id를 사용하고 있는 PK 컬럼명?
참고: 엔티티의 식별자는 id 를 사용하고 PK 컬럼명은 member_id 를 사용했다. 엔티티는 타입(여기서는Member )이 있으므로 id 필드만으로 쉽게 구분할 수 있다. 테이블은 타입이 없으므로 구분이 어렵다. 그리고 테이블은 관례상 테이블명 + id 를 많이 사용한다. 참고로 객체에서 id 대신에 memberId 를 사용해도 된다. 중요한 것은 일관성이다.
실무에서 @ManyToMany를 사용하지 말자
참고: 실무에서는 @ManyToMany 를 사용하지 말자 @ManyToMany 는 편리한 것 같지만, 중간 테이블에 컬럼을 추가할 수 없고, 세밀하게 쿼리를 실행하기 어렵기 때문에 실무에서 사용하기에는 한계가 있다. 중간 엔티티를 만들고@ManyToOne , @OneToMany 로 매핑해서 사용하자. 정리하면 대다대 매핑을 일대다, 다대일 매핑으로 풀어내서 사용하자
Fetch전략? 모든 연관관계는 지연로딩으로 설정!
즉시로딩(EAGER)은 예측이 어렵고, 어떤 SQL이 실행될지 추적하기 어렵다. 특히 JPQL을 실행할 때 N+1 문제가 자주 발생한다. 실무에서 모든 연관관계는 지연로딩(LAZY)으로 설정해야 한다. 연관된 엔티티를 함께 DB에서 조회해야 하면, fetch join 또는 엔티티 그래프 기능을 사용한다. @XToOne(OneToOne, ManyToOne) 관계는 기본이 즉시로딩이므로 직접 지연로딩으로 설정해야 한 다. (@OneToMany는 default LAZY;)
컬렉션은 필드에서 바로 초기화 하자!
- null 문제에서 안전하다.
- 하이버네이트는 엔티티를 영속화 할 때, 컬랙션을 감싸서 하이버네이트가 제공하는 내장 컬렉션으로 변경한다. 즉, 영속성컨텍스트에서 문제가 발생할 수 있음 만약 getOrders()처럼 임의의 메서드에서 컬력션을 잘못 생성하면 하이버네이트 내부 메커니즘에 문 제가 발생할 수 있다. 따라서 필드레벨에서 생성하는 것이 가장 안전하고, 코드도 간결하다.
엔티티(필드)→ 테이블(컬럼)
- 카멜 케이스 → 언더스코어(memberPoint→ member_point)
- .(점) → _(언더스코어)
- 대문자 → 소문자
- 논리명 생성 : 명시적으로 컬럼, 테이블명을 직접 적지 않으면 ImplicitNamingStrategy 사용
- 물리명 적용 : 모든 논리명에 적용됨, 실제 테이블에 적용 (username usernm 등으로 전사 표준에 따라 바꿀 수 있음)
케스케이드 옵션

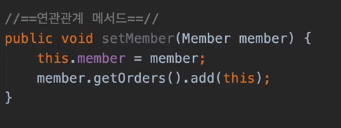
연관관계 편의 메서드
양방향일 경우 set에 편하게 사용!
트랜잭션 관리시 간단한 최적화
아래와 같이 등록이 아닌 읽기 전용 메소드 인경우 readOnly 어노테이션을 통해 엔티티매니저에게 알려주어 쓸때없는 더티체킹을 방지하고 최적화를 할 수 있습니다.

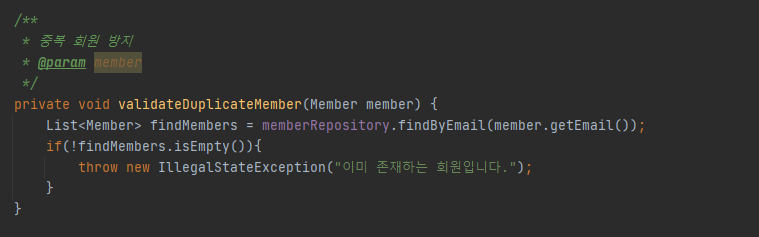
유니크 제약조건
아래의 중복회원 방지와 같은 중복조건을 마련해 두었음에도 여러대의 WAS에서 동시에 메서드를 불르거나 멀티쓰레드 환경에서 아래와 같은 조건을 통과할 수 있습니다.
따라서 DB에서 유니키 제약조건을 따로 걸어두는것이 안전합니다.
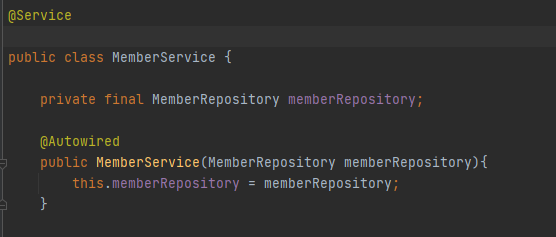
생성자 인잭션
롬복 version
코드 version
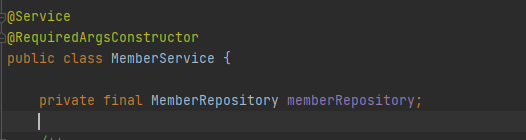
Setter를 지양해야하는 이유?
어떤 상품이 추가되어 전체 카테고리의 양의 추가되거나 줄어들어야 할 경우 외부에서 Setter를 이용해 상품의 quantity를 증가시키는게 아니라 도메인 내부의 비지니스 로직을 통해 필드값을 변경해야한다고 합니다.
엔티티를 직접 노출해야할 때
엔티티는 직접 노출해야하는 일이 없어야 한다. 따라서 Hibernate5Module를 사용하기보다는 DTO로 변환해서 반환하는 것이 더 효율적이다.
만약 엔티티를 직접 노출할 때는 양방향 연관관계가 걸린곳은 꼭 한곳을 @jsonIgnore 처리 해야한다. 만약 그대로 노출하게 된다면 양쪽을 서로 호출하면서 무한 루프가 걸리게 된다.
