
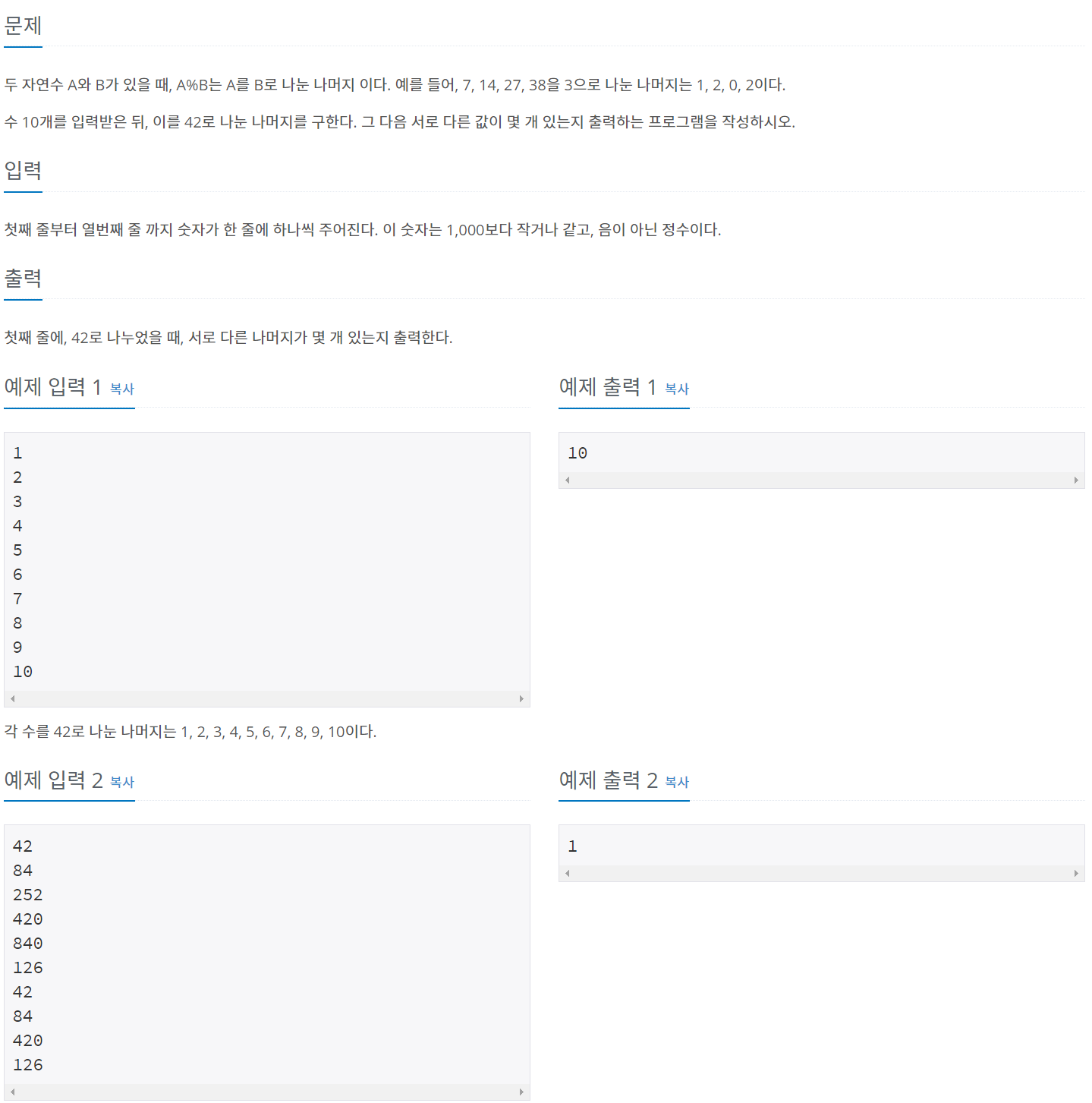
Python 풀이
N = [] #빈 list생성 for _ in range(10): #10개의 숫자를 입력받음 N.append(int(input())%42) N = set(N) #리스트를 set으로 바꿔줌 print(len(N)) #N의 길이 출력
set은 리스트, 딕셔너리, 튜플과 같이 데이터를 담는 컨테이너 중 하나이다. set의 특징은
1. 중복을 허용하지 않는다.
2. 순서가 없다.(unordered collection)
set은 순서가 없기 때문에 인덱싱(indexing)을 할 수가 없다. set은
set = {1, 2, 4, 6, 3}과 같이 선언하는데 dictionary와 비슷하다. dictionary는 인덱싱을 key를 이용하여 하기 때문에 set의 인덱싱을 가진 버전이 dictionary라 볼 수 있다.
아무튼! set은 중복을 허용하지 않기 때문에 나머지가 '서로 다른' 개수를 구하라는 문제에서 나머지를 전부 구해준 후에 중복을 제거해주면 서로 다른 나머지만 남기 때문에 set을 이용하여 풀이하였다.
C++ 풀이
#include <algorithm> #include <vector> #include <iostream> using namespace std; int main() { ios_base::sync_with_stdio(false); cin.tie(NULL); vector<int> arr; //vector arr 선언 int n; for (int i = 0; i < 10; i++) { cin >> n; //10개의 숫자 입력 arr.push_back(n % 42); //입력 후 바로 vector에 42로 나눈 나머지 추가 } sort(arr.begin(), arr.end()); //vector 정렬 arr.erase(unique(arr.begin(), arr.end()),arr.end()); //vector 중복 제거 cout << arr.size(); //vector의 크기 출력 }
C++도 set이 있다. 헤더에 #include <set>을 선언해주고 set<int> s로 set을 만들어준 후 하나씩 추가하면 된다.
이 풀이는 vector의 중복된 요소를 제거하는 방법인데, 중복을 제거하기 전에 먼저 sort로 정렬을 해준다. 그 이유는 아래에서 설명하겠다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
vector<int> v = { 1,5,2,3,3,2,1,5 };
unique(v.begin(), v.end());
for (int i : v) cout << i << '\n';
}
1 1 2 2 3 3 5 5
/*
결과 :
1
5
2
3
2
1
5
5
*/
링크텍스트
위 링크에서 그 이유에 대해 잘 설명이 되어있으니 한번 보시는 걸 추천!

https://oraange.tistory.com/ 여기에도 많이 놀러와 주세요