
Spring
체크예외와 인터페이스
이전까지 학습했던것 처럼 서비스 계층은 가급적 특정 구현 기술에 의존하지 않고, 순수하게 유지하는것이 좋다. 다만 이를 위해서는 예외에 대한 의존도 해결해야한다. 물론 그 방법은 리포지토리에서 체크예외를 런타임예외로 변환하여 던져주면 된다.
다만, 리포지토리 자체는 특정 구현에 의존하기 때문에 리포지토리도 추상화를 통해서 제공해야한다.
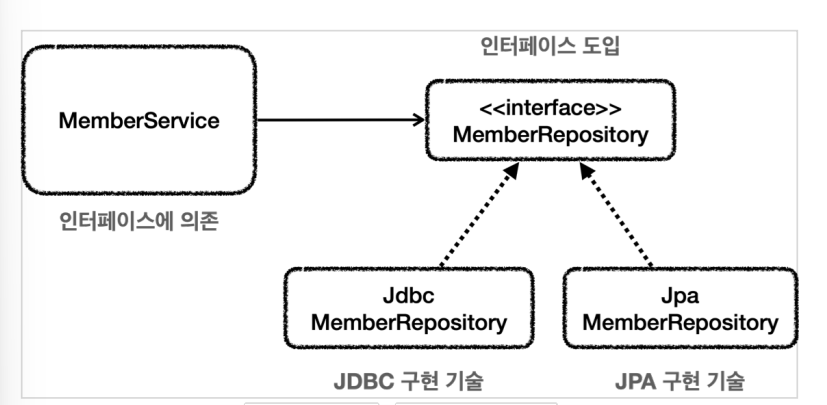
- 위 사진처럼 구현 기술을 변경하고자 한다면 DI를 이용해서 MemberService 코드의 변경 없이 구현 기술을 변경할 수 있다.
즉, 서비스 계층에서 순수한 자바 코드를 제공하기 위해서는 다음 2가지가 필수적? 이다.
- 리포지토리의 추상화
- 리포지토리에서의 예외 변환(체크예외 -> 언체크 예외)
1,2번을 모두 포함한 예시 코드를 보면 아래와 같다.
// 리포지토리 인터페이스 public interface MemberRepository { Member save(Member member); Member findById(String memberId); void update(String memberId, int money); void delete(String memberId); }
// 리포지토리 구현체 public class MemberRepositoryV4_1 implements MemberRepository { private final DataSource dataSource; public MemberRepositoryV4_1(DataSource dataSource) { this.dataSource = dataSource; } @Override public Member save(Member member) { String sql = "insert into member(member_id, money) values(?, ?)"; Connection con = null; PreparedStatement pstmt = null; try { con = getConnection(); pstmt = con.prepareStatement(sql); pstmt.setString(1, member.getMemberId()); pstmt.setInt(2, member.getMoney()); pstmt.executeUpdate(); return member; } catch (SQLException e) { throw new MyDbException(e); } finally { close(con, pstmt, null); } }// 사용자 정의 런타임 예외 public class MyDbException extends RuntimeException { public MyDbException() { } public MyDbException(String message) { super(message); } public MyDbException(String message, Throwable cause) { super(message, cause); } public MyDbException(Throwable cause) { super(cause); } }
위 코드를 보면 SQLException이라는 체크 예외를 MyDbException이라는 런타임예외로 변환해서 던지고 있다.
따라서, 이제 리포지토리를 사용하는 서비스에서는 구현체가 아닌 인터페이스에 의존하고 특정 기술에 대한 의존도 사라진다.
다만 위 코드에도 문제가 존재한다.
리포지토리에서 넘어오는 특정한 예외의 경우 복구를 시도할 수도 있다. 그런데 위 코드는 항상 MyDbException이라는 예외만 넘어오기 떄문에 예외를 구분할 수 없는 단점이 있다. 만약 특정 상황에서는 예외를 잡아서 복구하고 싶으면 예외를 어떻게 구분해서 처리해야할까?
데이터 접근 예외
데이터베이스 오류에 따라서 특정 예외를 복수 하고 싶을 수 있다.
