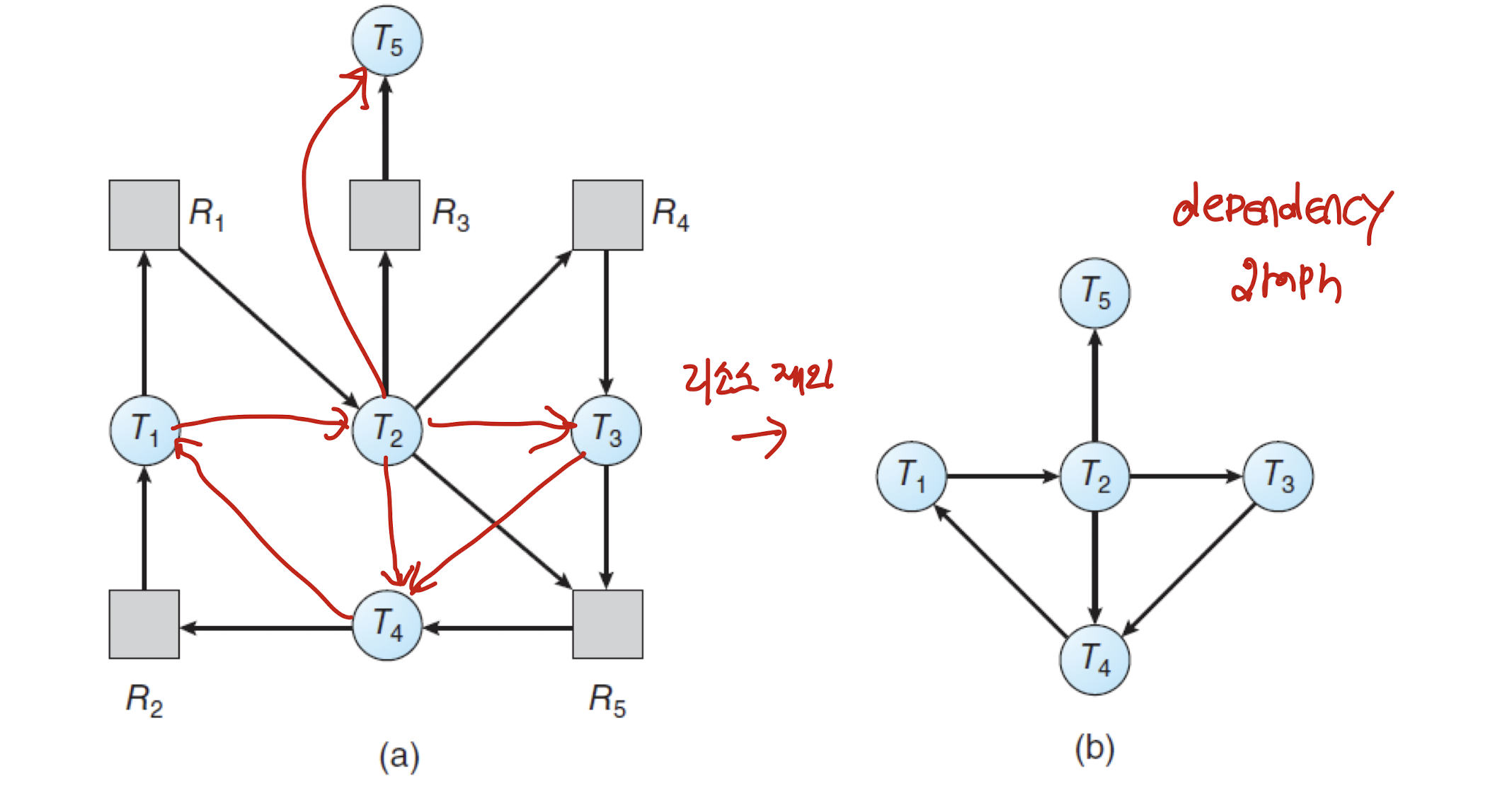
- 기존의 RAG와 차이점은 그래프에서 리소스를 제외하는 것이다.
- 그렇다면, 리소스에 인스턴스가 여러 개 있는 경우엔 어떤 방식을 사용할까?
- 똑같이 위의 은행원 알고리즘을 변형하여 데드락을 발견한다.
Work=Available로 초기화하고,Allocation[i]가 0이면Finish[i]를true로 설정한다.
(스레드가 리소스를 점유하고 있지 않다는 뜻이므로 체크하는 것이 무의미하다. 즉, 프리패스 🏎)- 아래의 두 조건을 만족하는 스레드를 찾는다.
:Finish[i] == false,Request[i] <= Work
: 마찬가지로 조건에 만족하는 스레드가 없다면 4번으로 간다. - 아래의 두 연산을 실행한다.
:Work = Work + Allocation[i],Finish[i] == true Finish[i] == false이면 해당 스레드는 데드락이 발생한 상태임을 의미한다.
Recovery from Deadlock
- 탐지 알고리즘을 통해 데드락이 있다는 것을 확인했을 때 데드락이 일어났음을 단순히 알리는 경우도 있고, 중요한 시스템일 경우 데드락을 복구하는 방법이 있다.
- 데드락을 복구하는 방법은 여러가지가 있다.
- Process and Thread Termination
: 데드락에 걸린 모든 프로세스를 종료하는 방법
: 데드락 사이클에 있는 프로세스를 한번에 하나씩 종료하는 방법 - Resource Preemption
: Selecting a victim : 비용이 낮은 프로세스, 즉 희생자를 선점하여 요청이 들어온 프로세스에게 넘겨준다.
: Rollback : 프로세스를 안전한 상태로 롤백한다.
: Starvation : 같은 프로세스가 계속해서 희생자가 되면 기아 상태가 일어날 수 있으므로 제한 숫자를 둔다.
- 그렇다면, 탐지 알고리즘은 얼마나 자주 돌려야할까?
- 데드락이 일어날 가능성이 높다면, 당연히 데드락 탐지 알고리즘을 자주 돌려야 할 것이다.
- 데드락이 일어났을 때 사이클에 있을만한 스레드의 수가 많다면, 탐지 알고리즘을 자주 돌려야 할 필요가 있다.
- 데드락 탐지 알고리즘은 시스템 성능에 영향을 미칠 수 있어 자주 돌리는 것이 좋은 것은 아니다.
- 그러나, 탐지 주기가 너무 길면 데드락 사이클이 많아져 어디서 데드락이 일어났는지 확인하기 어려울 수 있다.
- 개발자의 판단으로 적절한 탐지 주기를 선택해야 한다.
