금정구 관내 학생끼리 하는 대회를 갔다.
우리학교(대진전자통신고) 8명 지산고 6명이 왔다.
1일차 2일차 나누어서 개발을 하고 발표까지 하는 해카톤 대회였다.
난 한학년 동생과 2인팀이 되었다. 저번에 했던 팀프로젝트에 금정구 민원 분류기를 다시 한번 사용할려고 한다. 하지만 그렇게만 하면 안될것같고 결과물이 만족치 않을것 같아 분류기에 비속어를 쓰면 민원 분류를 해주지 않게 하기위해 공개 API서비스에서 비속어 추출 API를 사용해 민원 내용 안에 비속어가 있고 없고를 알수있게하여 만들어보았다.
- 자료 - 크롤링, 전처리
- ai - ai모델링
- 웹 - streamlit
- 발표
이걸 코치님과 3명에서 하기로 하였다.
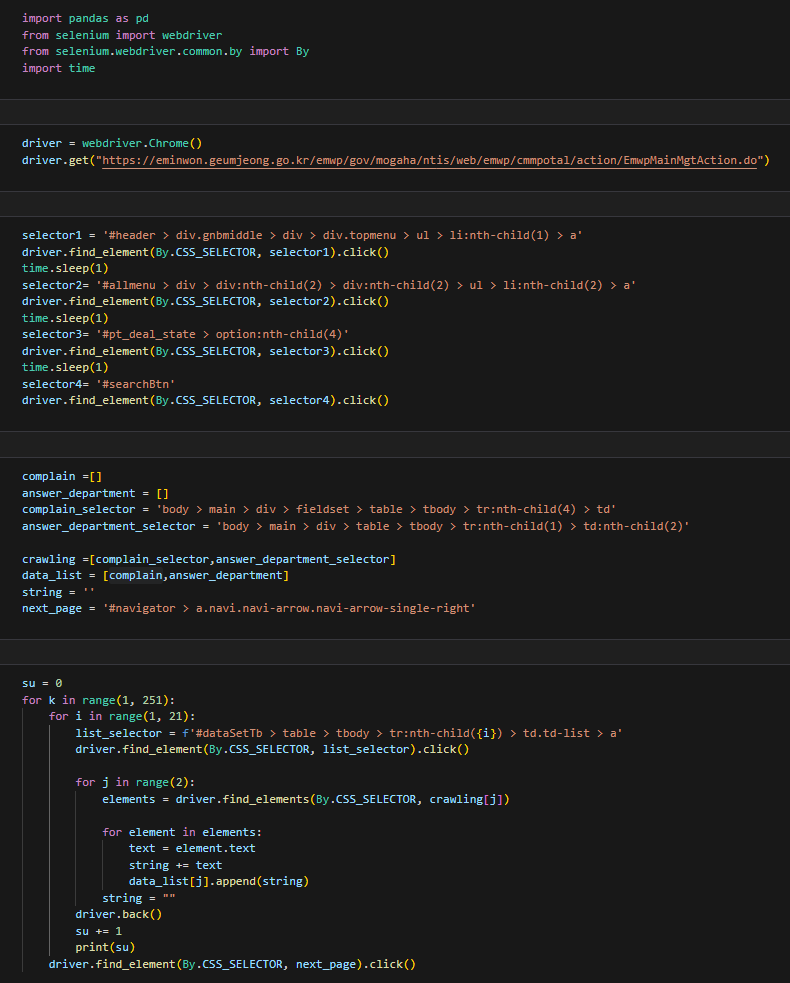
나는 크롤링과 약간의 전처리를 하고
코치님이 내 전처리의 문제점을 조금 고쳐주셨다.
웹은 한학년 동생인 친구가 하다가 많이 막히어 크롤링과 전처리를 끝낸 후
같이 웹을 만들었다.
어려웠던 점
전에 했던 프로젝트라고 쉽게 끝날줄 알았지만 생각보다 막히는게 많았다.