데이터베이스는 각 데이터베이스에 따라서 오류 코드를 반환한다.
이 오류는 코드를 받은 JDBC 드라이버는 SQLException을 던진다.
그리고 SQLException에는 데이터베이스가 제공하는 errorCode라는것이 들어 있다.
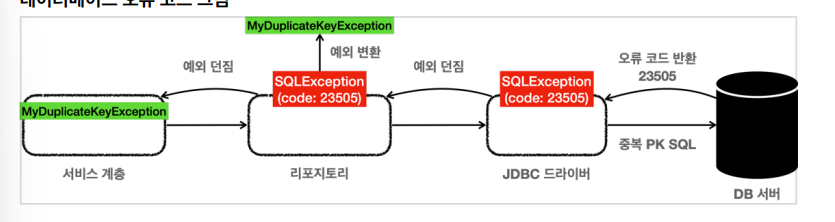
물론 이 오류 코드는 데이터베이스마다 모두 다르다.
예시로 H2 데이터베이스의 키 중복 오류 코드는 아래와 같이 체크가 가능하다.
e.getErrorCode() == 23505따라서 SQLException 내부에 들어 있는 errorCode를 활용하면 데이터베이스에 어떤 문제가 발생했는지 확인할 수 있다.
실제 리포지토리 구현체는 아래와 같이 구현될 수 있다.
// 리포지토리 코드 @RequiredArgsConstructor static class Repository { private final DataSource dataSource; public Member save(Member member) { String sql = "insert into member(member_id, money) values(?, ?)"; Connection con = null; PreparedStatement pstmt = null; try { con = dataSource.getConnection(); pstmt = con.prepareStatement(sql); pstmt.setString(1, member.getMemberId()); pstmt.setInt(2, member.getMoney()); pstmt.executeUpdate(); return member; } catch (SQLException e) { //h2 db if (e.getErrorCode() == 23505) { throw new MyDuplicateKeyException(e); } throw new MyDbException(e); } finally { closeStatement(pstmt); closeConnection(con); } } }
// 서비스 계층 코드 @Slf4j @RequiredArgsConstructor static class Service { private final Repository repository; public void create(String memberId) { try { repository.save(new Member(memberId, 0)); log.info("saveId={}", memberId); } catch (MyDuplicateKeyException e) { log.info("키 중복, 복구 시도"); String retryId = generateNewId(memberId); log.info("retryId={}", retryId); repository.save(new Member(retryId, 0)); } catch (MyDbException e) { log.info("데이터 접근 계층 예외", e); throw e; } } private String generateNewId(String memberId) { return memberId + new Random().nextInt(10000); } }
위 코드 처럼 서비스 계층에서는 예외 복구를 위해서 리포지토리 계층에서 올라온 예외인 키 중복 오류를 확인할 수 있어야 한다. 그래야 오류에 맞는 복구 작업을 진행할 수 있기 때문이다.
하지만, SQLException을 던지면 의존성을 갖게 되기 때문에 사용자 정의 예외를 만들어 변환해서 서비스 계층으로 던져야한다.
하지만, 위 코드에도 문제는 여전히 남아 있다.
-
SQL ErrorCode는 각각의 데이터 베이스마다 다르다. 결과적으로 데이터베이스가 변경될때 마다 ErrorCode도 모두 변경해야한다.
-
데이터베이스가 전달하는 오류는 키 중복 뿐만 아니라 락이 걸린 경우, SQL 문법에 오류가 있는 경우 등등 수 십 수백가지 오류 코드가 있다. 이 모든 상황에 맞는 예외를 다 만들어야 한다면? 그리고 데이터베이스마다 오류 코드가 다르기 때문에 그에 맞춰 대응해줘야한다면?
그건 지옥이다..
스프링 예외 추상화
위에서 말한 문제를 해결하기 위해 데이터 접근과 관련된 예외를 추상해서 스프링은 제공한다.
