Database Connection Pool
🙋♀️ JDBC?
기존 JDBC는 아래와 같은 과정을 거칩니다.
- DB벤더에 맞는 드라이버 로드
- DB서버의 IP,ID PW등을 DriverManager 클래스의 getConnection 메소드를 사용하여 Connection 객체 생성
- Connection으로 부터 PreparedStatement 객체를 받음
- executeQuery를 수행하고 ResultSet객체를 받아 데이터를 처리
- 사용했던 ResultSet, PreparedStatement, Connection을 close
이러한 일련의 과정을 거쳐 Java 애플리케이션과 Database가 연동되어 원하는 데이터를 처리할 수 있게 도와줍니다. 이 과정중에서 가장 오래걸리는 부분을 예상한다면 2번 과정의 Connection 객체를 얻는 부분이 될것입니다. 이유는 DB서버와 애플리케이션 사이의 통신이기에 같은 장비에 둘다 존재하더라도 오랜 시간이 걸리기 때문입니다. 만일, 사용자가 급증한다면 서버 환경에선 반복적으로 Connection 객체를 얻기 위해 많은 시간을 소모할 것입니다.
만약에 이러한 환경에서 미리 필요한 양만큼의 Connection 객체를 미리 얻어놓는다면 Connection 객체를 생성하는 부분에서 발생하는 대기 시간을 줄이고 네트워크의 부담을 줄일 수 있을 것입니다. 이때 등장한 개념이 DB Connecion Pool 입니다.
🙄 DB Connection Pool?
.png)
사용자의 요청에 따라 무수한 Connection을 생성하다보면 서버에 과부하가 걸리게 된다. 이러한 상황을 방지하기 위해 미리 설정해놓은 일정수의 Connection을 만들어 놓고 이것을 Connection Pool에 보관해두었다가 요청이 발생하면 제공을 해주고 Connection의 사용이 끝난다면 다시 Connection Pool에 반환하여 보관하는 기술을 DB Connection Pool 이라고 합니다.
💡 장점
- DB 접속 설정 객체를 미리 만들어 연결하여 메모리 상에 등록해 놓기 때문에 클라이언트가 빠르게 DB에 접속 가능
- DB Connection 수를 제한 할 수 있어서 과도한 접속으로 인한 서버 자원 고갈 방지 가능
- DB 접속 모듈을 공통화해 DB서버의 환경이 바뀔 경우 쉬운 유지보수 가능
- 연결이 끝난 Connection을 재사용함으로써 새로 객체를 만드는 비용을 줄일 수 있음.
Datasource와 DB Connection Pool의 차이
DataSource는 JDK 1.4버전부터 생긴 표준이다. DataSource는 Connection Pool로 연결을 관리해야 하고, 트랜잭션 관리도 가능하게 만들어야한다. 그러므로 DataSource가 DB Connection Pool을 포함한다고 생각하면 된다. 여기서 유의할 점은 DB Connection Pool은 Java 표준으로 지정되어 있는 것이 없다는 점이다. 따라서 WAS 벤더에 따라서 사용법이 상이할 수 있다. 그러나 DataSource는 Java 표준이므로 WAS에 상관없이 사용법은 동일하다.
HikariCP란?

HikariCP란 Springboot 2.0부터 default로 설정되어 있는 DB Connection Pool로써 Zero-Overhead가 특징으로 높은 성능을 자랑하는 DB Connection Pool입니다. HikariCP는 미리 정해놓은 만큼의 Connection을 Connection Pool에 담아 놓습니다. 그 후 요청이 들어오면 Thread가 Connection을 요청하고, Hikari는 Connection Pool내에 있는 Connection을 연결해주는 역할을 합니다.
또한, Springboot 환경에서는 아래와 같이 application.properties에서 간단하게 HikariCP의 설정을 할 수 있습니다.
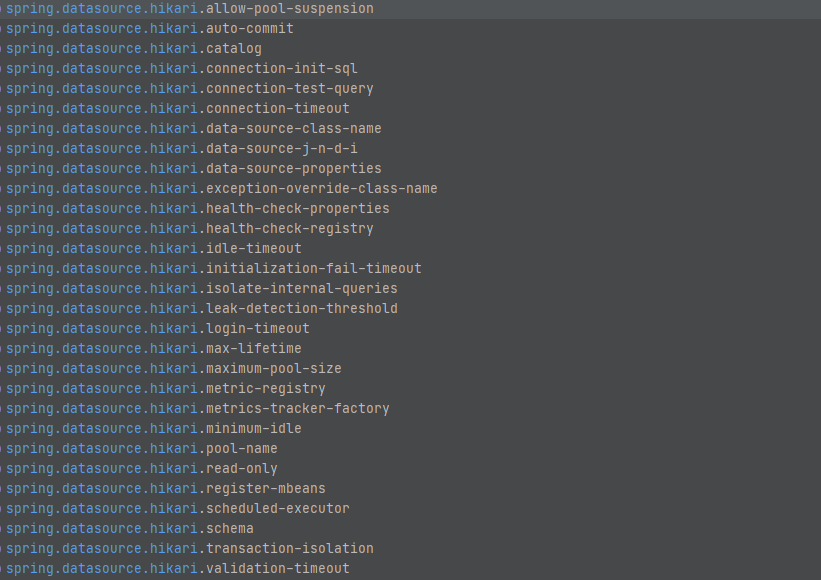
Hikari 뜯어보기
데이터 소스 생성
HikariDataSource ds = new HikariDataSource(config)
-------------------------------------------------------------------
private final HikariPool fastPathPool;
private volatile HikariPool pool;
....
public HikariDataSource(HikariConfig configuration)
{
configuration.validate();
configuration.copyStateTo(this);
LOGGER.info("{} - Starting...", configuration.getPoolName());
pool = fastPathPool = new HikariPool(this);
LOGGER.info("{} - Start completed.", configuration.getPoolName());
this.seal();
}Hikari는 DataSource 객체에서 pool, fastPathPool에 각각 HikariPool을 생성합니다. 여기서 pool이 volatile로 정의된 이유는 여러 Thread에서 해당 pool변수를 참조할 때 값이 달라지면 안되기 떄문입니다. Volatile로 설정하면 해당 변수를 읽고 쓸 떄 메인메모리로 바로 접근합니다.
Hikari Pool이 가지있는 변수
- logger : 로그를 기록하는 Logger 객체
- poolState : Pool의 상태
- aliveBypassWindowMs : Connection이 살아있는지 판단할 때 ByPass할 수 있는 시간(millisecond)
- housekeepingPeriodMs : 배치처럼 작동하는 HouseKeeping이 돌아가는 주기
- poolEntryCreator : Pool에 새로운 Entry를 생성해주는 Creator 객체
- postFillPoolEntryCreator : Pool에 Entry를 채우기 위한 Creator객체
- addConnectionQueue : Connection을 새로 만들기 위한 thread를 잠시 담아 놓는 Queue
- addConnectionExecutor : Thread를 addConnectionQueue에 넣어 놓는 Executor
- closeConnectionExecutor : Connection 종료를 진행하는 Executor
- connectionBag : Connection Entry를 담고 있는 객체
- suspendResumeLock : Pool의 사용을 지속/중지할지 결정하는 변수.
- houseKeepingExecutorService : Pool을 관리하기 위해 필요한 배치작업을 수행하는 객체
- houseKeeperTask : HouseKeepingExecutor가 실행하는 Task
계속............
📝참고