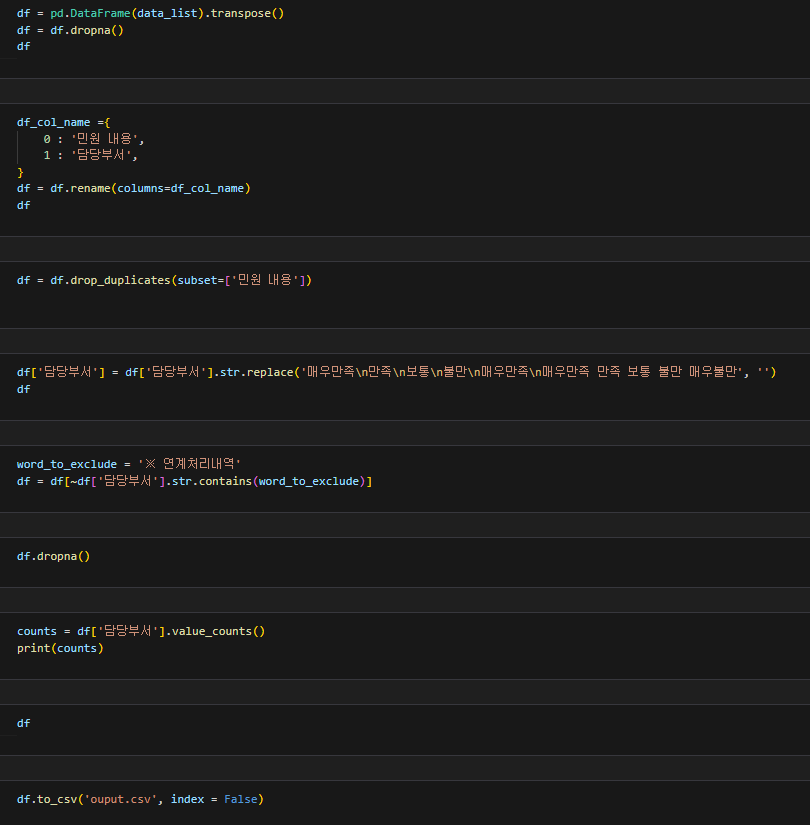
전처리를 할떄 간단한 것들만 지웠지만 아직 나에겐 전처리 실력이 조금 부족해서 코치님이 도와주셨다. 이 부분은 좀더 공부를 해야될거같다.
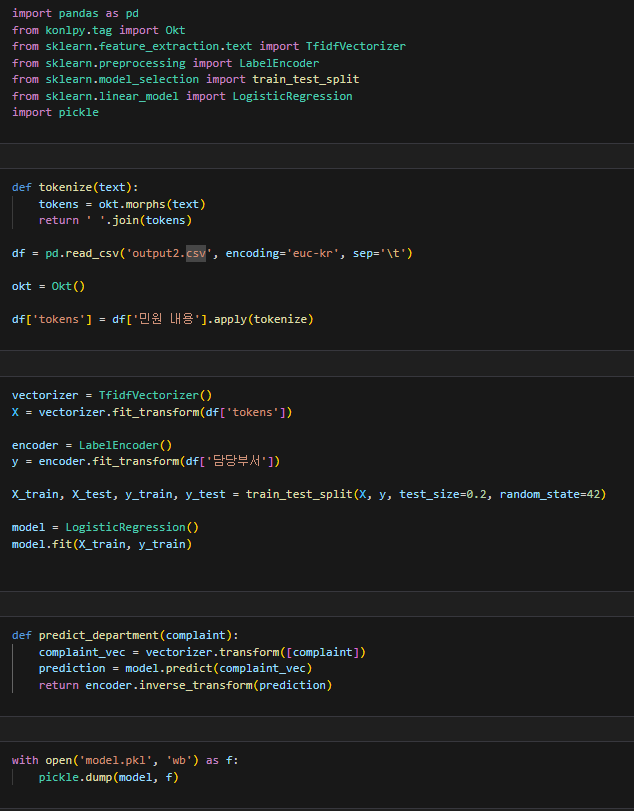
모델링 한 것을 저장하고 streamlit에서 ai를 가져와 사용할려고 하였지만 시간이 너무 들어서 포기하고 있다가 뤼튼(챗봇)을 사용하여 그 부분을 완화 했다. 뤼튼이 짜준 코드를 보면서 공부를 하면 도움이 될거같다.
그리고 api가 뭔지는 알고 있었지만 실전 프로젝트에선 사용해 본적이 없어서 얼탔지만 사용방법을 보고 잘 응용해서 썼던것 같다. 아직 공부할게 많은 것같다.