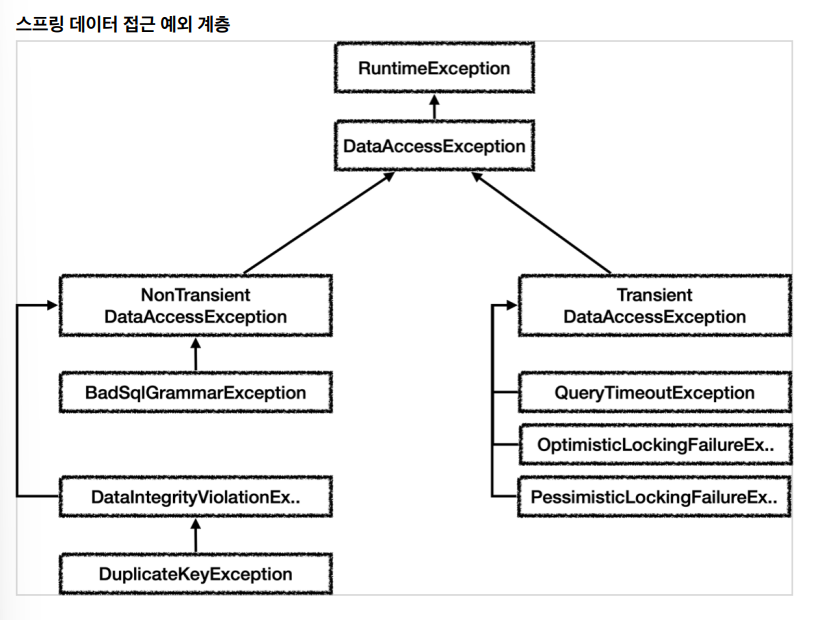
- 스프링은 데이터 접근 계층에 대한 수십 가지 예외를 정리해서 일관된 예외 계층을 제공한다. 이 예외는 당연히 런타임 예외이므로 개발자가 사용자 정의 예외를 만들지 않아도 된다.
- 각각의 예외는 특정 기술에 종속적이지 않는다. 따라서, 서비스 계층에서도 스프링이 제공하는 예외를 사용하면 된다.
- JDBC나 JPA를 사용할 때 발생하는 예외를 스프링이 제공하는 예외로 변환해주는 역할도 스프링이 제공한다.
- 예외의 최고 상위는 org.springframework.dao.DataAccessException이다. 위 그림에서 보듯이 런타임 예외를 상속 받았기 때문에 스프링이 제공하는 데이터 접근 계층의 모든 예외는 런타임 예외이다.
- DataAccessException은 크게 2가지로 구분하는데, NonTrasient 예외와 Transient예외이다.
- Transient는 일시적이라는 뜻인데, Transient 하위 예외는 동일한 SQL을 다시 시도했을때 성공할 가능성이 있다.- NonTransient는 일시적이지 않다는 뜻이다. 같은 SQL을 그대로 반복해서 실행하면 실패한다.
스프링이 제공하는 예외 변환기
스프링은 데이터베이스에서 발생하는 오류 코드를 스프링이 정의한 예외로 자동으로 변환해주는 변환기를 제공한다.
앞선 코드들은 SQL ErrorCode를 직접 확인했는데 이렇게 직접 예외를 확인하고 하나하나 스프링이 만들어준 예외로 변환하는것은 지옥이다.
그래서 스프링은 예외 변환기를 제공한다.
@Test
void exceptionTranslator() {
String sql = "select bad grammar";
try {
Connection con = dataSource.getConnection();
PreparedStatement stmt = con.prepareStatement(sql);
stmt.executeQuery();
} catch (SQLException e) {
assertThat(e.getErrorCode()).isEqualTo(42122);
//org.springframework.jdbc.support.sql-error-codes.xml
SQLExceptionTranslator exTranslator = new
SQLErrorCodeSQLExceptionTranslator(dataSource);
//org.springframework.jdbc.BadSqlGrammarException
DataAccessException resultEx = exTranslator.translate("select", sql,
e);
log.info("resultEx", resultEx);
assertThat(resultEx.getClass()).isEqualTo(BadSqlGrammarException.class);
}
}위 코드에서 보듯이 스프링이 제공하는 SQL 예외 변환기는 아래와 같이 사용하면 된다.
SQLExceptionTranslator exTranslator = new
SQLErrorCodeSQLExceptionTranslator(dataSource);
DataAccessException resultEx = exTranslator.translate("select", sql, e)- translate() 메서드의 첫번째 파라미터는 읽을 수 잇는 설명을 의미하고, 두번째는 실행한 SQL, 마지막은 발생된 SQLException을 전달하면 된다.
각각의 DB마다 SQL ErrorCode는 다르다. 그런데 스프링은 어떻게 각각의 DB가 제공하는 SQL ErrorCode까지 고려해서 예외를 변환할까?
비밀의 파일에 있다.
sql-error-codes.xml
SQLExceptionTranslator exTranslator = new SQLErrorCodeSQLExceptionTranslator(dataSource); DataAccessException resultEx = exTranslator.translate("select", sql, e)
- org.springframework.jdbc.support.sql-error-codes.xml
- 스프링 SQL 예외 변환기는 SQL Error Code를 이 파일에 대입해서 어떤 스프링 데이터 접근 예외로 전환해야할지 찾아낸다.
정리
- 스프링은 데이터 접근 꼐층에 대한 일관된 예외 추상화를 제공한다.
- 스프링은 예외 변환기를 통해서 SQLException의 ErrorCode에 맞는 적절한 스프링 데이터 접근 예외로 변환해준다.
- 만약, 서비스, 컨트롤러 계층에서 예외 처리가 필요하면 특정 기술에 종속적인 SQLException같은 예외를 직접 사용하는것이 아니라 스프링이 제공하는 데이터 접근 예외를 사용하면 된다.
JDBC 반복 문제 해결- jdbcTemplate
서비스 계층을 순수한 자바 코드로 유지하기 위해서 많은 spring 기술을 사용했다.
마지막으로 리포지토리에서 JDBC를 사용하기 떄문에 발생하는 반복 문제만 해결하면 된다.
JDBC 반복 문제
- 커넥션 조회, 커넥션 동기화
- PreparedStatement 생성 및 파라미터 바인딩
- 쿼리 실행
- 결과 바인딩
- 예외 발생시 스프링 예외 변환기 실행
- 리소스 종료
리포지토리의 각각의 메서드를 살펴보면 상당히 많은 부분이 반복된다. 이런 반복을 효과적으로 처리하는 방법이 바로 템플릿 콜백 패턴이다.
스프링은 JDBC 반복 문제를 해결하기 위해 JdbcTemplate이라는 템플릿을 제공한다.
예시코드
public class MemberRepositoryV5 implements MemberRepository { private final JdbcTemplate template; public MemberRepositoryV5(DataSource dataSource) { template = new JdbcTemplate(dataSource); } @Override public Member save(Member member) { String sql = "insert into member(member_id, money) values(?, ?)"; template.update(sql, member.getMemberId(), member.getMoney()); return member; } @Override public Member findById(String memberId) { String sql = "select * from member where member_id = ?"; return template.queryForObject(sql, memberRowMapper(), memberId); } @Override public void update(String memberId, int money) { String sql = "update member set money=? where member_id=?"; template.update(sql, money, memberId); } @Override public void delete(String memberId) { String sql = "delete from member where member_id=?"; template.update(sql, memberId); } private RowMapper<Member> memberRowMapper() { return (rs, rowNum) -> { Member member = new Member(); member.setMemberId(rs.getString("member_id")); member.setMoney(rs.getInt("money")); return member; }; } }
JdbcTemplate는 JDBC로 개발할때 발생하는 반복을 대부분 해결해준다. 그 뿐만 아니라 지금까지 학습했던 트랜잭션을 위한 커넥션 동기화는 물론이고 예외 발생시 스프링 예외 변환기도 자동으로 실행해준다.
참고
해당 포스팅은 아래의 강의를 공부하여 정리한 내용입니다.
김영한님의 SpringDB1-체크예외와 인터페이스
jdbcTemplate에서 특정 객체로 반환하기 위해서는 맵핑 정보를 넣어줘야함.
그게 RowMapper임
자세한 내용은 db2 강의에서 설명함.