1일차 결과
시현영상
코드
크롤링-
전처리-
AI모델링-
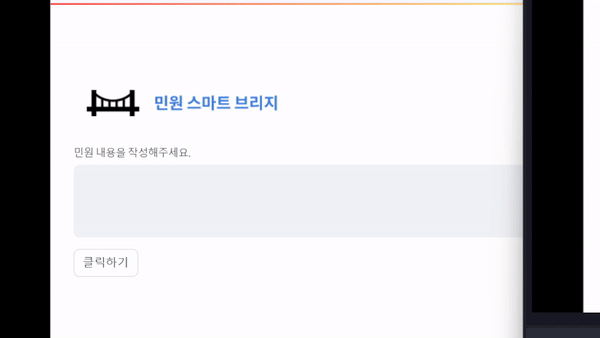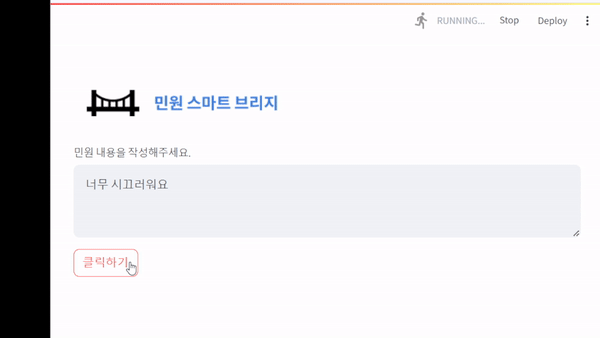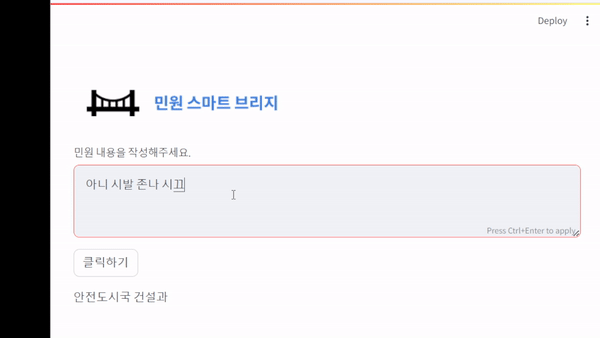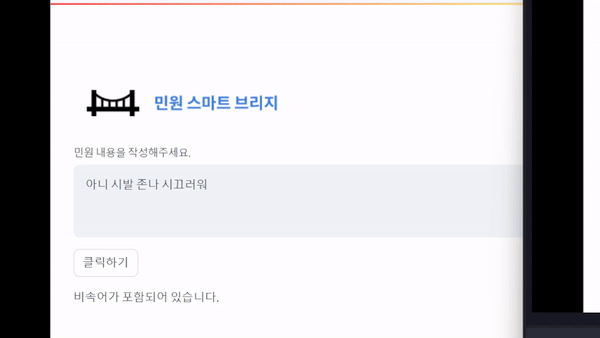
웹-
import streamlit as st
import pandas as pd
from konlpy.tag import Okt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import LabelEncoder
import pickle
import requests
@st.cache_data()
def load_data():
df = pd.read_csv('minwon_1.csv', encoding='euc-kr', sep='\t')
return df
@st.cache_data()
def preprocess_data(df):
okt = Okt()
df['tokens'] = df['민원 내용'].apply(lambda x: ' '.join(okt.morphs(x)))
return df
@st.cache_data()
def load_model():
with open('model\model.pkl', 'rb') as f:
model = pickle.load(f)
return model
def predict_department(complaint, vectorizer, encoder, model):
complaint_vec = vectorizer.transform([complaint])
prediction = model.predict(complaint_vec)
return encoder.inverse_transform(prediction)[0]
def besok(text):
url = 'https://api.matgim.ai/54edkvw2hn/api-keyword-slang'
headers = {
'content-type': 'application/json',
'x-auth-token': 'api-key'
}
data = {
'document': f'{text}'
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
response_data = result.get('result', {}).get('data', [])
return response_data
def main():
st.set_page_config(
page_title="민원 분류기",
page_icon="photo\icon.png",
initial_sidebar_state="expanded"
)
img_url = "photo\banner.png"
st.image(img_url, width=300)
text = st.text_area('민원 내용을 작성해주세요.')
btn = st.button('제출하기')
if btn:
if besok(text):
st.write("비속어가 포함되어 있습니다.")
else:
df = load_data()
df = preprocess_data(df)
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df['tokens'])
encoder = LabelEncoder()
y = encoder.fit_transform(df['담당부서'])
model = load_model()
result = predict_department(text, vectorizer, encoder, model)
st.write(f'{result} 부서에 민원을 제기하십시요.')
if __name__ == "__main__":
main()
